面向Transformer模型的高效预训练方法
声明:本文转载自 哈工大讯飞联合实验室 公众号. 原创作者 韦菁
本期导读:自从BERT出现以来,预训练技术逐渐发展成为了 NLP 领域不可或缺的主流技术。这给我们处理NLP任务带来了极大的便利,但是优秀的预训练模型背后需要极大的算力成本,因此如何高效地训练Transformer模型也成为了人们关注的一个重点。本期结合预训练策略研究的一篇最新工作对模型策略微调与模型性能、训练效率的关系展开说明。
1 引言
基于Transformer的神经网络架构,例如BERT, RoBERTa等著名模型对自然语言处理领域产生了极大的影响,在各种任务上它们的优越性能使其迅速成为标杆。然而这些模型的计算成本极高,通常需要昂贵的硬件和漫长的时间进行预训练。因此,人们也开始关注如何降低预训练模型的训练成本。例如,ELECTRA模型采用判别器/生成器的方式避免了训练过程中[MASK]标记的出现,避免了预训练/精调的不一致性,同时提高训练数据的利用率,从而提升预训练效率。
EFFICIENT PRE-TRAINING OBJECTIVES FOR TRANSFORMERS
受ELECTRA的启发,该篇论文在Masked Language Modeling(MLM)和token detection(TD)的基础上针对预训练目标的设置进行改进,提出了多种新颖的预训练策略。作者选择在RoBERTa和ELECTRA模型用相同的超参数进行训练并在四个自然语言推理基准数据集:GLUE、SQUAD、ASNQ-R和WikiQA中测试它们,验证所提策略的有效性。
2 预训练策略
2.1 Random Token Substitution (RTS)
对于输入的文本被分词后得到的词条标记(token),此方法将在输入中随机替换标记,训练一个判别器学习区分原始标记和被替换的标记,此方法类似于ELECTRA判别器的训练方式,两者的区别是,RTS随机选择输入中15%的标记进行替换,替换词来源于模型词汇表。本文中将RTS应用于RoBERTa模型,后续记为RoBERTa-RTS。
2.2 RTS with aggregated probabilities (C-RTS)
此方法中引入了后验错误分类概率来选择被替换标记,针对 和 两个标记:
其中P是指在 被替换为 的情况下,判别器在分类时出现错误的概率。P可以通过计算之前迭代中每对 的失败/成功次数比例得出。此方法下与ELECTRA生成器的主要区别在于上下文。ELECTRA利用整个输入句子来创建替换词,而此方法只使用单个标记的预测历史,并且只依赖于模型对它过去的预测。
鉴于RoBERTa模型的词汇量多达50K,按照上述方法则会产生大量的 条目,而且极为稀疏,将难以计算准确的P。因此,作者将用于预训练的相同数据先在word2vec模型上训练获得相应的词向量后,计算各个向量之间的欧式距离,然后利用K-Means模型将所有标记划分出n个簇 。
实现上,首先初始化一个矩阵 为0,它将保存判别器对每个簇对的判别失败与成功次数之差。例如在训练过程中,一些标记被随机篡改,对于一对标记 ,假设 被替换为 ,如果模型正确判别α被替换, 则减1,反之加1。训练中,对各个聚类的抽样采用均匀分布,则P可以近似估计为:
其中 可以从计数矩阵F中计算得到。对于每个标记 ,可以通过对 行进行索引,在 上定义一个多叉分布。为了得到一个可以被解释为概率的值的向量,应用min-max归一化:
从而得到:
其中 系数用于控制集中或分布在最有可能的簇上。以上方法概括地说,作者首先随机选择输入句子中的一些标记,并在给可知标记 所属簇的情况下,对目标簇( 所在簇)定义一个多项式分布,最后从目标簇中以均匀分布的概率选择标记用作替换词。作者经过初步实验发现最佳组合是 =2。本文将C-RTS应用于RoBERTa,后续记为RoBERTa-C-RTS。
2.3 Swapped Language Model (SLM)
此方法类似于MLM,输入的标记将被随机替换,但不会被替换成特殊的[MASK]标记。与RTS不同的是,此方法中模型将被训练预测替换前的原始标记,而不是判别某个标记是否被替换。本文将SLM应用于RoBERTa,后续记为RoBERTa-SLM。
2.4 SLM-all
由于SLM方法并没有对标记是否被替换进行判别,它只适用于被修改的标记对应的输出位置,此时损失函数不能直接反馈训练ELECTRA模型。为此文章设置了额外的条件,判别器必须预测整个输入句子,判别哪些标记被改变并预测它们的原始值。同时,对于未被修改的输入,它应该在输出中重现输入。本文将SLM-all应用于ELECTRA,后续记为ELECTRA-SLM-all。
| 策略 | MLM | RTS | SLM | SLM-all |
|---|---|---|---|---|
| 替换方式 | 随机15%(80%[mask],10%随机token,10%原始token) | 随机15%,替换为随机token | 随机替换,没有[mask]标记 | 随机替换,没有[mask]标记 |
| 预测目标 | [Mask]处token | 是否被替换 | 原始token | 是否被替换+原始token |
3 实验
3.1模型设置
为了保证实验公平进行,采取控制变量的方式设置模型结构参数:
| Model | RoBERTa-base model | ELECTRA |
|---|---|---|
| Transformer layers | 12 | 12 |
| hidden size | 768 | 256 |
| attention heads | 12 | 4 |
| intermediate size | 3072 | 1024 |
| parameters | 125M | 142M |
由于预训练的时间与参数的数量不成正比,采用进行预训练所需的浮点运算(FLOPs)的数量作为指标。FLOPs测量的是在整个预训练阶段硬件上形成的数学运算的数量,因此这个数字与使用GPU或TPU和模型的大小无关。预训练过程中,作者在英文维基百科和BookCorpus数据集上对每个模型进行了900K步的预训练,学习率为 ,优化器采用Adam,参数如下: 。

上图表明了用来预训练每个模型的FLOPS。ELECTRA和ELECTRA-SLM-all之间的巨大差距是由于ELECTRA模型只在鉴别器上使用了一个小的二进制分类头,而ELECTRA增强了SLM,它对每个输入都进行了标记预测。
3.2 微调实验
3.2.1 General Language Understanding Evaluation (GLUE)
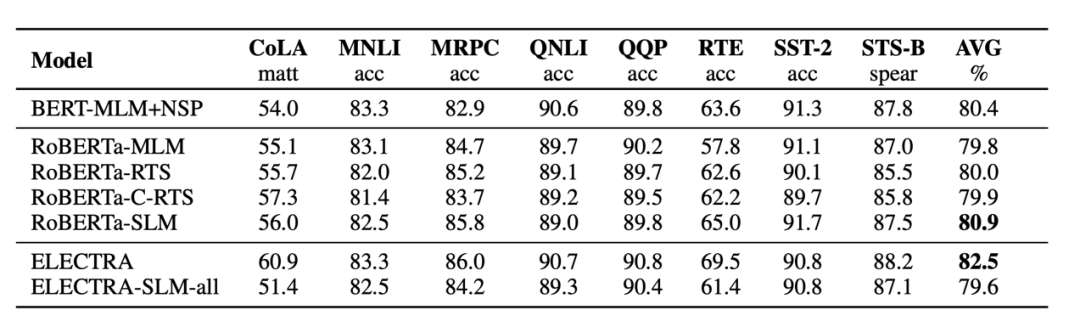
GLUE涵盖了九个不同的自然语言理解基准任务,下表是本文模型在各个任务上的实验结果:
Development sets
Test sets
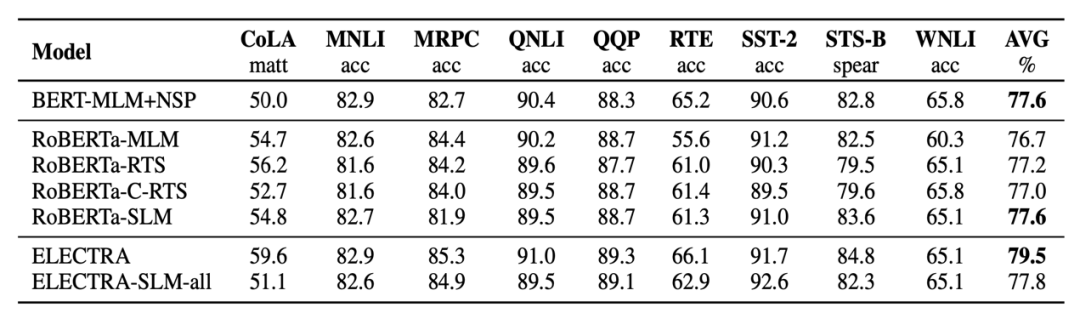
如图结果表明,除了原始ELECTRA之外,所有考虑的方法都获得可观的性能。值得注意的是,基于RTS和C-RTS的RoBERTa模型在测试集上获得了比MLM更多的改进,同时只需要较少的计算量来进行预训练。在QQP和MNLI上,ELECTRA和ELECTRA-SLM-all之间的性能差异不太明显。然而ELECTRA只但在CoLA、RTE和STS-B上都大幅超过作者所提出的模型。
3.2.2 问答类实验
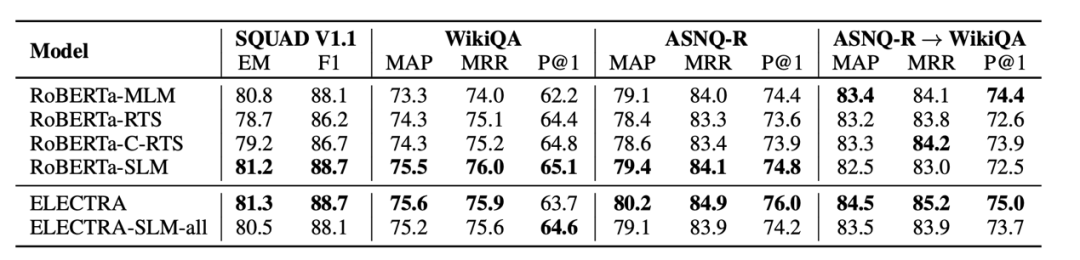
问答实验中共使用了3个不同的数据集:1.SQuAD是一个由人工创造的问题以及从维基百科中提取的可能有问题答案的相关文章段落的数据集。2. ASNQ-Reduced,这是使用自然问题语料库建立的问答数据集,自然问题包含了向谷歌搜索引擎提出的问题和相应的维基百科页面,这些页面几乎已经包含答案。3. WikiQA,该数据集由向微软必应搜索引擎提出的问题建立,问题与来自维基百科文章的答案进行了人工配对,并将其标记为相关或不相关。此外还设置了迁移学习实验测试模型的泛化能力。作者利用ASNQ-R数据集来对模型进行训练,之后在WikiQA上进行微调和测试其中转移和微调的超参数与分别用于微调ASNQ-R和WikiQA的参数相同。
Development sets
Test sets
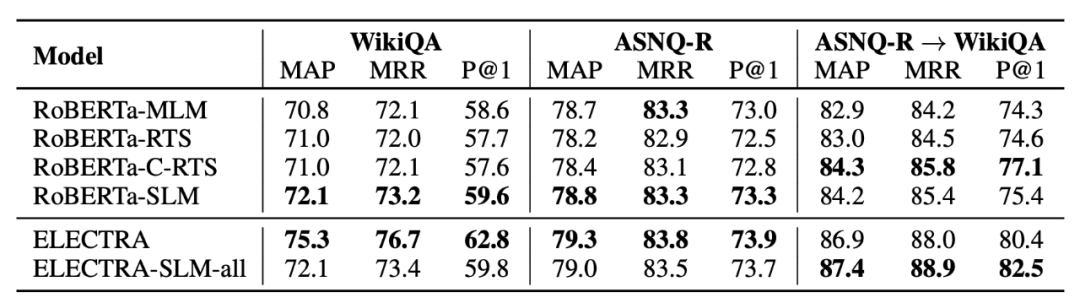
如图所示模型在QA和AS2基准数据集上的结果。针对RoBERTa模型,SLM策略在每个数据集上都优于MLM,甚至在SQuAD上与ELECTRA的性能相匹配。而在WikiQA这类低资源任务中,它获得了比MLM更大的优势,证实了更好的泛化能力,别忘了RTS和C-RTS相较于MLM只要求较少的资源来进行预训练。针对ELECTRA模型的结果,可以发现两种方法之间存在较大的差异。在测试集中,SLM-all与ELECTRA在ASNQ-R上的表现相当(79.0/79.3),在WikiQA上SLM-all表现较差(相差3.2%),但在从ASNQ-R到WikiQA的转移学习后,SLM-all方法的结果为87.4,而ELECTRA为86.9。SLM-all策略在迁移学习上表现出优越的性能,但是并不能确保在大多数任务中获得提升。
4 总结
在RoBERTa模型对比结果上,RTS和C-RTS策略在每个任务中都能与RoBERTa-MLM的性能相匹配,同时需要更少的训练时间。此外,RoBERTa-C-RTS在转移学习中也显示出比RTS和MLM更好的性能。SLM或许是MLM的一个有效替代方案:在使用完全相同的计算时,它在每个任务中都以一致的幅度超过了MLM,这也证明了去除[MASK]特殊标记有益于模型的预训练。在ELECTRA模型对比结果上可知,ELECTRA的性能并没有因为判别器只做二元分类而受到影响。ELECTRA-SLM-all则在迁移学习上性能的提升也非常有趣,它达到了这项工作中的最高性能。
参考文献
[1]Luca Di Liello, Matteo Gabburo, and lessandro Moschitti. Efficient pre-training objectives for Transformers. arXiv preprint arXiv:2104.09694





