谷歌Quoc Le团队新transformer:线性可扩展,训练成本仅有原版1/12
机器之心报道
编辑:泽南、杜伟
谷歌的新研究,让 transformer 模型的效率有了巨大提升,该方法的核心在于减少注意力机制。
Transformer 是目前深度学习领域最热门的技术,在语言和视觉领域都取得了很多突破。尽管因为模型体量不断增加而受到质疑,但大多数 Transformer 因为输入长度的二次复杂度问题,仍然限于短上下文大小——由于记忆容量有限,不得不抛弃较早的信息。这一限制阻止了 Transformer 模型处理长期信息的能力,而后者是许多应用程序的关键属性。
在学界,已经有很多技术试图通过更有效的注意力机制来扩展上下文能力。尽管其中一些方法具有线性理论复杂性,但常规 Transformer 仍然是最先进系统中的主要选择。从实际的角度来研究,现有的有效注意力方法至少存在以下缺点之一:
性能低下。实验表明,通过几个简单的调整来增强普通 Transformer 可以比文献中使用的常见基线强得多(见图 1)。与增强的 Transformer 相比,现有的高效注意力方法通常会导致质量显着下降,而这种性能下降超过了它们的效率优势。
计算开销。由于有效的注意力方法通常会使 Transformer 层复杂化并需要大量的数据 / 内存格式化操作,因此其理论复杂性和 GPU 或 TPU 等加速器的经验速度之间可能存在不小的差距。
低效率的自回归训练。大多数注意力线性化技术在推理中享受快速解码,但在语言建模等自回归任务上训练可能非常慢。这主要是由于它们在大量步骤中的 RNN 式顺序状态更新,使其无法在训练期间充分利用现代加速器的优势。
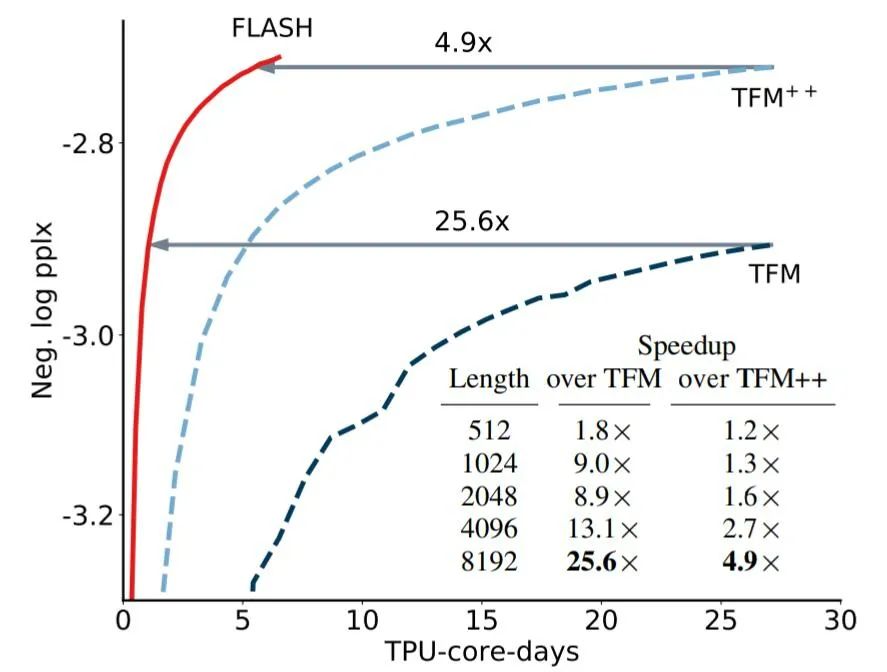
来自康奈尔大学、谷歌大脑的研究人员近日提出了一个新模型 FLASH(Fast Linear Attention with a Single Head),首次不仅在质量上与完全增强的 Transformer 相当,而且在现代加速器的上下文大小上真正享有线性可扩展性。与旨在逼近 Transformers 中的多头自注意力 (MHSA) 的现有高效注意力方法不同,谷歌从一个新层设计开始,自然地实现更高质量的逼近。FLASH 分两步开发:
首先设置一个更适合有效近似的新层,引入门控机制来减轻自注意力的负担,产生了下图 2 中的门控注意力单元 (Gated Attention Unit, GAU)。与 Transformer 层相比,每个 GAU 层更便宜。更重要的是,它的质量更少依赖于注意力精度。事实上,小单头、无 softmax 注意力的 GAU 与 Transformers 性能相近。
虽然 GAU 在上下文大小上仍存在二次复杂度,但它削弱了注意力的作用,允许稍后以最小的质量损失进行近似。
随后作者提出了一种有效的方法来逼近 GAU 中的二次注意力,从而导致在上下文大小上具有线性复杂度的层变体。其思路是首先将标记分组为块,然后在一个块内使用精确的二次注意力和跨块的快速线性注意力(如下图 4 所示)。在论文中,研究者进一步描述了如何利用此方法自然地推导出一个高效的加速器实现,在实践中做到只需更改几行代码的线性可扩展能力。
在大量实验中,FLASH 在各种任务、数据集和模型尺度上均效果很好。FLASH 在质量上与完全增强的 Transformer (Transformer++) 相比具有竞争力,涵盖了各种实践场景的上下文大小 (512-8K),同时在现代硬件加速器上实现了线性可扩展。
例如,在质量相当的情况下,FLASH 在 Wiki-40B 上的语言建模实现了 1.2 倍至 4.9 倍的加速,在 Transformer++ 上 C4 上的掩码语言建模实现了 1.0 倍至 4.8 倍的加速。在进一步扩展到 PG-19 (Rae et al., 2019) 之后,FLASH 将 Transformer++ 的训练成本降低了 12.1 倍,并实现了质量的显着提升。
论文《Transformer Quality in Linear Time》:

论文链接:https://arxiv.org/abs/2202.10447
门控注意力单元
研究者首先提出了门控注意力单元(Gated Attention Unit, GAU),这是一个比 Transformers 更简单但更强的层。虽然 GAU 在上下文长度上依然具有二次复杂度,但它在下文展示的近似方法中更可取。
相关的层包括如下:
原版多层感知机(Vanilla MLP);
门控线性单元(Gated Linear Unit, GLU),它是门控增强的改进版 MLP 变体。GLU 已被证实在很多情况下都有效,并在 SOTA Transformer 中使用;
门控注意力单元(GAU),其核心思路是将注意力和 GLU 作为一个统一层,并尽可能多地共享它们的计算,具体如下图 2 所示。这样做不仅实现了更高的参数和计算效率,而且自然地赋能一个强大的注意力门控机制。
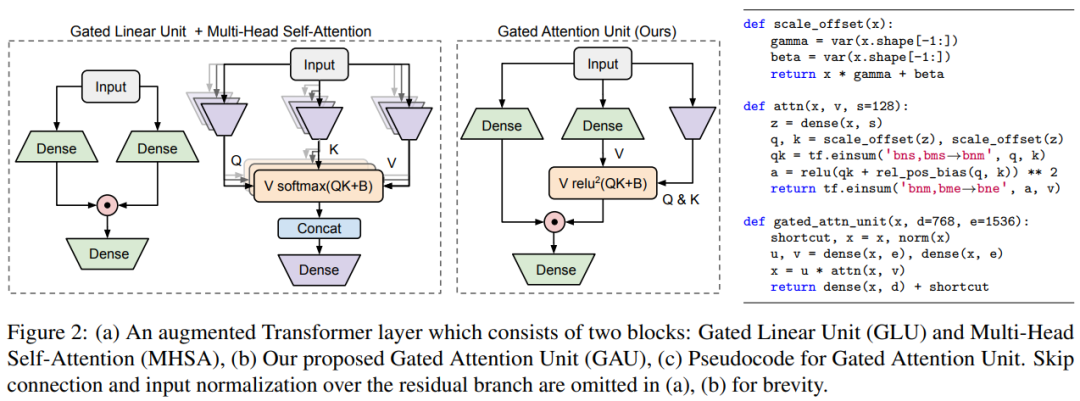
图 2 左为包含两个块的增强 Transformer 层,这两个块分别为门控线性单元(GLU)和多头自注意力(MHSA);图 2 中为研究者提出的门控注意力单元(GAU);图 2 右为 GAU 的伪代码。
研究者在下图 3 中展示了 GAU 与 Transformers 的比较情况,结果显示对于不同模型大小,GAU 在 TPUs 上的性能可与 Transformers 竞争。需要注意,这些实验是在相对较短的上下文大小(512)上进行的。

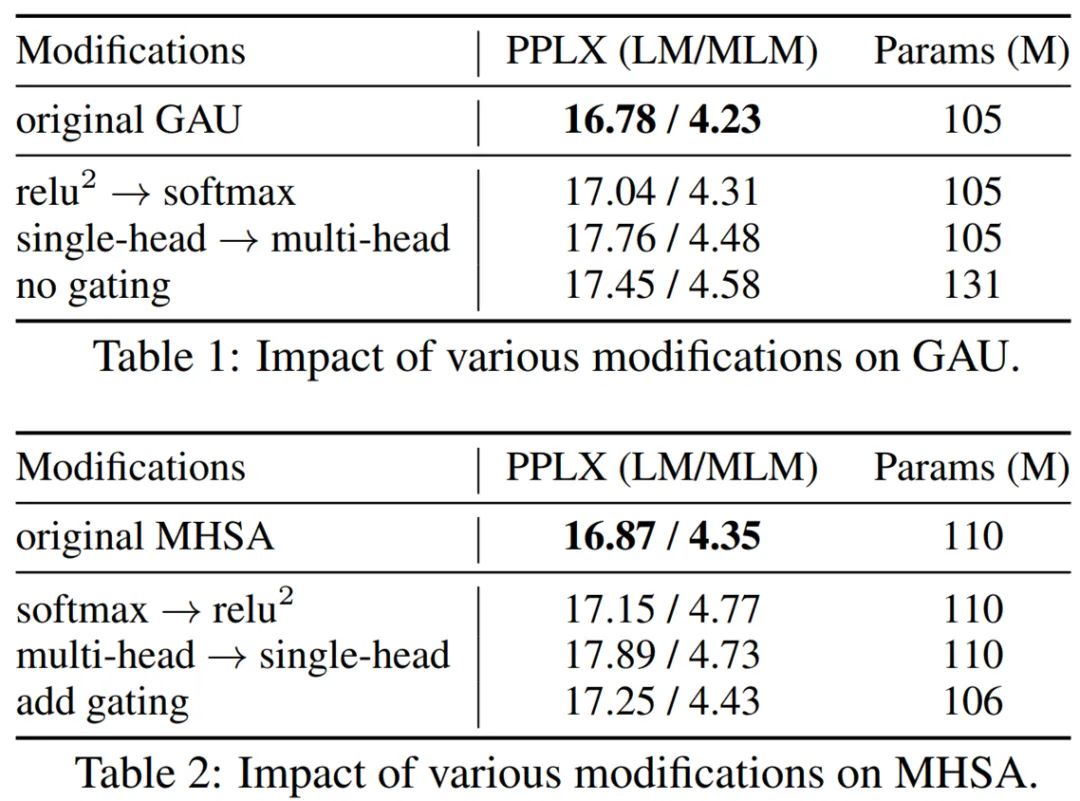
下表 1 和表 2 为层消融实验,结果显示 GAU 和 Transformers 各自都是局部最优的。
使用 GAU 的快速线性注意力(FLASH)
研究者从上一章节得到了以下两个重要的观察结果,并受到启发将 GAU 扩展至建模长序列中。
其一,GAU 中的门控机制使得可以使用没有质量损失的更弱的(单头、无 softmax)的注意力。如果进一步将这一思路引入到使用注意力建模长序列中,GAU 也可以提升近似(弱)注意力机制的有效性,比如局部、稀疏和线性注意力;
其二,使用 GAU 使注意力模块的数量自然地增加一倍,就开销而言,MLP+MHSA 约等于两个 GAU。由于近似注意力通常需要更多层来捕获完整依赖,因此这一特征使得 GAU 更适宜建模长序列。
研究者首先回顾了使用注意力建模长序列的一些相关工作,然后展示了如何使得 GAU 在长序列上以线性时间实现 Transformer 级别的质量。现有的线性复杂度变体(Linear-Complexity Variant)包括局部注意力和线性注意力。
混合块注意力
根据现有线性复杂度的优缺点,研究者提出了混合块注意力(mixed chunk attention),它融合了局部注意力和线性注意力的优点。下图 4 为二次注意力(Quadratic attention)、线性注意力和混合块注意力的构造比较。
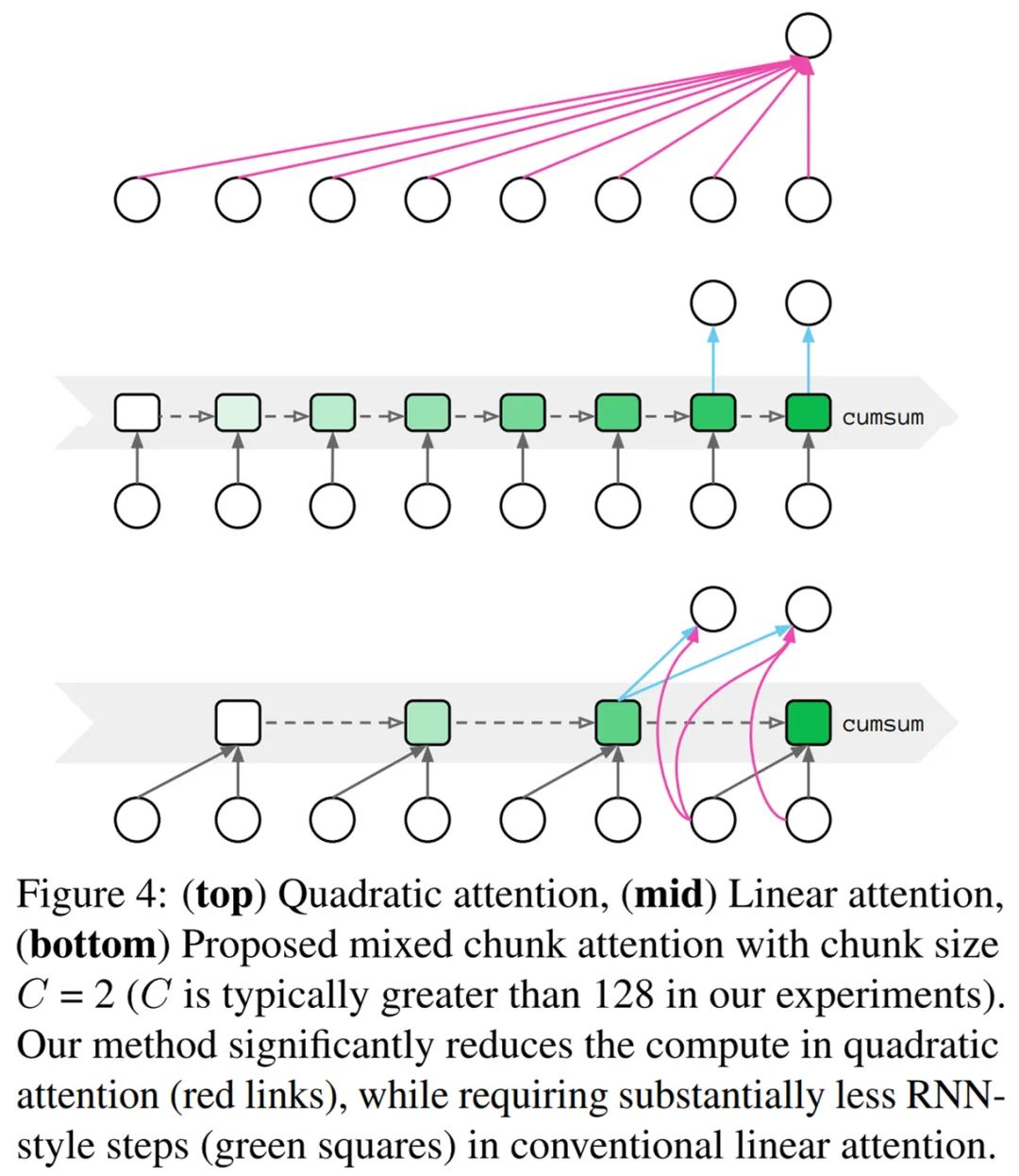
输入序列首先被切割成 G 个大小为 C 的非重叠块,也就是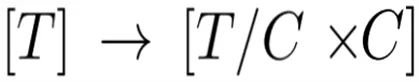
最后使用 per-dim 缩放和偏移来从 Z_g 中生成四种类型的注意力头,即 Q^quad_g、K^quad_g、Q^lin_g 和 K^lin_g。
研究者描述了如何使用局部注意力和全局注意力来高效地近似 GAU 的注意力。
每个块的局部注意力。局部二次注意力独立地应用于每个长度为 C 的块以生成部分预门控状态(pre-gating state)。
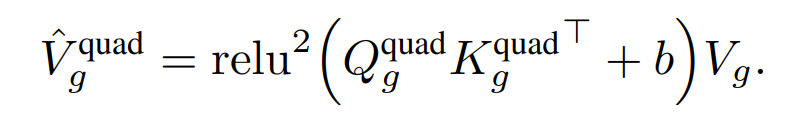
跨块(across chunks)的全局注意力。一个全局线性注意力机制被部署来捕获跨块的长程交互。
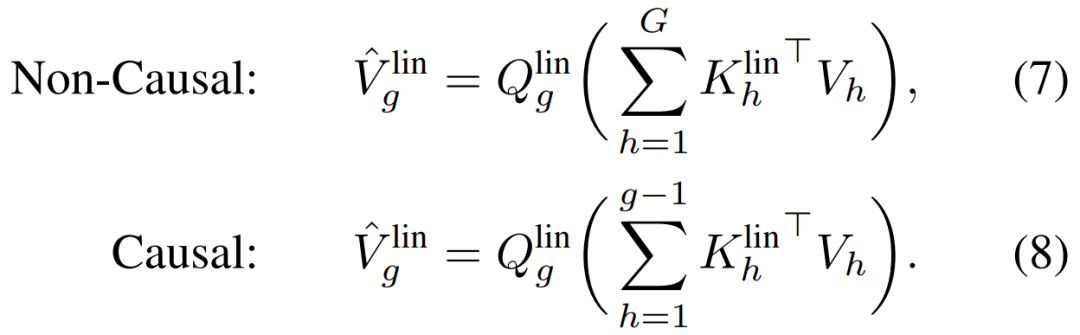
下图为混合块注意力的伪代码。

实验结果
为了证明模型的效率和泛化能力,该研究在多个大规模数据集上对模型进行了评估。
双向语言建模
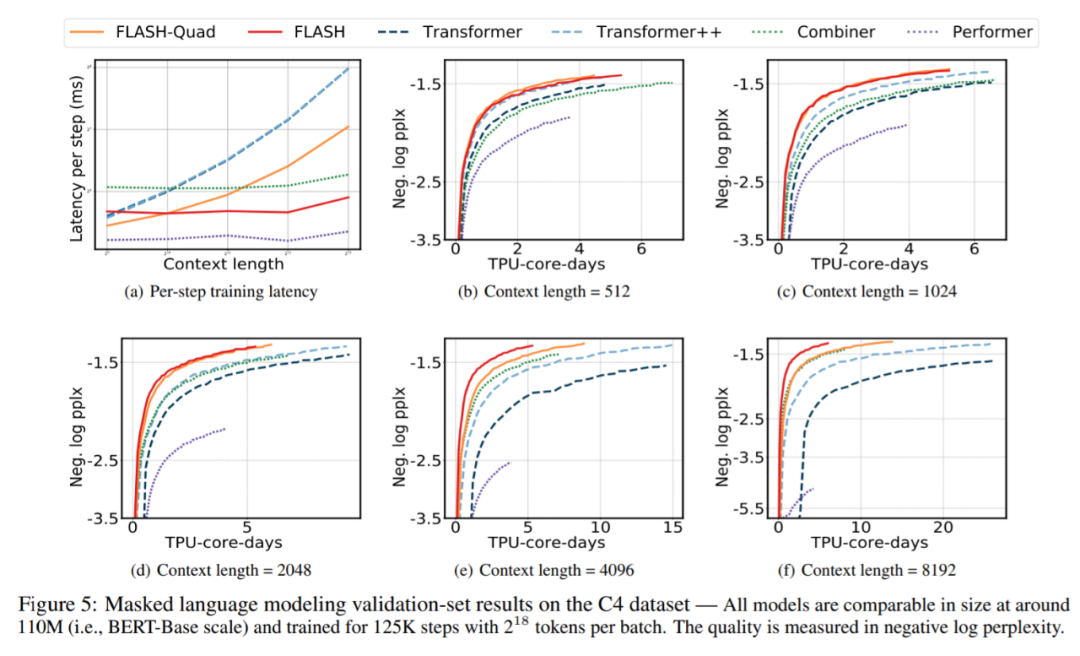
该研究在 C4 数据集上预训练和评估所有模型(Raffel 等人,2020),图 5(a) 显示了所有模型在不同上下文长度下每个训练 step 的延迟。
在所有六个模型中,随着上下文长度的增加,Combiner、Performer 和 FLASH 的延迟大致保持不变,这证明了上下文长度的线性复杂性。对于所有上下文长度,FLASH-Quad 始终比 Transformer 和 Transformer++ 快。特别是,当上下文长度增加到 8192 时,FLASH-Quad 的速度是 Transformer++ 的 2 倍。
更重要的是,如图 5(b)-5(f) 所示,对于从 512 到 8192 的所有序列长度,Google AI 的模型总是在相同的计算资源下达到最好的质量(即最低的困惑度)。特别是,如果目标是在 125K step 匹配 Transformer++ 的最终困惑度,FLASH- Quad 和 FLASH 可以分别减少 1.1×-2.5× 和 1.0×-4.8× 的训练成本。值得一提的是,FLASH 是唯一一个与其二次复杂度对应物实现竞争性困惑度的线性复杂度模型。
自回归语言建模
从图 6(a) 可以看出,在二次复杂度和线性复杂度模型中,FLASH- quad 和 FLASH 的延迟最小。在图 6(b)-6(f) 中,Google AI 比较了在 Wiki40-B 上所有模型在增加上下文长度时的质量和训练成本之间的权衡。与 MLM 任务类似,Google AI 的模型在在质量和训练速度方面优于所有其他模型。
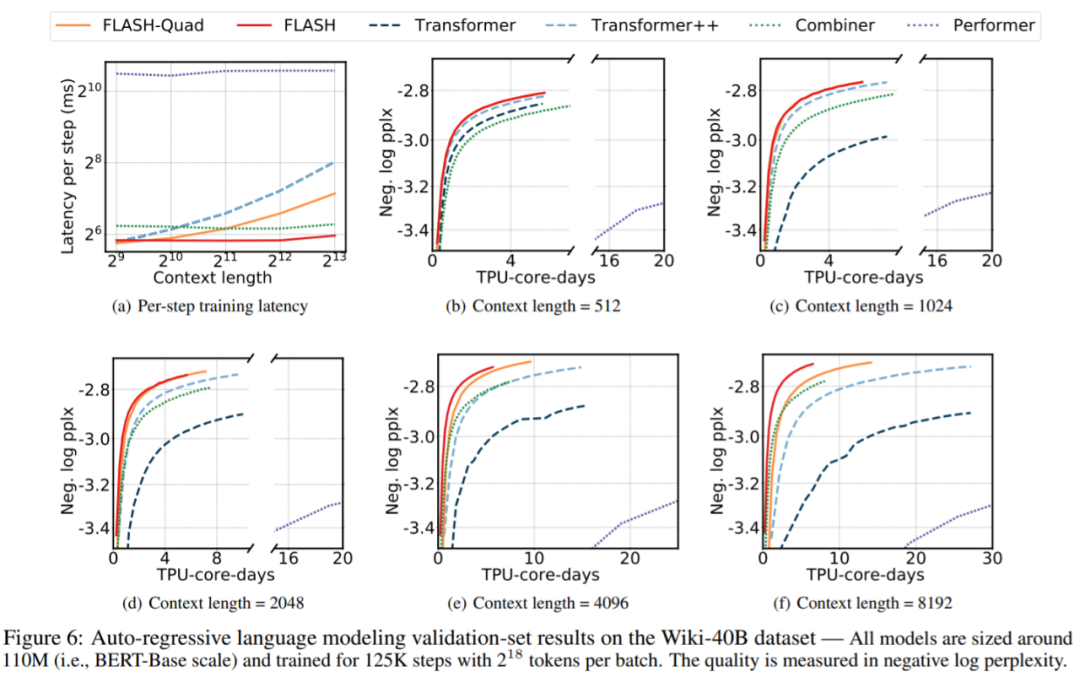
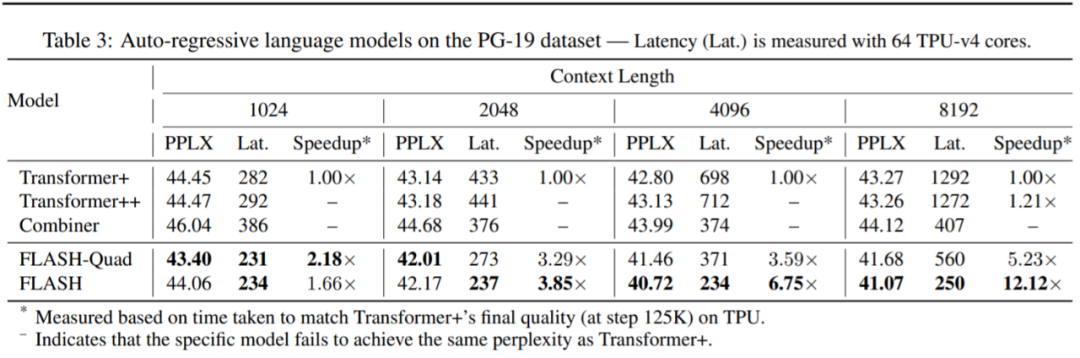
Google AI 还在 PG-19 数据集上进行了实验,结果如表 3 所示。与 Wiki-40B 相比,在 PG-19 上,FLASH 在困惑度和训练时间上比 Transformer + 获得了更显著的改善。例如,在上下文长度为 8K 的情况下,FLASH-Quad 和 FLASH 只需 55K 和 55K step 即可达到 Transformer+ 的最终困惑度(125K step),分别产生 5.23 倍和 12.12 倍的加速。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com



