学界 | 受压缩感知启发,斯坦福 AI 研究院提出新的无监督表示学习框架!

非确定性自编码器!
AI 科技评论按:如今,说到图像领域的生成式模型,大家往往会想到对抗生成网络(GAN)和自编码器(AE)。本文介绍了斯坦福 AI 研究院的研究人员如何从统计压缩感知技术中汲取灵感设计出的非确定性自编码器(该编码器在自编码器的潜在空间中对不确定性进行建模),并巧妙地使用变分技术为其设计目标函数,相较于传统方法,该模型的性能有巨大的提升。斯坦福 AI 研究院将这一成果进行了介绍,AI 科技评论编译如下。
压缩感知技术能够通过低维投影有效地采集和恢复稀疏的高维数据信号。 我们在 AISTATS 2019发表的一篇论文(https://arxiv.org/pdf/1812.10539)中提出了非确定性自编码器(UAE),把低维投影作为自编码器的带噪声的潜在表示,并通过一个可跟踪的变分信息最大化目标直接对信号采样(即编码)和逐步恢复(即解码)的过程进行学习。实验表明,我们在高维数据的统计压缩感知任务中相较于其他方法的性能平均提高了 32% 。
无监督表示学习的广泛目标是学习对输入的数据进行变换,从而简便地捕获到数据分布统计的根本特性。在之前的工作中,研究人员已经从潜变量生成建模、降维和其他角度出发,提出了大量的学习目标和算法。在本文中,我们将介绍一个受压缩感知启发而设计出的新的无监督表示学习框架。首先,我们将从统计压缩感知谈起。
统计压缩感知
能够高效地采集和精确地恢复高维数据的系统构成了压缩感知的基础。这些系统得到了广泛的应用。例如,压缩感知技术已经被成功地用于了包括「设计节能的单像素摄像头」和「加快核磁共振医学成像扫描时间」在内的广泛的应用领域。
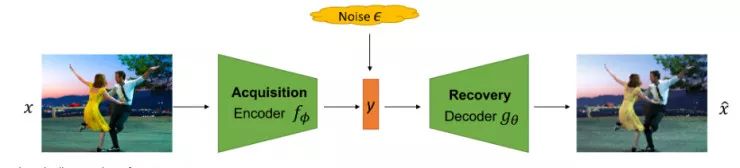
压缩感知的工作流程由两部分组成:
采集(acquisition):一个从高维信号
到测量数据
的映射
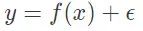
其中 ϵ 代表测量过程中任意的外部噪声。当 m 远小于 n 时,我们称采集过程是高效的。
恢复(recovery):一个从测量数据 y 到恢复的数据信号
的映射
。当归一化损失(例如
)很小时,恢复的过程是精确的。
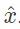
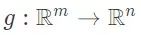
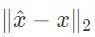
在标准的压缩感知过程中,采集映射 f 在 x 中是典型的线性变换(即对于某个矩阵 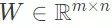
在这项工作中,我们考虑统计压缩感知的情况,其中我们可以访问一个训练数据信号 x 的数据集 D。我们假设对于某些未知的数据分布 q_data,有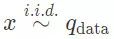
在训练时:
1. 自然环境向智能体提供一个有限的高维信号数据集 D。
2. 智能体通过优化一个恰当的目标来学习信号采集和恢复的映射 f 和 g。
在测试时:
1.对于一个或多个测试信号 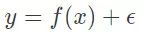
2.智能体恢复出信号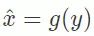
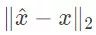
为了实现这个过程,智能体的任务是选取信号采集和恢复的映射 f 和 g,从而最小化测试损失。
非确定性自编码器
实际上,在仅仅根据测量数据 y 恢复出信号 x 时,即使智能体可以选出一个信号采集映射 f,仍有两个不确定性的来源。其一是由于随机的测量噪声 ϵ 引起的。其次,信号采集映射 f 通常被参数化为一个精度有限的受限映射族
在 f 为线性映射的说明样例中,我们确信不可能实现完全精确的恢复。那么还有什么高效的方式来采集数据呢?在下图中,我们考虑了一个真实数据分布是由两个沿正交方向延伸的二维高斯分布的混合分布的简单情况。我们从这个混合分布中采样出了 100 个点(黑色的点),并考虑了两种将这些数据点的维数降低到一维的方法。
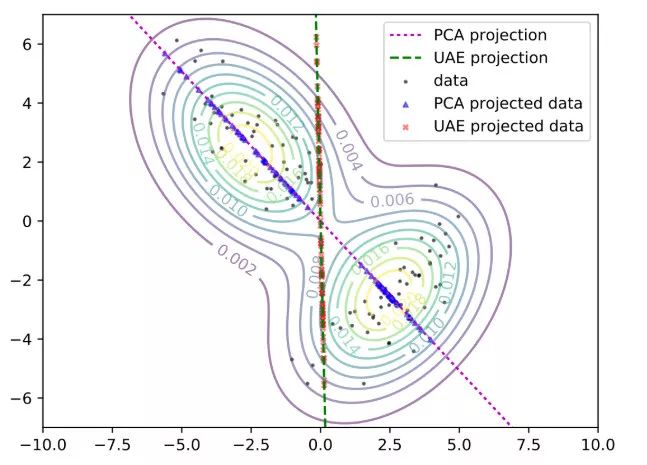
第一种方法是使用主成分分析(PCA)将数据沿着最能导致数据中的变化的方向进行投影。对于上述的二维混合高斯分布的情况,这种方法是通过洋红色线上的蓝点表示的。这条洋红色的线捕获了数据中大部分的变化,但是它将从右下角的高斯分布中采样得到的数据压缩到了一个狭窄的区域中。当多个数据点在低维空间被压缩成重叠的、密集的聚类区域时,在恢复(recovery)过程中就很难消除低维投影与原始数据点之间的关联。
或者,我们可以考虑在绿色的坐标轴上投影(红色的点)。这些投影结果更加分散,这表明恢复过程更加容易(即使与 PCA 相比,这样做会增加投影空间的总方差)。接下来,我们提出了「UAE」框架,它能够精确地学习上面提到的低维投影,使恢复更加准确。
从概率意义上说,信号 x 和测量数据 y 的联合分布可以表示为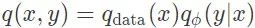
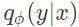
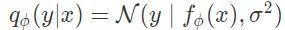
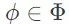
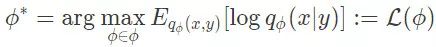
上面的目标函数最大化了从测量数据 y 中恢复出信号 x 的对数后验概率,这与上面提到的智能体在测试时的目标是一致的。
变分信息最大化
或者,你可以将上述过程解释为最大化信号 x 和测量数据 y 之间的互信息。为了查看二者之间的联系,请注意数据熵 H(x) 是一个常量,它不会影响优化过程。因此,我们可以将目标函数改写为:
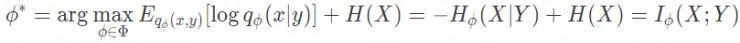
遗憾的是,在当前的情况下,估计(和优化)互信息是十分困难和棘手的。为了克服这个困难,同时也能快速地进行恢复,我们建议使用一个互信息变分下界的平摊变体。
特别地,我们考虑一个真实后验概率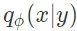
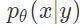
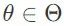
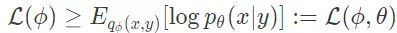
上面的表达式定义了非确定性自编码器的学习目标,其中数据采集过程可以被看作对数据信号进行编码,而恢复过程则相当于根据测量数据解码出数据信号。
案例分析
实际上,「UAE」目标函数的期望值是通过蒙特卡洛方法来估计的:数据信号 x 是从训练数据集 D 中采样得到的,测量数据 y 是从一个允许重参数化的假设的噪声模型(各向同性的高斯分布)中采样得到的。根据对恢复过程的准确度的度量,我们可以在平摊变分分布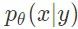
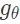
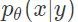
举例来说,不妨考虑一个带有已知的标量方差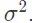
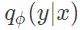
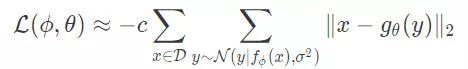
其中 c 为独立于 φ 和 θ 的正归一化常数。
非确定性自编码器 VS 常用的自编码器
除了对统计压缩感知的提升,非确定性自编码器(UAE)为无监督表示学习提供了一种替代框架,其中压缩的测量值可以被解释为潜在的表示。下面,我们将讨论 UAE 与常用的自编码器在计算方法上有何异同。
标准的自编码器(AE):当潜在空间中没有任何的噪声时,UAE 的学习目标函数就会退化为 AE 的目标函数。
去躁自编码器(DAE):DAE 在观测空间中添加噪声(例如,向数据信号添加噪声),然而 UAE 则是在潜在空间中对不确定性建模。
变分自编码器(VAE):变分自编码器将潜在空间正则化,使其遵循一个先验分布。而在 UAE 中则没有显式的先验,因此在潜在空间上没有 KL 散度正则项(而原始论文中没有对此进行讨论,UAE 的目标函数可以看做 β=0 时的 β-VAE 的特例)。这样就避免了使用 VAE 使存在的问题:使用强大的解码器会忽略潜在的表示。
那么 UAE 是否能像 DAE 和 VAE 那样,可以进行样本外的泛化呢?答案是肯定的!在恰当的假设下,我们说明了 UAE 学到了一个隐式的数据信号分布的生成模型,它可以被用来定义一个马尔科夫链蒙特卡洛(MCMC)采样。更多细节请参阅论文「Uncertainty Autoencoders: Learning Compressed Representations via Variational Information Maximization」(https://arxiv.org/pdf/1812.10539.pdf)中的定理 1 和推论 1。
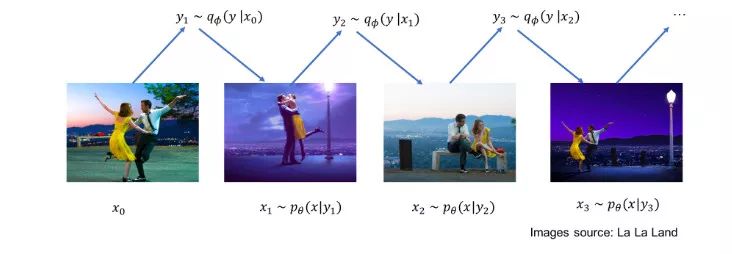
基于 UAE 的用于 q_data 的马尔科夫链采样器示意图。
实验结果概述
我们展示出了一些在下面的图像数据集上进行统计压缩感知的实验结果。在这些实验中,测量数据的个数 m 会变化,并且使用了随机高斯噪声。我们与两种基线进行了对比:
适当的稀疏性诱导基础上的 LASSO
CS-VAE/DCGAN,这是一种最近提出来的压缩感知方法,它通过搜索预训练的生成模型(如 VAE 和 GAN)的潜在空间来寻找潜在向量,从而使恢复损失最小。
MNIST
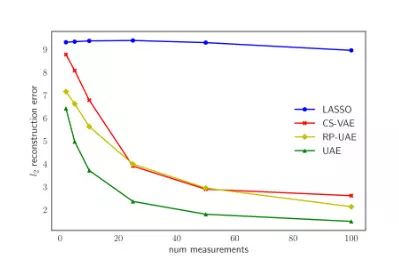
测量数据个数 m 变化时的测试的 l2 重建误差(每张图像)

测量值的个数为 m=25 时的重建结果。
CelebA
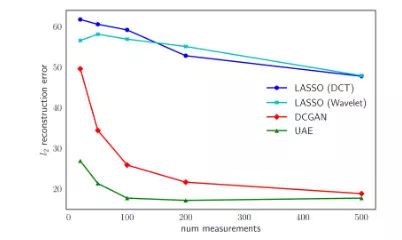
测量数据个数 m 变化时的测试的 l2 重建误差(每张图像)
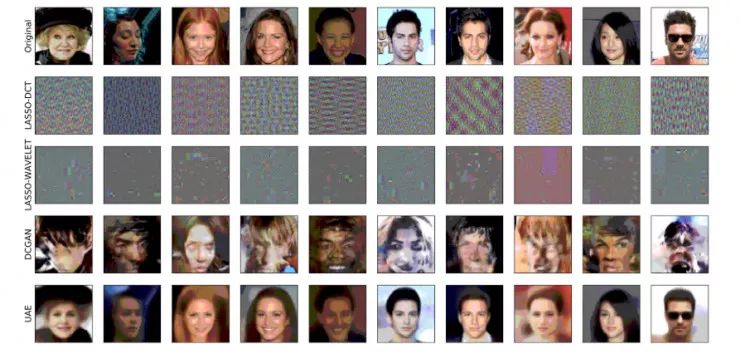
测量值的个数为 m=50 时的重建结果。
平均而言,我们观察到,对于所有的数据集和测量值来说,我们取得了 32% 的提升。关于在更多的数据集上的实验结果,以及将 UAE 应用到迁移学习和监督学习中的任务,请参阅我们的论文:
「Uncertainty Autoencoders: Learning Compressed Representations via Variational Information Maximization」Aditya Grover, Stefano Ermon. AISTATS, 2019。
论文下载地址:https://arxiv.org/pdf/1812.10539
代码:https://github.com/aditya-grover/uae
via http://ai.stanford.edu/blog/uncertainty-autoencoders/
2019 年 7 月 12 日至 14 日,由中国计算机学会(CCF)主办、雷锋网和香港中文大学(深圳)联合承办,深圳市人工智能与机器人研究院协办的 2019 全球人工智能与机器人峰会(简称 CCF-GAIR 2019)将于深圳正式启幕。
届时,诺贝尔奖得主JamesJ. Heckman、中外院士、世界顶会主席、知名Fellow,多位重磅嘉宾将亲自坐阵,一起探讨人工智能和机器人领域学、产、投等复杂的生存态势。

今日限量赠送3张1000元门票优惠码,门票原价1999元,打开以下任一链接即可使用,券后仅999元,限量3张,先到先得,送完即止。
https://gair.leiphone.com/gair/coupon/s/5d0763011b2e8
https://gair.leiphone.com/gair/coupon/s/5d0763011b077
https://gair.leiphone.com/gair/coupon/s/5d0763011ae43





