CVPR 2019 | 图像压缩重建也能抵御对抗样本
点“计算机视觉life”关注,置顶更快接收消息!
本文授权自机器之心
近日,微软亚洲研究院在清华举办了 CVPR 2019 论文分享会。20 余位论文作者在分享会现场进行了报告宣讲,30 多篇论文进行了海报展示与交流。在这篇文章中,我们将介绍其中一篇关于对抗样本的海报展示论文,该论文表示我们可以重构对抗样本而去除掉对抗信息,从而令它不会对分类模型产生危害。
什么是对抗样本
对抗样本是指攻击者通过向真实样本中添加人眼不可见的噪声,导致深度学习模型发生预测错误的样本,如下图所示给定一张熊猫的图像,攻击方给图片添加了微小的噪声扰乱,尽管人眼是很难区分的,但是模型却以非常高的概率将其误分类为长臂猿。
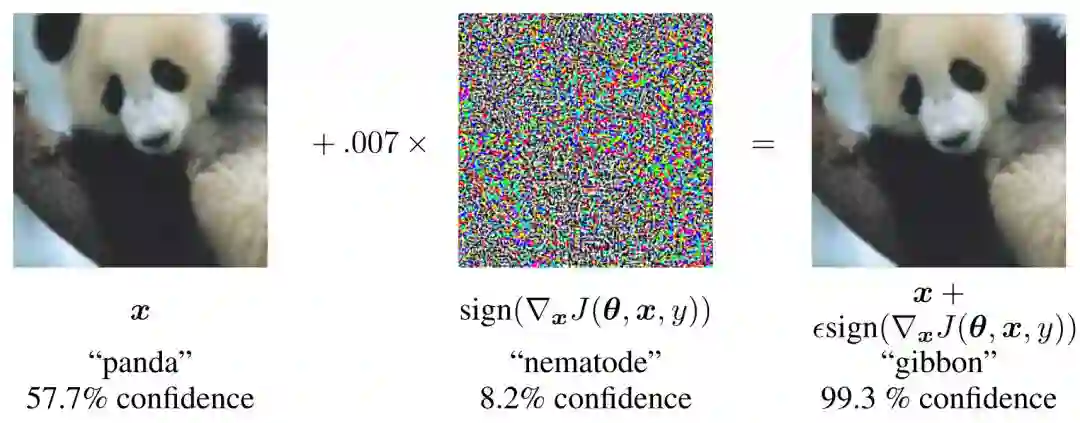
上图为 Ian Goodfellow 在 14 年展示的对抗样本,这种对抗样本是通过一种名为 FGSM 的算法得出。
一般而言,对抗攻击可以分为白盒攻击、黑盒攻击、定向攻击,以及通用攻击。其中白盒攻击是指攻击者能完全访问到被攻击模型,也就是说攻击者在知道模型架构和参数的情况下制造能欺骗它的对抗样本。而黑盒攻击则表明攻击者只能观察到被攻击模型的输入与输出,例如通过 API 攻击机器学习模型可以视为一个黑盒攻击,因为攻击者只能通过观察输入输出对来构造对抗样本。
近年来,人们已经提出了许多抵御对抗样本的方法。这些方法大致可分为两类。第一类是增强神经网络本身的鲁棒性。对抗训练是其中的一种典型方法,它将对抗样本放入训练数据中以重新训练网络。标签平滑将 one-hot 标签转换为软目标也属于此类。
第二类是各种预处理方法。例如 Song 等人(arXiv:1710.10766)提出的 PixelDefend,它可以在将对抗图像输入分类器之前,将其转换为清晰的图像。类似地,也有研究者(arXiv:1712.02976)将察觉不到的扰动视为噪声,并设计了高阶表征引导去噪器(HGD)来消除这些噪声。HGD 在 NIPS 2017 对抗样本攻防竞赛中获得第一名。
一般而言,后一种方法更有效,因为它们不需要重新训练神经网络。然而,在训练降噪器时,HGD 仍然需要大量的对抗图像。因此,在对抗图像较少的情况下很难获得良好的 HGD。PixelDefend 的主要思想是模拟图像空间的分布,当空间太大时,模拟结果会很差。
新的防御方案
从另一个方向而言,图像压缩是一种低阶的图像变换任务。由于局部结构中相邻像素之间具有很强的相似性和相关性,因此图像压缩可以在保留显著信息的同时减少图像的冗余信息。在此基础上,这篇论文的研究者设计了 ComDefend,它利用图像压缩来消除对抗扰动或打破对抗扰动的结构。ComDefend 的基本思想如图 1 所示:
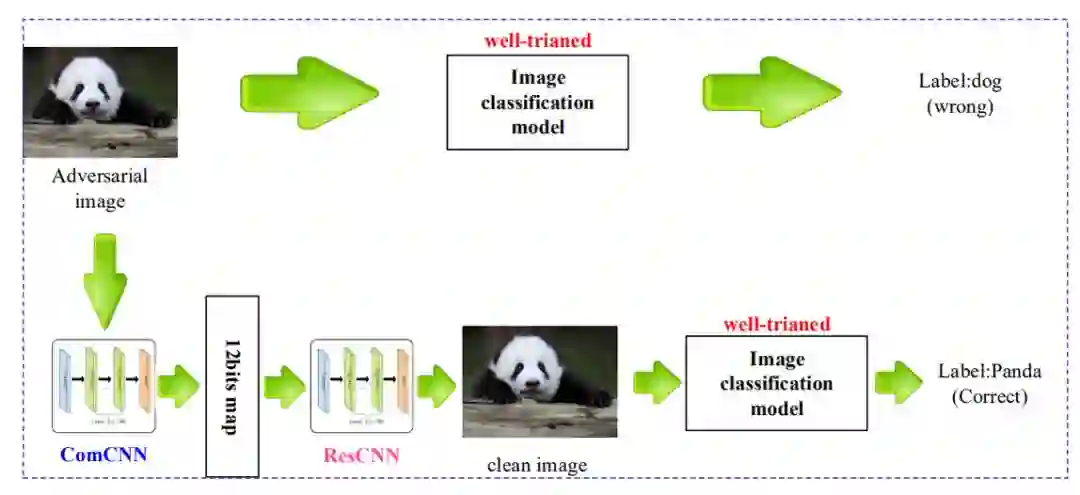
图 1:抵御对抗样本的端到端图像压缩模型主要思想。对抗图像和原始图像之间的扰动非常小,但是在图像分类模型的高层表示空间,扰动被放大。研究者使用 ComCNN 去除去除对抗性图像的冗余信息,再用 ResCNN 来重建清晰的图像,这样就抑制了对抗扰动的影响。
ComDefend 由两个 CNN 模块组成。第一个 CNN,称为压缩 CNN(ComCNN),用于将输入图像转换为压缩表示。具体是指将原始的 24 位像素压缩为 12 位。从输入图像提取的压缩表示可以保留足够的原始图像主体信息。第二个 CNN,称为重建 CNN(ResCNN),用于重建高质量的原始图像。ComCNN 和 ResCNN 最终组合成一个统一的端到端框架,并联合学习它们的权重。
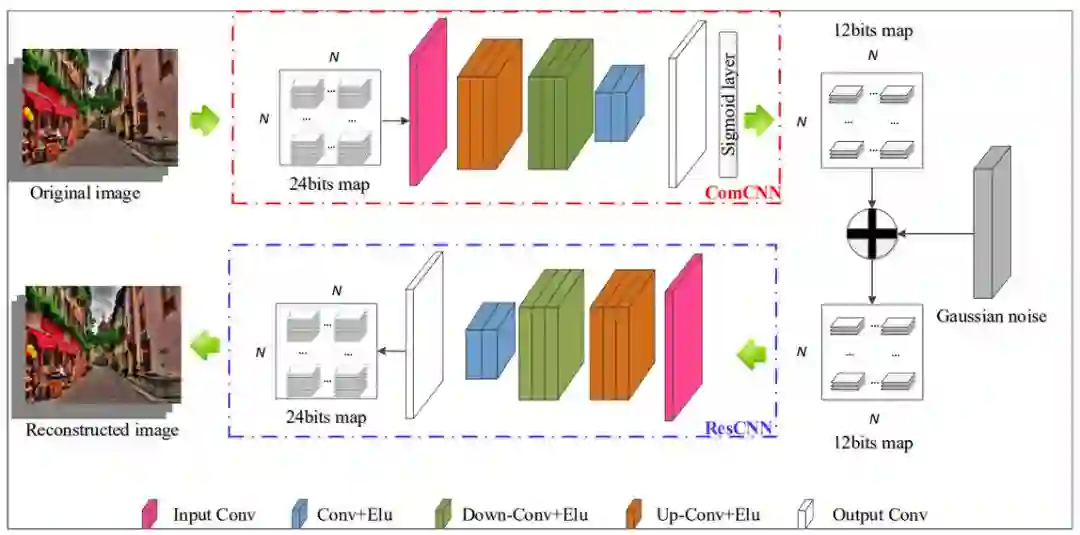
图 2:ComDefend 概览图。
ComCNN 用于保存原始图像的主要结构信息,RGB 三个通道的原始 24 位图被压缩为 12 位图(每个通道分配 4 位)。ResCNN 负责重建清晰的原始图像,它会在压缩表示上增加了高斯噪声,以提高重建质量,并进一步增强抵御对抗样本的能力。
我们可以发现 ComDefend 是针对清晰图像进行训练的,网络将学习清晰图像的分布,从而可以从对抗图像中重建清晰的图像。与 HGD 和 PixelDefend 相比,ComDefend 在训练阶段不需要对抗样本,因此降低了计算成本。另外,ComDefend 采用逐块的方式对图像处理,而不是直接对整幅图处理,这提高了处理效率。
综上所述,这篇论文主要有以下贡献:
提出了 ComDefend,一种端到端的图像压缩模型来抵御对抗样本。
设计了一个统一的学习算法,以同时学习 ComDefend 中两个 CNN 模块的权重。
该方法极大地提高了模型对各种攻击方法的抵抗力,并击败了目前最先进的防御模型,包括 NIPS 2017 对抗样本攻防竞赛的冠军。
论文:ComDefend: An Efficient Image Compression Model to Defend Adversarial Examples

论文地址:https://arxiv.org/abs/1811.12673
实现地址:https://github.com/jiaxiaojunQAQ/Comdefend
深度神经网络(DNN)在对抗样本中容易受到影响。即在清晰图像中添加难以察觉的扰动可能会欺骗训练好的深度神经网络。在本论文中,我们提出了一种端到端的图像压缩模型 ComDefend 来抵御对抗样本。该模型由压缩卷积神经网络(ComCNN)和重建卷积神经网络(ResCNN)组成。
ComCNN 用于维护原始图像的结构信息并去除对抗扰动,ResCNN 用于重建高质量的原始图像。换句话说,ComDefend 可以将对抗样本转换为「干净」的图像,然后将其输入训练好的分类器。我们的方法是一个预处理模块,并不会在整个过程中修改分类器的结构。因此,它可以与其他特定模型的抵御方法相结合,共同提高分类器的鲁棒性。在 MNIST、CIFAR10 和 ImageNet 上进行的一系列实验表明,我们所提出的方法优于目前最先进的抵御方法,并且一致有效地保护分类器免受对抗攻击。
端到端图像压缩模型
在以前的相关研究中,我们可以将难以察觉的扰动视为具有特定结构的噪声。换句话说,扰动不会影响原始图像的结构信息,这种难以察觉的扰动可以被认为是图像的冗余信息。从这个角度来看,我们可以利用图像压缩模型中的图像冗余信息,进而依赖这些信息的特征抵御对抗样本。
为了消除不易察觉的扰动或打破扰动的特定结构,我们提出了端到端图像压缩模型。如图 2 所示,图像压缩模型包含压缩和重建过程。
在压缩过程中,ComCNN 提取图像结构信息,并删除图像的冗余信息。在重建过程中,ResCNN 重建输入图像而不产生对抗扰动。具体而言,ComCNN 将 24 位像素图像压缩为 12 位,即 12 位像素图像去除原始图像的冗余信息。随后,ResCNN 使用 12 位像素图像来重建原始图像。
在整个过程中,我们希望从原始安全图像中提取的 12 位像素图像尽可能与对抗样本相同。因此,我们可以将对抗样本转换为安全的图像。如图 3 所示,我们可以看到添加随机高斯噪声有助于提高压缩模型的性能。

图 3:ComDefend 中是否添加高斯噪声的结果比较。在每个子图中,顶部图像是原始图像,中间图像是压缩的 12 位图,底部是重建图像。(a)ComDefend 通过非二值化的 12 位图重建图像。(b) 在没有高斯噪声的情况下,ComDefend 通过二值化的 12 位图重建图像。(c) 利用高斯噪声,ComDefend 通过二值化 12 位图重建图像。
我们看到 (c) 中的重建质量与 (a) 中的重建质量相同,这意味着非二值化映射的增量信息实际上是噪声。因此,当在二值化映射上添加高斯噪声时,可以重建出更好的图像。
4. 实验结果和分析
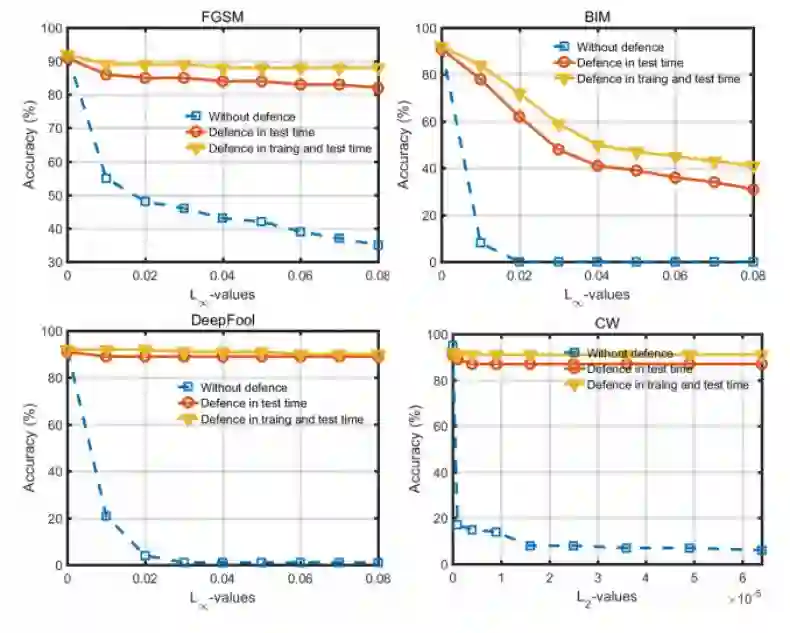
图 4:ResNet-50 对对抗样本的分类准确度,这四种攻击会分别在测试、训练和测试阶段进行防御。虚线表示 ResNet-50 模型在没有任何防御下对对抗性图像的分类准确性。
Cifar-10 图像数据集的比较结果如表 4 所示。
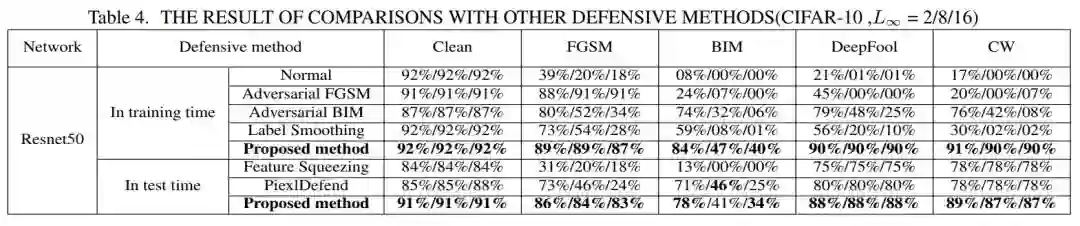
如表 6 所示,该方法提高了 FGSM、DeepFool 和 CW 攻击方法的防御性能。

推荐阅读

觉得有用,给个好看啦~



