ECCV 2020 | CV “造车”,生成内容一致的车辆数据集 |
点击上方“计算机视觉life”,选择“星标”
快速获得最新干货
本文转自我爱计算机视觉,粉丝YorkeYao投稿,转载自知乎。
链接:https://zhuanlan.zhihu.com/p/198061566
本文介绍一篇我们发表于ECCV 2020的论文 《Simulating Content Consistent Vehicle Datasets with Attribute Descent》 。这篇文章主要介绍了澳大利亚国立大学和英伟达推出的VehicleX数据集,是目前用于车辆重识别(vehicle re-ID)中最大的合成数据集,为CVPR 2020 aicity challenge 提供了源数据。VehicleX的3D模型,生成的图片,引擎及其源代码均已开源。
数据在深度学习的时代越来越被重视,但是一直以来如何获取大量的数据是一个难题,数据的隐私安全和标注的复杂性是问题的重点。在这个问题上,合成数据有先天的优势。首先合成数据不涉及具体某个人物的信息,因此不会有隐私的问题。其次,合成数据自带标注,所以不存在人工标注的问题。
但是,一直以来,合成数据的使用存在着瓶颈。合成数据是人工合成的。换句话说,整个合成数据的环境都需要人去决定。这虽然为合成数据提供了很大的自由度,但如果生成合成数据的方式不合理,合成数据的质量会和我们期望的差距甚远。
所以,评价一个合成数据合适不合适,首先要看这个数据集和我们的目标数据集是不是‘看起来’相似。

这种让数据集‘看起来’相似的任务,被叫做领域适应(domain adaptation)。上图是两个domain adaptation的示例。第1行显示具有不同前景和背景的数字分类数据集。第2行是人群计数数据集,左边是合成数据,右边是真实数据集。在这两种情况下,源域和目标域之间的domain gap都很大。所以在这种情况下,在源域上训练的模型可能在目标域上表现不佳。

许多研究都集中在通过图像风格迁移(例如纹理,照明和分辨率等)来弥合domain gap。在这里,我们展示了一些风格迁移的例子。第一排是从GTA5数据集的风格到cityscape的风格,第二排是从VehicleX数据集的风格到VeRi数据集的风格。
我们可以看到这些方法会稍微改变图像(如纹理,光线强度等),但是这些方法无法改变内容上的差异,例如在第一排的例子中建筑物的密度,遮挡的程度和第二排例子中车辆的方向。
在本文中,我们主要研究车辆re-ID的任务。所以,我们现在抽象出来的研究问题就是,当我们把合成数据作为源域,真实数据集作为目标域的时候,如何弥补这种领域差距?
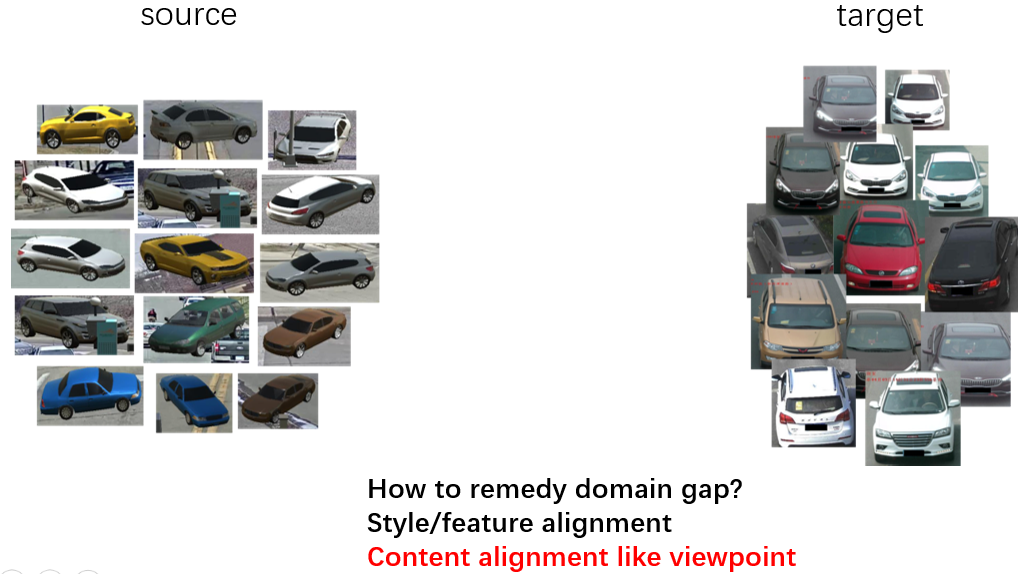
例如,图片右侧是VehicleID数据集中的图片,左侧是随机初始化的合成数据集。除了合成数据和目标数据的图片风格不一样之外,在VehicleID数据集中,很清楚的能够看到车辆的朝向和相机的位置都是固定的,在这个摄像头视角下,我们只能看到车头和车尾。
那么,如果我们希望一个深度学习模型,能够在VehicleID数据集上表现的好的话,那么这个模型的训练数据,应该也主要包括车头和车尾。换句话说,合成数据集和我们的目标数据集,在车辆的朝向上,应该有相似的分布。

所以我们主要去研究内容层面上的domain gap(content level domain adaptation)。在vehicle re-ID任务中,内容被定义为车辆朝向,相机高度,光照强度等。因为这些内容因素会对re-ID模型的性能造成很大影响。

我们提出了一个大型的3D合成数据集VehicleX。其中各个3D模型都有现实世界的车型对应。整个数据集有1362个id,其中包括11种主流车型。上图显示了16种不同的车辆id。
同时,我们也为VehicleX制作了一个demo。这个demo中随机挑选了1362id中的69个id。同时对于VehicleX,我们详细标注了车辆的车型和颜色。我们也放出了这些车辆的3D模型,可以导入到unity,unreal和blender中。

为了实现content level domain adaptation,我们构建了Unity-Python的交互接口,这个接口能让我们我们对3D环境进行修改,并获取渲染的图像。
在3D环境中,我们能够调整车辆方向,光线方向和强度,相机高度以及相机与车辆之间的距离。同时我们也为合成数据添加了随机的真实背景和遮挡物。
实际操作中,我们使用高斯或高斯混合模型对属性分布进行建模,并且提出了一种叫做attribute descent的方法来近似现实数据集中的属性分布。工作流程如下所示。
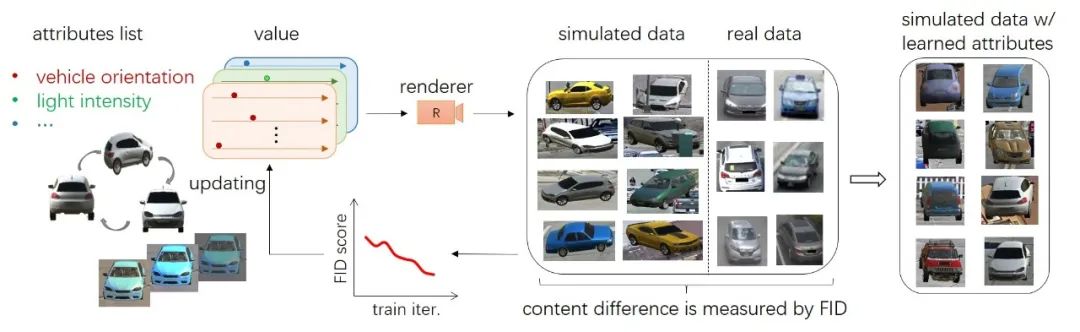
给定一个属性列表(角度,相机,光照),我们使用渲染器进行车辆3D渲染。然后,我们计算合成数据和实际车辆之间的Frechet inception distance (FID),FID是一个通用的domain gap的衡量指标,最早被用在gan生成图片质量的衡量。
attribute descent是一个简单有效的算法来迭代更新这些属性值,从而在训练迭代中使FID最小化。具体来说,我们逐一操纵VehicleX中的每个属性,旨在最大程度地减少VehicleX与真实数据之间存在的domain gap。
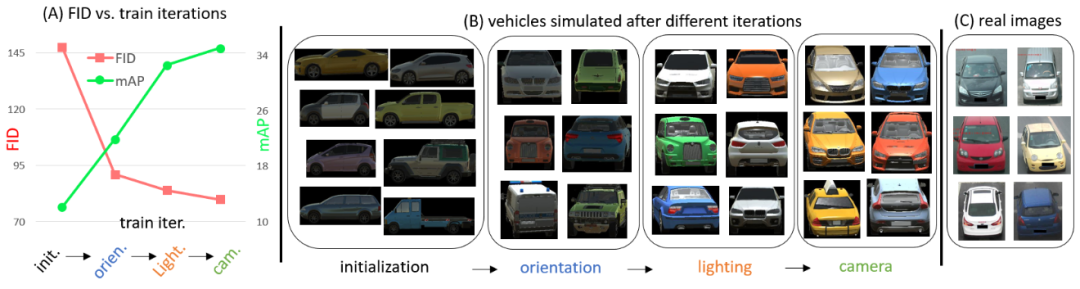
从左图可以看出,在attribute descent训练过程中,FID不断下降,同时unsupervised re-ID(VehicleX->VehicleID)的准确率(mAP)不断提高。同时,如上图右侧,VechileX的数据(b)和VehicleID的(c)数据在外观上越来越相近。

同时,VehicleX的数据也可与现实数据集联合训练以提高现实数据的性能,在上表中,VechileX和cityflow数据集混合训练,和只用cityflow数据集训练相比,在mAP上提升了6.95个点。使用attribute descent方法,和random attribute相比,在mAP上提升了1.2个点。
总结来说,合成数据在这些年越来越被重视,但是合成数据和现实数据之间的domain gap约束合成数据的发展。这篇文章从内容适应的角度出发,提出了一个新的合成数据集VehicleX。目前,vehicleX的3D模型和生成的图片,引擎及其源代码,均已开源。欢迎大家提出宝贵意见。
END
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~
投稿、合作也欢迎联系:simiter@126.com

扫描关注视频号,看最新技术落地及开源方案视频秀 ↓



