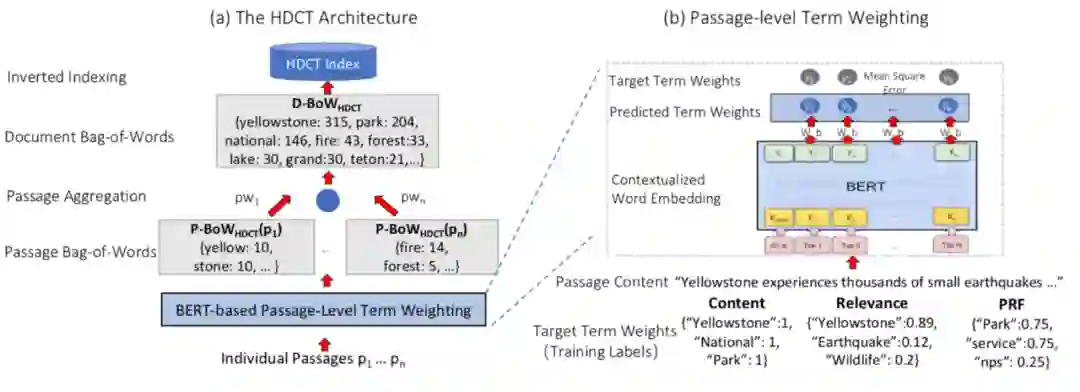
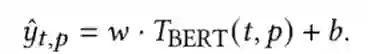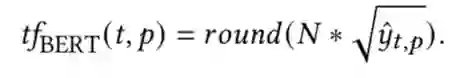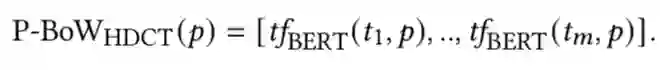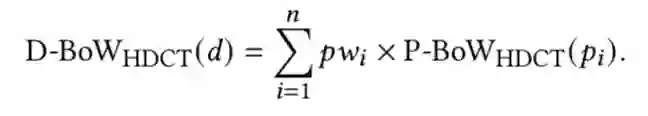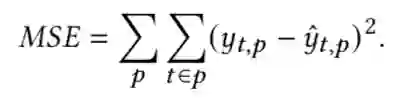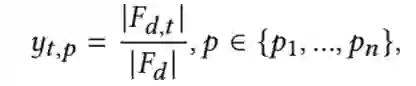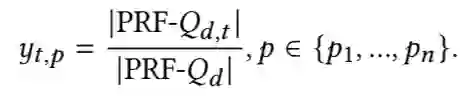具体来说,权重的选取有两种方式:第一种方式认为各段落的重要性相同,即 ;第二种方式考虑用户阅读的注意力随文本的深入而下降,认为各段落的权重随位置前后逐步递减,具体可设置为 。该步骤得到的文档级词项权重可直接应用 BM25 等初步检索模型。模型训练根据给定的 ground truth 权重分数 ,作者以最小化平均平方误差作为目标训练模型,损失函数如下:
具体来说,作者提出了三种获取 ground truth 的方法,分别基于文本内容(document content)、基于相关性信号(relevance)和基于伪相关反馈信号(Pseudo-Relevance Feedback)。基于文本内容的方法考虑包含词项的文本信息源(fields,例如标题、关键词等)的比例。给定文本 的段落集合 和 field 集合 ,ground truth 分数计算方法如下:
基于相关性信号的方法考虑包含词项的相关查询的比例。给定文本的段落集合 和相关查询集合 ,ground truth 分数计算方法如下:
基于伪相关反馈信号的方法考虑包含词项的相关查询得到的伪相关反馈文本的比例。ground truth 分数计算方法如下:
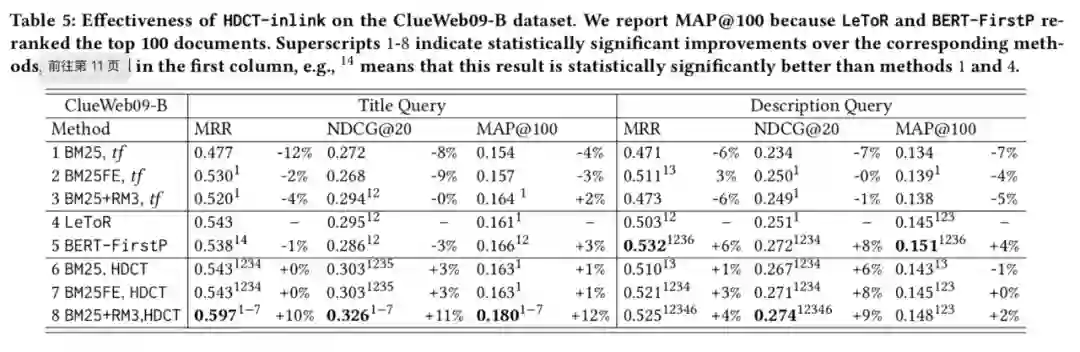
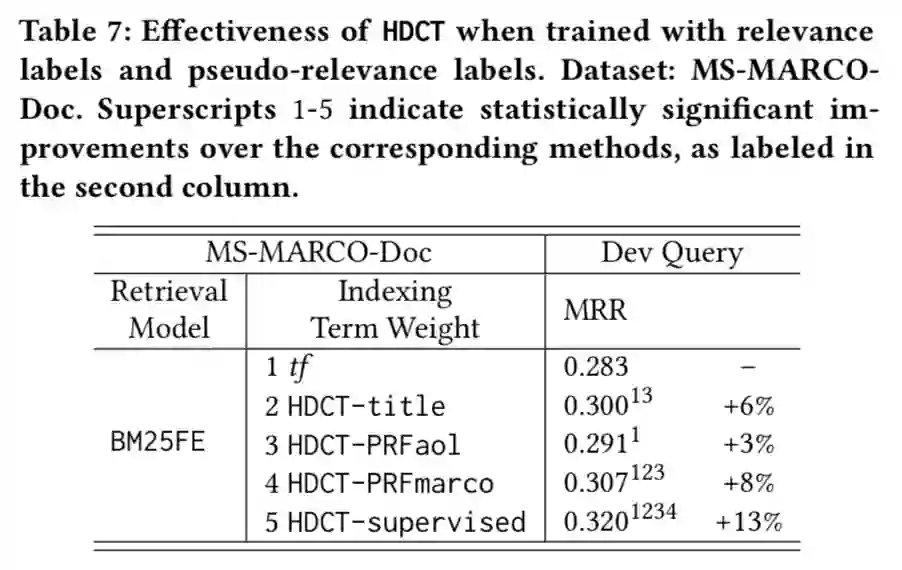
实验本文实验在 ClueWeb 数据集(包括 ClueWeb09-B/C,ClueWeb12-C)和 MS-MARCO Document Ranking 数据集上实现。作者在前者验证了基于内容的训练方法在初步检索任务和重排序任务上的效果,在后者研究了不同训练方法之间的效果差异。 ClueWeb数据集 作者首先在该数据集上对比了传统的 term frequence 算法和 HDCT 得到的权重对 BM25 及相关算法的效果差异。作者分别使用文本的 title 和 inlink 训练模型,发现两种情况效果均优于传统的 term frequence,而在不同的任务上两者效果各有千秋,总体而言使用 inlink 效果略好。