斯坦福博士提出超快省显存Attention,GPT-2训练速度提升3.5倍,BERT速度创纪录
白交 发自 凹非寺
量子位 | 公众号 QbitAI
Flash is all you need!

最近,一个超快且省内存的注意力算法FlashAttention火了。
通过感知显存读取/写入,FlashAttention的运行速度比PyTorch标准Attention快了2-4倍,所需内存也仅是其5%-20%。
而它的表现还不止于此。
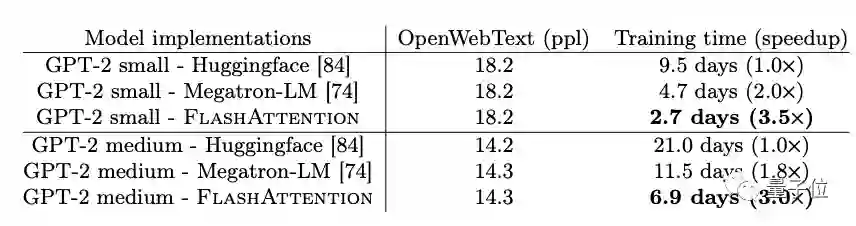
训练BERT速度相较于MLPerf训练记录提升15%;
训练GPT-2的速度提高3.5倍;
训练Transformer的速度比现有基线快。
网友们纷纷表示惊叹:Great Job!这项工作对我来说很有用。

来看看这是一项什么样的研究~
FlashAttention
本文提出了一种IO感知精确注意力算法。
随着Transformer变得越来越大、越来越深,但它在长序列上仍然处理的很慢、且耗费内存。(自注意力时间和显存复杂度与序列长度成二次方)
现有近似注意力方法,在试图通过去牺牲模型质量,以降低计算复杂度来解决该问题。
但存在一定的局限性,即不能提升运行时的训练速度。
研究者认为,应该让注意力算法具有IO感知,即考虑显存级间的读写,比如大但慢的HBM(High Bandwidth Memory)技术与小但快的SRAM。
基于这样的背景,研究人员提出了FlashAttention,具体有两种加速技术:按块递增计算即平铺、并在后向传递中重新计算注意力,将所有注意力操作融合到CUDA内核中。

FlashAttention使用平铺来防止大的𝑁×𝑁注意力矩阵(虚线框)在GPU HBM上物化(materialization)。在外部循环中(红色箭头),FlashAttention循环通过K和V矩阵的块,并将其加载到SRAM。
在每个区块中,FlashAttention 循环Q矩阵的区块(蓝色箭头)将其加载到 SRAM,并将注意力计算的输出写回 HBM。
这样就产生了一种注意力算法,在实际耗时(wall-clock time)内,其内存效率和速度都很高,相比于标准的注意力算法可以更少地访问HBM。

结果比现有注意力算法都快
研究人员评估了FlashAttention来训练Transformer的影响,包括训练时间、模型准确性,以及注意力运行时间和内存效率。
首先在训练速度上。FlashAttention比MLPerf 1.1的BERT速度记录高出15%。

在实现GPT-2上,比HuggingFace速度高出3倍,比Megatron的标准Transformer速度高出1.8倍,FlashAttention将LRA(long-range arena)的基准速度提高了2.4倍。
在模型质量,FlashAttention将Transformer扩展到更长的序列,并且质量更好。
长上下文的语言建模。
如图所示,使用FlashAttention可以让GPT-2上下文长度增加4倍的情况下,训练时间还比Megatron-LM优化实现快30%,同时也获得了0.7的困惑度(困惑度越低,说明语言模型越好)。

长文档分类
对较长序列的Transformer训练可以提高MIMIC-III和ECtHR数据集的性能,比如序列长度为16K在MIMIC上比长度512多出4.3分。
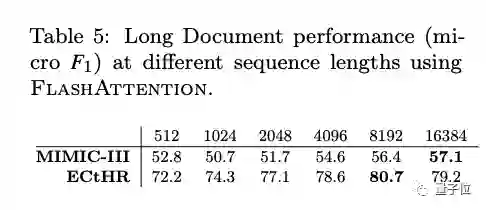
MIMIC-III:包含重症监护室病人的出院总结,每个都有多个标签注释;ECtHR:包含欧洲人权法案的法律案件;两个数据集都包含很长的文本文件。
此外,还完成了第一个能在Path-X和Path-256任务中实现非随机性能的Transformer模型。

之后,研究人员还完成了基准测试,测量FlashAttention和块状稀疏(Block-Sparse)FlashAttention的运行时间和内存性能,并与带有40GB HBM的A100 GPU上的各种注意力基线进行了比较。

结果显示,FlashAttention的运行时间,比PyTorch注意力实现快3倍;在短序列情况下,FlashAttention在短序列中仍比近似和稀疏注意力运行得快;至于块状稀疏的FlashAttention,在所有的序列长度上都比现有注意力实现都快。
至于在显存效率方面,FlashAttention比PyTorch注意力基线高20倍。
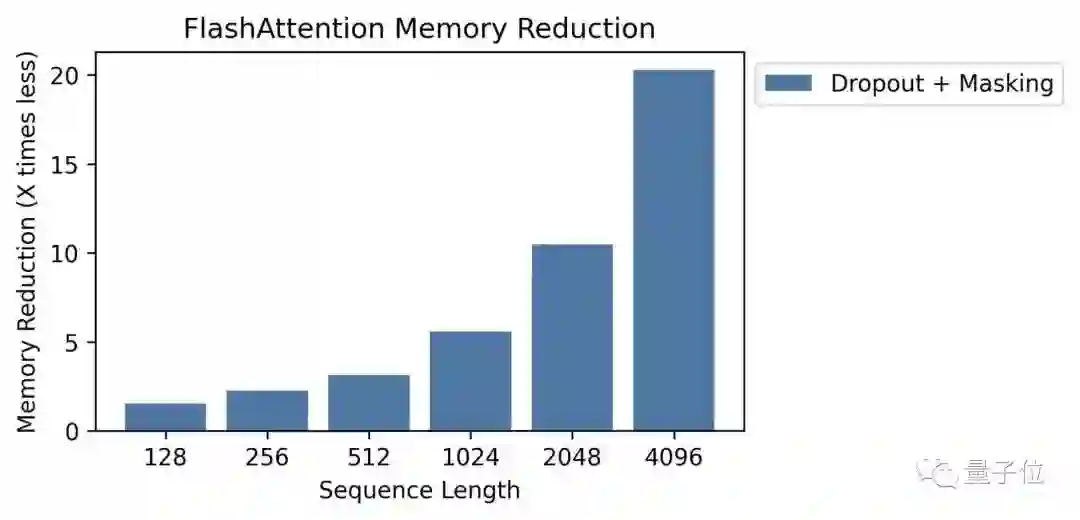
在64k序列长度、其他所有算法都已经耗尽显存的情况下,FlashAttention的效率仍比Linformer高2倍。
斯坦福博士一作

这篇研究来自斯坦福大学计算机系以及纽约州立大学布法罗分校。共同一作是两位斯坦福计算机博士生Tri Dao和Dan Fu。

感兴趣的朋友,可戳下方论文链接了解更多~
论文链接:
https://arxiv.org/abs/2205.14135
GitHub链接:
https://github.com/HazyResearch/flash-attention
参考链接:
https://twitter.com/tri_dao/status/1531437619791290369
— 完 —
直播报名 | 自动驾驶的量产之路:
为什么“渐进式”路径先看到了无人驾驶量产的曙光?
自动驾驶领域一直以来就有“渐进式”和“跨越式”两种路径之争,前者以特斯拉为代表,后者以Waymo为领头羊。
特斯拉宣布2024年实现新型“Robotaxi”的量产,而另一边是Waymo CEO离职,商业化落地裹足不前。在此背后,为什么“渐进式”路径被越来越多的机构看好?“渐进式”技术发展路径是什么?自动驾驶量产离我们的生活还有多远?

点这里👇关注我,记得标星哦~
一键三连「分享」、「点赞」和「在看」
科技前沿进展日日相见~

