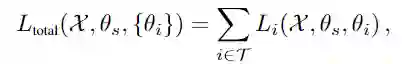来源:Google AI
编辑:LRS
【新智元导读】对于多任务场景来说,最大的难点就在于如何找到多个任务之间相互关联的部分。Google Brain团队在NeurIPS 2021上发表了一篇论文,提出一个亲和力指标,能将训练速度提升32倍,直接少训练2000个小时,相当于省了6200美元!
通常情况下,一个机器学习模型一次学习过程中只针对一个任务进行训练。例如语言模型的训练只有一个任务,就是在给定单词的上下文来预测下一个单词的概率,目标检测的任务就是识别图像中所有可能存在的物体。
但更广泛的人工智能应用场景要求一个模型能够很好地完成多个任务,反过来同时学习多任务也能极大提高训练效率和模型性能,从而形成一个正反馈。多任务在现实生活中的应用场景也越来越多,机器人需要同时学习如何拾取、放置、对齐和重新排列各种物体等多个任务才能正式「上岗工作」。
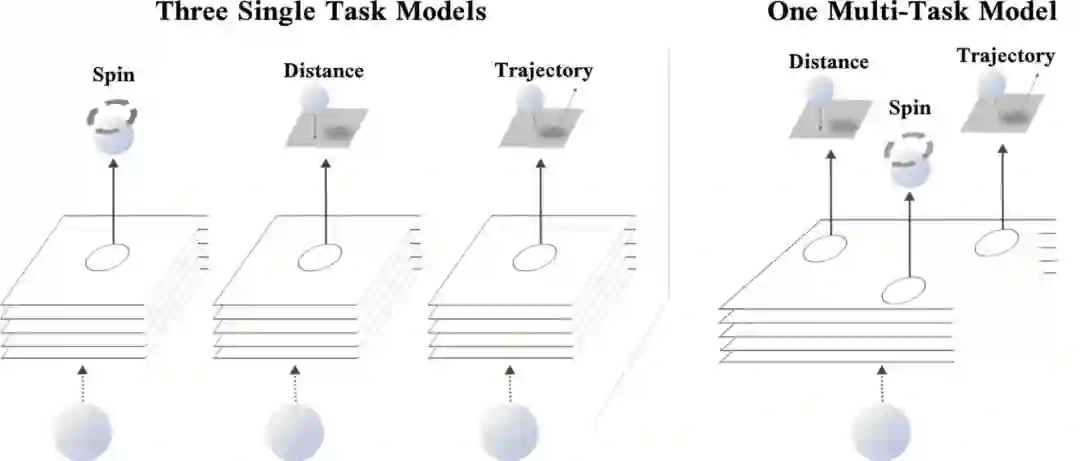
一个典型的例子就是当你打乒乓球时,不仅要判断乒乓球的距离、旋转角度以及判断乒乓球的运行轨迹,并且同时还要调整身体进行挥拍。但如果要人工智能模型来做,对于过程中的每一个任务可能都需要一个模型来单独预测,因为预测乒乓球的旋转角度和预测乒乓球的位置从根本上来说需要不同的特征来进行预测。
但如果能同时预测好乒乓球的旋转和位置,则对于更好地推理出乒乓球的预测轨迹来说一定是有帮助的。所以如果一个深度学习模型能够同时训练并预测这三个任务,那肯定比单独预测三个任务来说准确率更高。
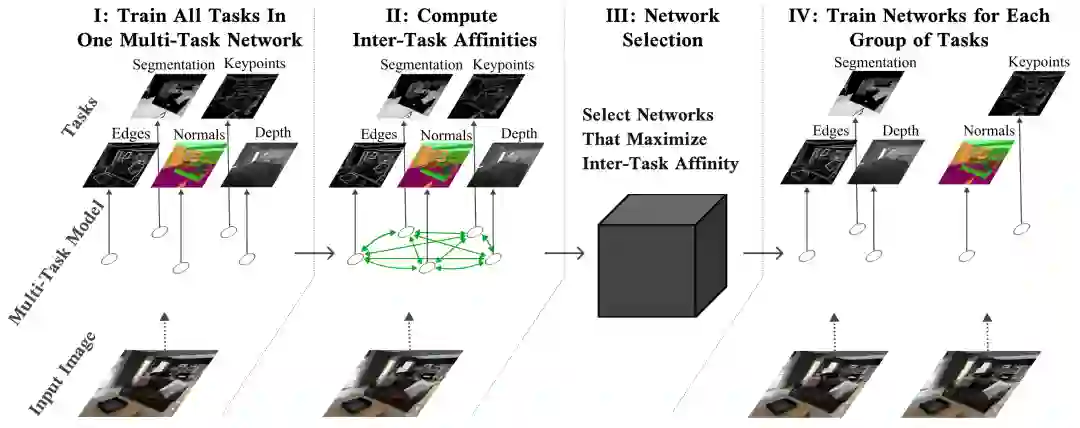
对于如何有效地训练多任务,Google Brain团队在NeurIPS 2021上发表了一篇论文,提出了一个新方法,能够在多任务神经网络中确定哪些任务可以一起训练。研究人员首先将一组任务分成较小的子集,先使得所有任务都得到充分训练。
为了达到性能最大化,需要将所有任务一起列入单个多任务模型中训练,并测量每个任务在模型参数上的梯度更新对网络中其他任务的loss 影响程度,这个影响程度也被称为任务间的亲和力(inter-task affinity)。实验结果表明选择最大化任务间亲和力的任务组,能够显著提升整体模型的性能。
https://ai.googleblog.com/2021/10/deciding-which-tasks-should-train.html
一个多任务模型首先面临的一个问题是:哪些任务可以一起训练?
在理想情况下,一个多任务学习模型能够把它在每一个任务的训练中获得的信息用于降低网络训练中包含的其他任务的损失。这种信息的传递融合可以合并为一个模型,这样不仅可以对多个任务分别做出多个预测,而且与针对每个任务的不同模型的训练性能相比,多任务联合预测的准确性可能还会提高。
但多任务联合训练也有一个弊端,如果只训练一个单一的模型可能会导致模型参数量上升。并且如果多个任务是互不关联的,那模型的性能也会急剧下降。
就像如果一个人一边打乒乓球,一边在思考斐波那契数列的下一个值,那肯定会影响他对于乒乓球位置、旋转角度和轨迹的预测。
一个最直接的方法就是对一组任务的多任务网络的所有可能组合进行全面搜索,挨个尝试模型的性能,但这种搜索成本可能会高到劝退。特别是如果任务量非常大的话,那可能的组合方式也会呈指数级增长。
如果模型在运行过程中需要不断增加和删除任务的话,那情况将会更加复杂。由于任务是从所有任务集中添加或删除的,每次增加删除任务都需要重复测量才能确定新的任务组。
此外,随着模型的规模和复杂性不断增加,即使是只评估可能的多任务网络的一个子集的近似任务分组算法,模型的训练也可能变得十分耗时到难以接受的地步。
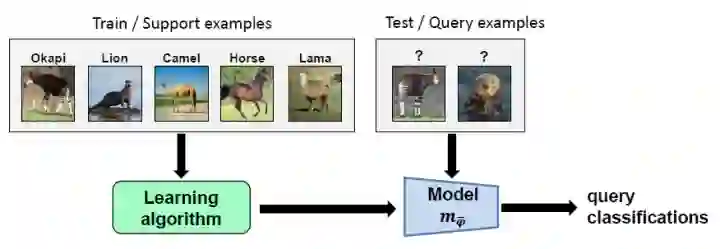
研究人员受到元学习的启发,因为元学习的目标就是可以训练一个能够快速适应新的、以前未完成的任务的神经网络。
经典的元学习算法MAML通过对一组任务的模型参数应用梯度更新,然后更新其原始参数集以将该集合中计算的任务子集损失最小化。通过使用这种方法,MAML能够训练出一个模型来学习表示。这个表示方法并不是将其当前权重的损失最小化,而是在一个或多个训练步骤后对权重进行训练。
因此,MAML能够训练一个模型使其能够快速适应以前未完成的任务,因为它是在为未来而不是当下的目标进行优化。
TAG使用类似的机制来使得多任务神经网络能够动态地训练。并且它只更新单个任务的模型参数来观察这一变化将如何影响多任务神经网络中的其他任务,然后取消这次更新。
通过对其他任务重复此过程,以收集关于网络中每个任务如何与任何其他任务交互的信息。然后通过更新网络中每个任务的模型共享参数,继续进行正常训练。
收集到这些统计数据后并观察其在整个训练过程中的动态情况,可以发现某些任务始终显示出正向的关系,而有些任务则相互对立(产生负面的性能影响)。
网络选择算法可以利用这个信息将任务分组在一起,以最大化任务间的亲和力,这也取决于从业者在推断过程中可以使用多少多任务网络。
任务间的亲和力以考虑一个任务对共享参数的连续梯度更新在多大程度上影响网络中其他任务为目标,并且所有任务的亲和力相加作为整体任务的亲和力,其中Li代表任务i的损失。
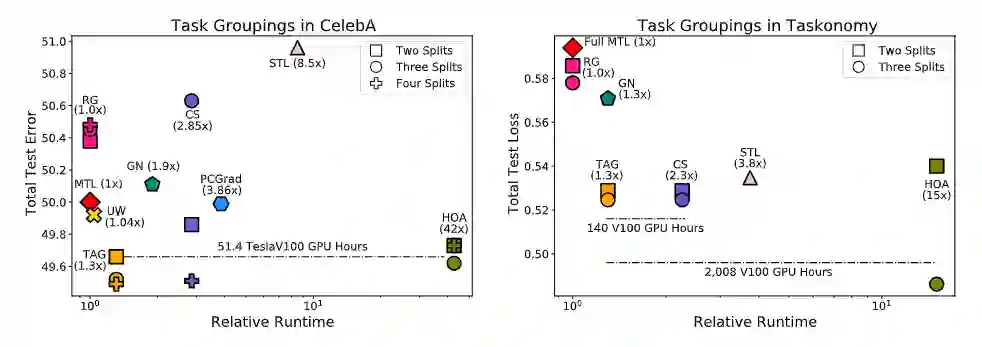
实验结果表明,TAG可以选择出强相关的任务组。在Celeba和TaskOnomy数据集上,TAG和sota模型相比运行速度的提升分别为32倍和11.5倍。
实验人员还评估了TAG在任务集中对语义分割、深度估计、关键点检测、边缘检测和曲面法线预测的任务组选择的能力。这个评估使用了一个增强版的中型任务单元拆分(2.4 TB),而非完整版(12 TB),这个操作能够减少计算开销并提高可复制性。
与Celeba上的研究结果相同,TAG继续以10.0%相比MTL、7.7%相比GN、1.5%相比STL和9.5%相比RG的优势获胜。将TAG与HOA进行比较时,可以看到TAG 的2-split 任务分组性能比HOAD高2.5%,但HOA的3-split任务分组性能优于tag。
在计算方面,TAG的效率明显高于HOA,HOA要求额外的2008 TESLAV100 GPU小时来查找任务组。为了考虑到这一成本,在一个8-GPU的AWS实例中,TAG和HOA之间的货币支出差异将为6144.48美元。类似地,TAG和CS在taskonomy上的性能是相等的,但是TAG的效率更高,计算任务组所需的teslav100 gpu小时少于140小时。
总而言之,TAG对于确定哪些任务在训练中可以协同训练来说是一种有效的方法,该方法研究了任务如何通过训练相互作用,特别是在一个任务上训练时更新模型参数对网络中其他任务丢失值的影响。
参考资料:
https://ai.googleblog.com/2021/10/deciding-which-tasks-should-train.html
![]()