使用网格搜索优化CatBoost参数
编者按:格里菲斯大学研究员James Lyons简要地介绍了梯度提升的原理,并分享了使用CatBoost的经验。

CatBoost是由Yandex发布的梯度提升库。在Yandex提供的基准测试中,CatBoost的表现超过了XGBoost和LightGBM。许多Kaggle竞赛的优胜者使用了XGBoost,因此CatBoost很值得考察一下。
快速示例
通过如下命令安装CatBoost
pip install catboost
在Windows 10/python 3.5上,一切工作良好。CatBoost的接口基本上和大部分sklearn分类器差不多,所以,如果你用过sklearn,那你使用CatBoost不会遇到什么麻烦。CatBoost可以处理缺失的特征以及类别特征,你只需告知分类器哪些维度是类别维度。
让我们在UCI Repository Adult Dataset上做个快速的试验。这一数据集包含约32000个训练样本,16000个测试样本。其中有14个特征,包括类别和连续值,其中一些特征缺失。我们将使用pandas解析csv文件:
import pandas
import numpy as np
import catboost as cb
# 从csv文件读取训练数据和测试数据
colnames = ['age','wc','fnlwgt','ed','ednum','ms','occ','rel','race','sex','cgain','closs','hpw','nc','label']
train_set = pandas.read_csv("adult.data.txt",header=None,names=colnames,na_values='?')
test_set = pandas.read_csv("adult.test.txt",header=None,names=colnames,na_values='?',skiprows=[0])
# 转换类别栏为整数
category_cols = ['wc','ed','ms','occ','rel','race','sex','nc','label']
for header in category_cols:
train_set[header] = train_set[header].astype('category').cat.codes
test_set[header] = test_set[header].astype('category').cat.codes
# 将标签从数据集中分离
train_label = train_set['label']
train_set = train_set.drop('label', axis=1) # 移除标签
test_label = test_set['label']
test_set = test_set.drop('label', axis=1) # 移除标签
# 训练默认分类器
clf = cb.CatBoostClassifier()
cat_dims = [train_set.columns.get_loc(i) for i in category_cols[:-1]]
clf.fit(train_set, np.ravel(train_label), cat_features=cat_dims)
res = clf.predict(test_set)
print('error:',1-np.mean(res==np.ravel(test_label)))
使用如下命令运行这一试验:
python cb_adult.py
20次运行的平均错误率是12.91%. 这比数据集列出的所有样本分类结果都要好(列出的最好结果是朴素贝叶斯的14%错误率)。考虑到我们还没有进行任何优化,这个结果可不赖。
数据集中的类别特征都以字符串的形式表示。我们需要将其转换为整数,以便CatBoost使用。使用pandas,这很容易办到。CatBoost看起来不能够处理类别栏中的缺失特征,我们通过pandas修正了这一点,直接将missing作为一个类别。CatBoost可以很好地处理连续值类型的缺失特征。
梯度提升介绍
CatBoost是一个梯度提升库,我将在本节中简要地描述梯度提升是如何工作的。
“梯度提升”源于“提升”,或者说,通过组合弱模型以构建强模型,从而提升弱模型的表现。梯度提升是提升的一个扩展,其中叠加生成弱模型的过程规划为基于一个目标函数的梯度下降算法。梯度提升属于监督学习方法,这意味着它接受一个带标签的训练实例集合作为输入,构建一个模型,该模型基于给定的特征,尝试正确预测新的未见样本的标签。
梯度提升可以使用许多不同种类的模型,但在实践中几乎总是使用决策树。开始训练时,构建单棵决策树预测标签。这第一棵决策树将预测一些实例,但在另一些实例上会失败。从真实标签(yi)减去预测标签(ŷi),将显示预测是低估还是高估,这称为残差(ri)。
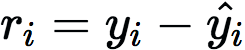
为了提升这一模型,我们可以构建另一棵决策树,不过这回将预测残差而不是原始标签。这可以认为是构建另一个模型以纠正现有模型的错误。添加新树至模型后,做出新预测,接着再次计算残差。为了使用多棵树做出预测,直接让给定实例通过每棵树,并累加每棵树的预测。通过构建估计残差的预测器,我们实际上最小化了真实标签和预测标签的方差的梯度:
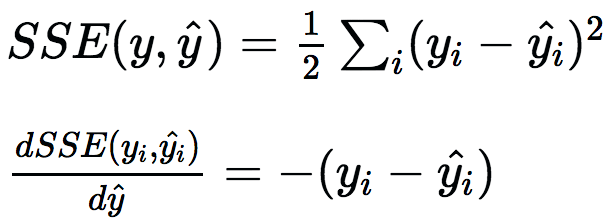
如果我们不想使用方差,我们可以使用交叉熵之类的其他可微函数,接着预测相应的残差。以上覆盖了梯度提升的基础,但还有一些额外的术语,例如,正则化。你可以看下XGBoost是如何进行正则化的。
分类调优参数
上一节概览了梯度提升如何工作的基础,本节中我将介绍CatBoost提供的一些调整预测的把手。你可以在文档中找到更多参数,但如果关注的是模型表现的话,并不需要调整更多参数。
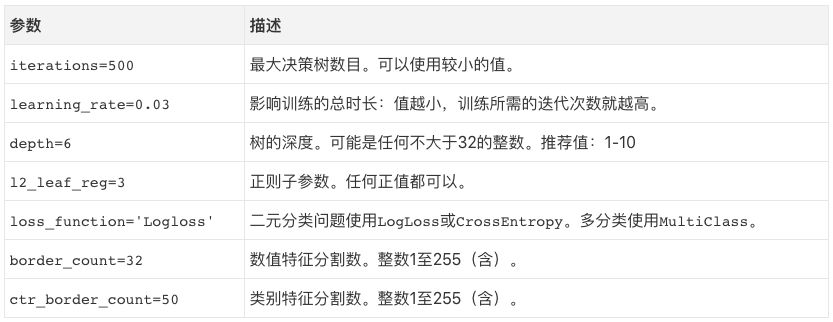
还有一些隐秘的选项,但使用以上这些参数效果已经很好了。
参数搜索
这一步骤通常叫做网格搜索,基本上就是寻找能取得最高分数的参数值。需要牢记的是我们不能用测试集来调优参数,否则我们会过拟合测试集。我们需要在训练集上做交叉验证(或者使用独立的验证集),直到最后的精确度计算阶段才能碰测试集。
这里我们不会做全网格搜索,因为所有参数组合的可能性实在太多了。我们将一小组参数一小组参数地做网格搜索,也就是局部搜索。
我们从默认的参数设定开始,因为它们已经相当不错了。首先我们独立优化ctr_border_count、border_count、l2_leaf_reg。我们将记住最佳的设定,然后我们将同时对iterations和learning_rate进行网格搜索,因为两者是紧密耦合的。最后,我们将查找最佳depth。因为我们并没有进行全网格搜索,我们可能不会得到最优设定,不过我们应该能得到相当接近最优设定的结果。
我编写了进行网格搜索的代码。开头部分基本和“快速示例”中的代码一样,读取数据集,转换类别特征为整数,并提取标签。
import pandas
import numpy as np
import catboost as cb
from sklearn.model_selection import KFold
from paramsearch import paramsearch
from itertools import product,chain
# 从csv文件读取训练数据和测试数据
colnames = ['age','wc','fnlwgt','ed','ednum','ms','occ','rel','race','sex','cgain','closs','hpw','nc','label']
train_set = pandas.read_csv("adult.data.txt",header=None,names=colnames,na_values='?')
test_set = pandas.read_csv("adult.test.txt",header=None,names=colnames,na_values='?',skiprows=[0])
# 转换类别栏为整数
category_cols = ['wc','ed','ms','occ','rel','race','sex','nc','label']
cat_dims = [train_set.columns.get_loc(i) for i in category_cols[:-1]]
for header in category_cols:
train_set[header] = train_set[header].astype('category').cat.codes
test_set[header] = test_set[header].astype('category').cat.codes
# 将标签从数据集中分离
train_label = train_set['label']
train_set = train_set.drop('label', axis=1)
test_label = test_set['label']
test_set = test_set.drop('label', axis=1)
然后是具体的参数搜索部分。我们首先指定将要进行网格搜索的参数,以及我们想要搜索的值。
params = {'depth':[3,1,2,6,4,5,7,8,9,10],
'iterations':[250,100,500,1000],
'learning_rate':[0.03,0.001,0.01,0.1,0.2,0.3],
'l2_leaf_reg':[3,1,5,10,100],
'border_count':[32,5,10,20,50,100,200],
'ctr_border_count':[50,5,10,20,100,200],
'thread_count':4}
然后我们定义进行交叉验证的函数——这一函数接受指定参数的集合,在训练数据集上进行n折验证,并返回每折的平均精确度。
# 这一函数基于catboostclassifier进行3折交叉验证
def crossvaltest(params,train_set,train_label,cat_dims,n_splits=3):
kf = KFold(n_splits=n_splits,shuffle=True)
res = []
for train_index, test_index in kf.split(train_set):
train = train_set.iloc[train_index,:]
test = train_set.iloc[test_index,:]
labels = train_label.ix[train_index]
test_labels = train_label.ix[test_index]
clf = cb.CatBoostClassifier(**params)
clf.fit(train, np.ravel(labels), cat_features=cat_dims)
res.append(np.mean(clf.predict(test)==np.ravel(test_labels)))
return np.mean(res)
下面是实际调用网格搜索函数的代码。我们使用itertools中的chain将多个迭代器组合为一个。我们首先搜索border_count,其他参数都保持默认值。接着我们使用之前找到的最佳参数搜索ctr_border_count。然后我们同时对iterations和learning_rate进行网格搜索(测试两者的所有可能组合)。在此之后我们找到最佳深度。一旦我们测试了所有组合后,我们直接使用最佳参数调用catBoostClassifier。
# 这一函数在一些参数上进行网格搜索
def catboost_param_tune(params,train_set,train_label,cat_dims=None,n_splits=3):
ps = paramsearch(params)
# 单独搜索'border_count'、'l2_leaf_reg'等参数,
# 但同时搜索'iterations'和'learning_rate'
for prms in chain(ps.grid_search(['border_count']),
ps.grid_search(['ctr_border_count']),
ps.grid_search(['l2_leaf_reg']),
ps.grid_search(['iterations','learning_rate']),
ps.grid_search(['depth'])):
res = crossvaltest(prms,train_set,train_label,cat_dims,n_splits)
# 保存交叉验证结果,这样以后的迭代可以复用最佳参数
ps.register_result(res,prms)
print(res,prms,s'best:',ps.bestscore(),ps.bestparam())
return ps.bestparam()
bestparams = catboost_param_tune(params,train_set,train_label,cat_dims)
现在我们使用找到的最佳参数调用CatBoost:
# 使用调优的参数训练分类器
clf = cb.CatBoostClassifier(**bestparams)
clf.fit(train_set, np.ravel(train_label), cat_features=cat_dims)
res = clf.predict(test_set)
print('error:',1-np.mean(res==np.ravel(test_label)))
调优参数后我们得到的最终分数实际上和调优之前一样!看起来我做的调优没能超越默认值。这体现了CatBoost分类器的质量,默认值是精心挑选的(至少就这一问题而言)。增加交叉验证的n_splits,通过多次运行分类器减少得到的噪声可能会有帮助,不过这样的话网格搜索的耗时会更长。如果你想要测试更多参数或不同的组合,那么上面的代码很容易修改。
预防过拟合
CatBoost提供了预防过拟合的良好设施。如果你把iterations设得很高,分类器会使用许多树创建最终的分类器,会有过拟合的风险。如果初始化的时候设置了use_best_model=True和eval_metric='Accuracy',接着设置eval_set(验证集),那么CatBoost不会使用所有迭代,它将返回在验证集上达到最佳精确度的迭代。这和神经网络的及早停止(early stopping)很像。如果你碰到过拟合问题,试一下这个会是个好主意。不过我没能在这一数据集上看到任何改善,大概是因为有这么多训练数据点,很难过拟合。
CatBoost集成
集成指组合某种基础分类器的多个实例(或不同类型的分类器)为一个分类器。在CatBoost中,这意味着多次运行CatBoostClassify(比如10次),然后选择10个分类器中最常见的预测作为最终分类标签。一般而言,组成集成的每个分类器需要有一些差异——每个分类器犯的错不相关时我们能得到最好的结果,也就是说,分类器尽可能地不一样。
使用不同参数的CatBoost能给我们带来一些多样性。在网格搜索过程中,我们保存了我们测试的所有参数,以及相应的分数,这意味着,得到最佳的10个参数组合是一件轻而易举的事情。一旦我们具备了10个最佳参数组合,我们直接构建分类器集成,并选取结果的众数作为结果。对这一具体问题而言,我发现组合10个糟糕的参数设定,能够改善原本糟糕的结果,但集成看起来在调优过的设定上起不了多少作用。不过,由于大多数kaggle竞赛的冠军使用集成,一般而言,使用集成明显会有好处。
原文地址:https://effectiveml.com/using-grid-search-to-optimise-catboost-parameters.html