从零开始训练目标检测器总结 | Rethinking ImageNet预训练
点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达

作者: 中国移不动
https://zhuanlan.zhihu.com/p/83635871
本文已由原作者授权,不得擅自二次转载
首先说明两个问题
一、
在2017年的DSOD之前,所有的目标检测器都使用了ImageNet预训练,这不是因为玩目标检测的研究人员穷,而是,不使用ImageNet预训练的模型检测精度明显低于预训练的模型。
那么,到底能不能在不使用ImageNet预训练的情况下,仅使用目标数据集训练就能达到甚至超过ImageNet预训练的精度?
2017年出品的DSOD回答:是,从零开始训练网络可以达到甚至超过预训练网络的精度。
二、
预训练的权重随便下载,为什么还要从头开始训练网络?
答:如果需要使用预训练分类网络(ResNet,VGG之类)的权重参数,则几乎无法变动其网络结构,而对于目标检测来说,很多检测器必须要大幅改动ResNet、VGG等网络,这就需要将改动后的网络重新拿到ImageNet上预训练,代价较大。
有些图像,如医疗图像、深度图和ImageNet的差距过大,采用ImageNet预训练的网络在不同域之前的迁移效果不一定OK。
DSOD:Train from Scratch的首次成功尝试
DSOD提出了4个原则,满足这4个原则即可以成功的Train from Scratch。但是…… 这4个原则已经全部被否定…… 这4个原则是这样的:
Proposal-free,即不使用RPN(Region Proposal Network )
作者解释的原因:RoI Pooling使梯度的传播不再平滑。
惨遭打脸,Rethinking用的就是Mask R-CNN架构
2. Deep Supervision,即使用DenseNet这样密集连接的主干网络(最重要的一点)
作者解释的原因:可以减缓梯度消失
被打脸,ScratchDet的一大目的就是解决DSOD在DenseNet以外的主干网络上不work的问题。
3. Stem Block 即增加Inception 那样的stem block。DSOD所用的Stem块由3个3×3的卷积层连接一个2×2的最大池化层组成,用于减少信息损失,提升性能。
被疯狂打脸,ScratchDet用的是VGG和resnet,Rethinking用的是resnet……
4. Dense Prediction Structure 即使用类似SSD的多尺度预测,并且不同尺寸的feature map通过下采样连接。
这个… 也不是必要条件。
ScratchDet:Train from Scratch距离成功只差一个Batch Normalization
ScratchDet的灵感来源于NIPS2018 How Does Batch Normalization Help Optimization?这篇文章,这篇文章指出,Batch Normalization好用的原因并不是减少了internal covariate shift,而是BN使得优化空间更加平滑了,和resnet加入skip connections就work了的原因相同:
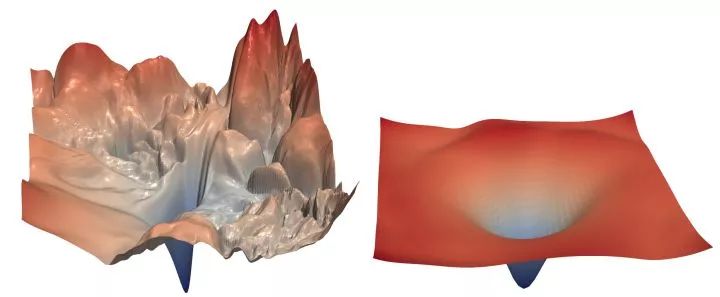
具体来讲,BN在优化中的作用为:
梯度更加稳定,更加可预测。
计算梯度时可采⽤更⼤的步⻓,即更⼤的学习率来加速训练。
防⽌loss函数解空间突变,既不会掉⼊梯度消失的平坦区域,也不会掉⼊梯度爆炸的局部最⼩。
放到Train from Scratch这个话题上来说,BN可以帮助训练收敛。沿着这个思路作者在SSD300检测框架上给VGG⽹络与检测⼦⽹络分别加上了BN来进⾏随机初始化训练,调整学习率之后,得到的最好结果78.7mAP,⽐直接随机初始化训练SSD的结果(67.6)⾼11.6,⽐原SSD300(77.2)⾼1.5,⽐使⽤预训练模型VGG-16-BN(78.2)⾼0.6。
Rethinking ImageNet Pre-training
该文章的结论如下:
Train from Scratch是可以达到和ImageNet预训练同样的精度的,但需要更多的迭代。
fine-tune不能减少过拟合,但是可以明显加快收敛速度。
对于位置敏感的任务,分类的模型fine-tune的作用会变小。
Rethinking也强调了使⽤Normalization。注意Rethinking和ScratchDet是同一个时间发布的文章。和ScratchDet不同的是,Rethinking输⼊图⽚分辨率较⼤,每张显卡只能容纳两张图,使用BN时因为得不到足够的统计量,反而会降低模型的准确率。于是Kaiming选择了syncBN和GN,syncBN使用多个GPU来为BN提供足够多的数据量,而GN的计算和batch大小无关。
结合Rethinking,ScratchDet的作者指出,要想从零开始训练一个检测器,需要满足以下3个条件:
都使用了稳定梯度的手段(BN、GN、syncBN)
充足的训练+合适的学习率
训练数据不能太小
Rethinking DSOD
回到最初的DSOD,既然作者的4个结论均遭打脸,那DSOD为什么work呢?原因就是DSOD满足上以上3点。其中2与3不必多言,重点说下第1个原因。还记得DSOD使用了什么主干网络吗?DenseNet,而且DSOD的设计在DenseNet以外的主干网络中表现不佳。为什么DenseNet就可以,看了下图就一目了然:
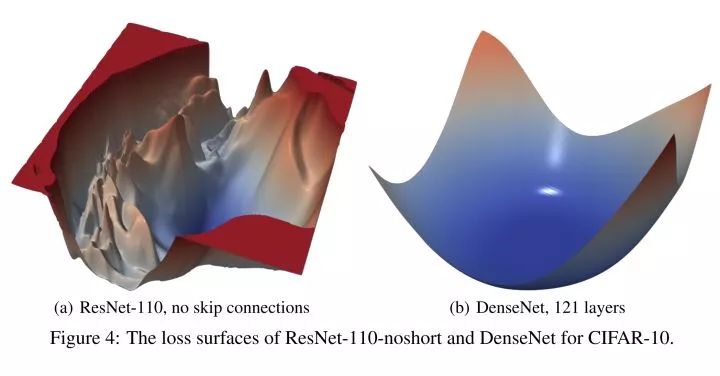
这不是跟Normalization的作用一样吗!
重磅!CVer-目标检测交流群成立啦
扫码添加CVer助手,可申请加入CVer-目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测和模型剪枝&压缩等群。一定要备注:研究方向+地点+学校/公司+昵称(如目标检测+上海+上交+卡卡)

▲长按加群

▲长按关注我们
麻烦给我一个在看!


