SIGIR是人工智能领域智能信息检索方向最权威的国际会议。最新组委会公布了一系列最佳论文。其中来自荷兰Radboud大学-Harrie Oosterhuis独自署名的论文获得最佳论文,山东大学聂礼强组获得最佳学生论文。
第45届国际信息检索大会(The 45th International ACM SIGIR Conference on Research and Development in Information Retrieval)将于2022年7月11日-7月15日在西班牙马德里召开。SIGIR是中国计算机学会CCF推荐的A类、清华推荐论文列表TH-CPL-A类国际学术会议,在相关领域享有较高学术声誉。这次会议共收到794篇长文投稿,仅有161篇长文被录用,录用率约20%。

最佳论文

A Non-Factoid Question-Answering Taxonomy
Valeriia Bolotova , Vladislav Blinov , Falk Scholer , W. Bruce Croft , Mark Sanderson Authors Info & Claims
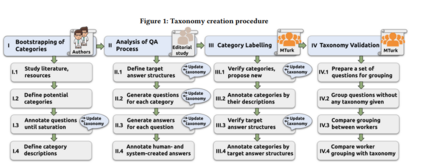
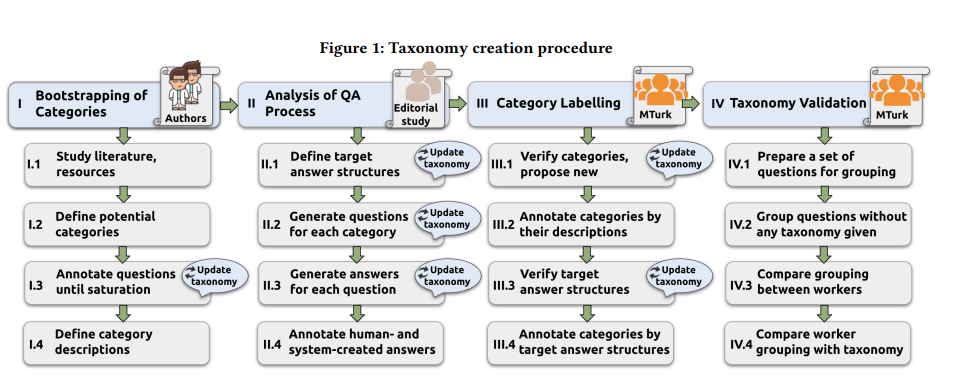
非事实陈述问题回答(NFQA)是一项具有挑战性和研究不足的任务,它需要对开放式的非事实陈述问题(NFQs)构建长形式的答案,如解释或观点。对于人们倾向于问的NFQs的类别,他们希望看到的答案形式,以及每个类别的关键研究挑战是什么,我们仍然知之甚少。
这项工作提出了NFQ类别的第一个全面分类和答案的预期结构。该分类法是用透明的方法构建的,并通过众包进行了广泛的评估。最具挑战性的类别是通过编辑用户研究确定的。我们还发布了一个分类NFQ的数据集和一个问题类别分类器。
最后,我们使用主要的NFQA数据集对问题类别的分布进行了定量分析,结果显示,当前NFQA系统中最具挑战性的NFQ类别在这些数据集中表现得很差。这种不平衡可能会导致挑战性类别的系统性能不足。新的分类法和分类器将有助于该领域的研究,帮助创建更平衡的基准,并将模型集中在处理特定类别上。
最佳短论文


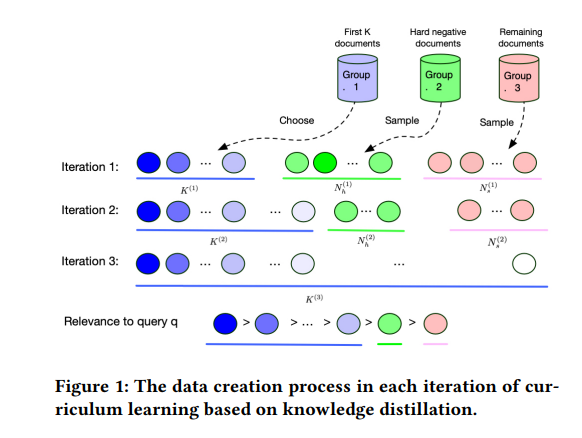
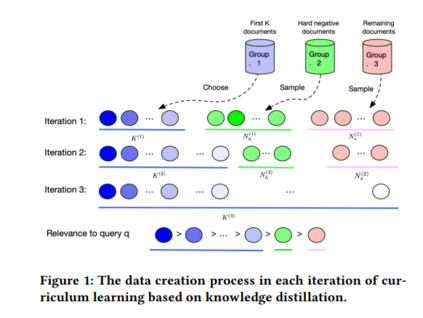
最近的研究表明,通过从已有的知识库重新排序模型中提取排序知识,可以获得更有效的密集检索模型。在本文中,我们提出了一个通用的基于课程学习的优化框架CL-DRD,该框架控制由重新排名(教师)模型产生的训练数据的难度水平。CL-DRD通过增加知识提取数据的难度迭代优化密集检索(学生)模型。更详细地说,我们最初在教师排序的文档之间提供学生模型粗粒度偏好对,并逐步转向更细粒度的成对文档排序需求。在我们的实验中,我们应用了CL-DRD框架的一个简单实现来增强两个最先进的密集检索模型。在三个公共通道检索数据集上的实验证明了我们提出的框架的有效性。