通过自动强化学习 实现远距离机器人导航
文 / Aleksandra Faust,Google 机器人团队高级研究员;Anthony Francis,高级软件工程师
仅在美国,就有 300 万人因运动机能损伤而无法走出家门。能够自主进行远距离导航的服务机器人可以帮行动不便者递取生活用品、药品和包裹等,让他们更独立地生活。研究表明,深度强化学习 (RL) 善于将原始感官输入映射到动作,例如 学习抓取物体 和机器人运动,但 RL 智能体通常不能理解大型物理空间,因而无法在没有人类帮助的情况下实现安全的远距离导航,也不能轻松地适应新空间。
在近期的三篇论文《通过 AutoRL 端到端地学习导航行为》(Learning Navigation Behaviors End-to-End with AutoRL)、《PRM-RL:通过结合强化学习和基于采样的规划完成远距离机器人导航任务》(PRM-RL: Long-Range Robotic Navigation Tasks by Combining Reinforcement Learning and Sampling-based Planning),以及《通过 PRM-RL 实现远距离室内导航》(Long-Range Indoor Navigation with PRM-RL) 中,我们通过将深度 RL 与远距离规划相结合探讨了易适应的机器人自主性。我们训练本地规划智能体执行基本导航行为,安全走过较短距离,而不会与移动障碍物发生碰撞。本地规划器接收噪声传感器观测数据,例如使用一维雷达提供距障碍物的距离,并输出线速度和角速度用于机器人控制。我们使用 AutoRL 对本地规划器进行模拟训练,AutoRL 是一种自动搜索 RL 奖励和神经网络架构的方法。尽管本地规划器的活动范围限制在 10 到 15 米内,但它们可以很好地迁移到真正的机器人和此前从未见过的新环境。因此,我们可以将其用作大空间导航的构建块。然后,我们构建了一个路线图,图中的节点表示地点。本地规划器可以通过其噪声传感器和控制很好地模仿真正的机器人,只有当本地规划器能够可靠地在节点中穿行时,连线才会连接节点。
自动强化学习 (AutoRL)
在 第一篇论文 中,我们是在小型的静态环境中训练本地规划器。然而,使用标准的深度 RL 算法(例如深度确定策略梯度,即 DDPG 算法)进行训练会带来一些挑战。例如,本地规划器的真正目的是达成目标,这代表获得稀疏奖励。在实践中,这需要研究人员花费大量时间迭代和手动调整奖励。此外,研究人员还必须在没有明确公认的最佳实践的情况下,就神经网络架构做出决策。最后,像 DDPG 这类算法无法进行稳定的学习,并且经常表现出灾难性的健忘。
注:第一篇论文 链接
https://ieeexplore.ieee.org/document/8643443
为了解决这些挑战,我们将深度强化学习 (RL) 训练自动化。AutoRL 是一个围绕深度 RL 的演化自动化层,使用 大规模超参数优化 来搜索奖励和神经网络架构。它的工作分为两个阶段,即奖励搜索和神经网络架构搜索。在奖励搜索期间,AutoRL 会同时对一群 DDPG 智能体进行持续几代的训练,每个智能体的奖励函数略有不同,用以优化本地规划智能体的真正目标:到达目的地。在奖励搜索阶段结束时,我们会选择最常引领智能体到达目的地的奖励。在神经网络架构搜索阶段,我们会重复这一过程,这次使用选定的奖励并调整网络层,以优化累计奖励。
注:大规模超参数优化 链接
https://ai.google/research/pubs/pub46180
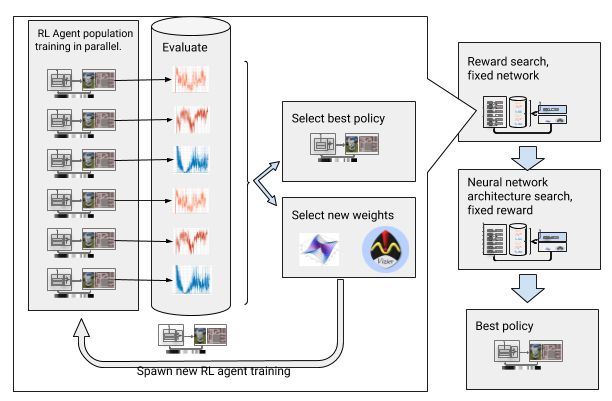
包含奖励搜索和神经网络架构搜索的自动强化学习
但是,此迭代过程意味着 AutoRL 的样本利用效率低下。训练一个智能体需要 500 万个样本;AutoRL 对 100 个智能体进行超过 10 代的训练需要 50 亿个样本,这相当于训练 32 年!这样训练的好处是,AutoRL 之后的手动训练流程是自动进行,而且 DDPG 不会发生灾难性健忘。最重要的是,由此产生的策略质量更高 — AutoRL 策略对传感器、执行器和本地化噪声而言非常稳健,并且可以很好地泛化到新环境。在我们的测试环境中,最佳策略的成功率比其他导航方法高 26%。
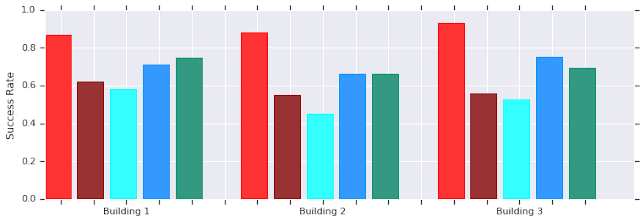
AutoRL(红色)在多个从未见过的建筑中进行短距离(不超过 10 米)导航的成功率。与手动调整的 DDPG(深红色)、人工势场法(浅蓝色)、动态窗口法(蓝色),以及行为克隆(绿色)相比较
迁移到机器人的 AutoRL 本地规划器策略,该机器人处于真实的非结构化环境中
虽然这些策略只执行本地导航,但它们对移动的障碍物而言非常稳健,并且可以很好地迁移到真正的机器人,即使在非结构化环境中也是如此。虽然在模拟训练中使用的只是静态障碍物,但它们也可以有效地处理移动物体。下一步是将 AutoRL 策略与基于采样的规划结合起来,以扩大其到达范围并实现远距离导航。
通过 PRM-RL 实现远距离导航
基于抽样的规划器通过粗略估计机器人运动来处理远距离导航。例如,概率路线图 (PRM) 对机器人的动作姿态抽样并将其与可行的转变联系起来,以创建能够在大空间中捕捉机器人有效移动的路线图。在 第二篇论文 中,我们将 PRM 与手动调整的基于 RL 的本地规划器(不使用 AutoRL)相结合,在本地训练一次机器人,然后使其适应不同的环境,该论文荣获 2018 年 IEEE 机器人与自动化国际会议 (ICRA) 最佳服务机器人论文。
注: 第二篇论文 链接
https://ai.google/research/pubs/pub46570
首先,对于每个机器人,我们在通用的模拟训练环境中训练一个本地规划器策略。然后,我们在部署环境的平面图上构建一个与此策略相关的 PRM,称为 PRM-RL。对于我们希望按照一次一个机器人 + 环境的设置在建筑物中部署的任何机器人,都可以使用相同的平面图。
为构建 PRM-RL,只有在能够很好地表示机器人噪声的 RL 本地规划器能够可靠且一致地在节点间导航时,我们才连接采样节点。此过程通过蒙特卡罗模拟完成。我们根据特定机器人的功能和几何形状对生成的路线图做了调整。对于具有相同几何形状,但传感器和执行器不同的机器人,其路线图会有不同的连接。由于智能体可以在拐角周围导航,所以路线图可以包含视线不清晰的节点。反之,由于传感器噪声,墙壁和障碍物附近的节点则不太可能连接为路线图。在执行时,RL 智能体在路线图的路径点间导航。

通过对每个随机选择的节点对进行 3 次蒙特卡罗模拟构建的路线图
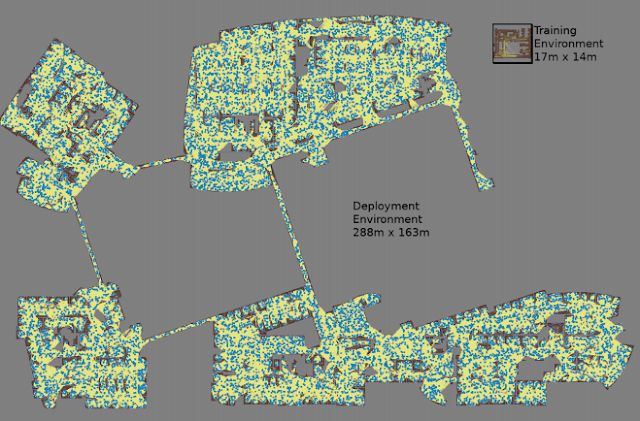
最大的地图为 288 米乘 163 米,包含近 700000 条连线,在集群中使用 300 个工作器花费 4 天多时间收集,需要进行 11 亿次碰撞检查
第三篇论文 对原始 PRM-RL 做了一些改进。首先,我们将手动调整的 DDPG 替换成经过 AutoRL 训练的本地规划器,从而改进远距离导航的效果。然后,添加机器人在执行时使用的同步定位和映射 (SLAM) 地图,作为构建路线图的来源。由于 SLAM 地图非常嘈杂,这一更改弥补了 “Sim2Real 差距”,这是机器人领域中的一种现象,即经过模拟训练的智能体在迁移到真正的机器人时性能会大幅下降。我们的模拟成功率与机器人实验的成功率相同。最后,我们添加了分布式路线图构建,产生的路线图规模非常大,包含多达 700000 个节点。
注:第三篇论文 链接
https://arxiv.org/abs/1902.09458
我们使用 AutoRL 智能体评估了此方法,使用比训练环境大 200 倍的办公室楼层图构建路线图,接受在 20 次试验中成功率大于等于 90% 的连线。我们在 100 米的距离(远超本地规划器的活动范围)内将 PRM-RL 与各种不同方法进行了比较。PRM-RL 的成功率超过基线 2 到 3 倍,因为我们已根据机器人的功能将节点进行了适当连接。
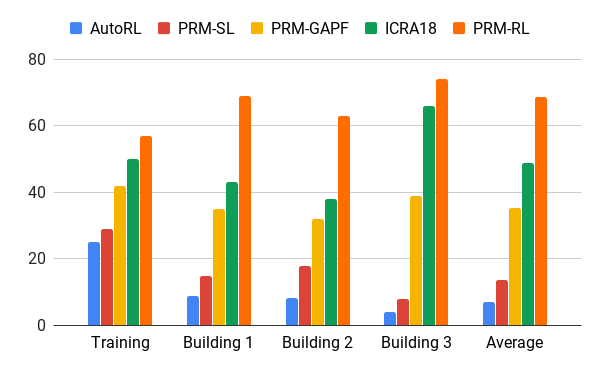
在几座建筑物中超过 100 米的距离进行导航的成功率。
第一篇论文 - AutoRL,仅本地规划器(蓝色);
原始 PRM(红色);路径导引人工势场(黄色);
第二篇论文(绿色);
第三篇论文 - 采用 AutoRL 的 PRM(橙色)
我们使用多个真实的机器人和建筑现场测试了 PRM-RL。一组测试如下所示;除了杂乱区域附近和超出 SLAM 地图边缘的位置,机器人的表现都非常稳定。
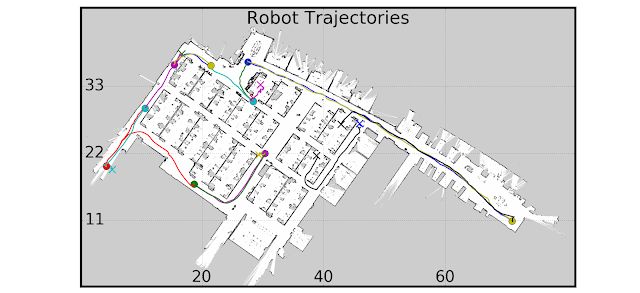
机器人实验
结论
自主机器人导航可以显著提高行动不便人士的独立性。我们可以通过发展容易适用的机器人自主性来实现这一目标,包括能够使用已有信息在新环境中部署的方法。我们的实现方法是,通过 AutoRL 自动学习基本的短距离导航行为,然后将习得的策略与 SLAM 地图相结合,构建路线图。这些路线图由节点构成,节点由机器人能够一致穿越的连线连接在一起。结果表明,经过一次训练的策略可以用于不同的环境,并且可能生成针对特定机器人的定制路线图。
致谢
此研究的参与者有(以姓氏字母排序):来自谷歌机器人团队的 Hao-Tien Lewis Chiang、James Davidson、Aleksandra Faust、Marek Fiser、Anthony Francis、Jasmine Hsu、J. Chase Kew、Tsang-Wei Edward Lee、Ken Oslund、Oscar Ramirez 和来自新墨西哥大学的 Lydia Tapia。感谢 Alexander Toshev、Brian Ichter、Chris Harris 和 Vincent Vanhoucke 提供的有益讨论。
更多 AI 相关阅读:




