攻克机器学习硕士学位,我的那些年与必备技能!

编者按:人工智能发展日趋成熟,也成为众多开发者职业生涯的首选方向。然而相较于其他领域,人工智能中的深度学习、机器学习、计算视觉、神经网络等技术更为错综复杂,进修难度也更胜一筹。对此,对于入门和想要进阶的学生及开发者群体,该如何攻克?在本文中,来自英国萨里大学机器学习与计算机视觉专业硕士Richmond Alake将从自身学业历程出发,分享一下其在读机器学习硕士的收获,以及相关的经验与课程,希望能帮助大家有所收获。

以下为译文:
其实,每所大学的课程不会有太大差异。所以,大家可以从本文了解机器学习和计算机视觉理学硕士的一些内容。除了在学习期间获得的东西之外,我还会分享更多学术知识,以及作为一名计算机视觉工程师职位相关的其他信息。

攻读机器学习硕士需要具备哪些必备技能?
研究生期间都会做一些选题,这些课题主要是反映机器学习领域的未来一些发展方向。而且机器学习的每个课程里都涵盖了很多内容。因此,我在修读MSc(Master of Science)学位需要确保在学习这些课程之前,还需要具备以下前提条件:
理解线性代数和微积分(微分/优化)
了解统计和概率研究
具有编程语言背景
拥有计算机科学、数学、物理或电子与机械工程专业学士学位
接下来介绍一下,我在读机器学习硕士时学到的关键内容:

计算机视觉
从我比较强项的课程模块说起,计算机视觉和深度学习研究是我真正非常感兴趣的机器学习领域,或者说是开发技术能直接产生实际影响,这点着实吸引了我。
近几十年来,媒体极大赞赏了计算机视觉取得的进步。如,面部识别系统的出现就非常重要,因为在国际机场、银行和政府组织等重要场景中,面部识别系统几乎无处不在。
我在硕士学业生涯中,对计算机视觉的学习研究比较有条理,我认为一开始不能直接进入实践和分析最新技术阶段,而是应该从了解基本图像处理技术开始,这样才能真正使用计算机视觉这一高级技术。
在深度学习中,想要了解卷积神经网络的底层,要从输入图像(例如线条和边缘)学习。不过,在卷积神经网络(CNN)引入计算机视觉之前就有基于启发式的技术可用于检测特征图上的目标并从图像中提取特征。我的计算机视觉研究就是通过这一系列基于启发式技术的工作原理,学以致用,才让我对该该领域基础有了理解。
计算机视觉研究为我提供了传统机器学习技术的知识,还有处理图像的技能,比如提取特征并对从图像中获得的描述符进行分类等。
接下来,分享一下我在研究生期间用到的一些议题和术语,好奇的小伙伴可以看一下:
SIFT(Scale Invariant Feature Transform):这是一种计算机视觉技术,用于生成图像关键点描述符(特征向量)。生成的描述符包含有关特征的信息,例如边缘、拐角和斑点。描述符可用于检测跨越不同比例和失真的图像的对象。SIFT用于诸如对象识别、手势识别和跟踪之类的应用程序中。SIFT的关键在于,其检测到的特征对于仿射变换(例如缩放,平移和旋转)是不变的。
HOG(Histogram of Orientated Gradients):这是一种用于从图像中提取特征的技术。提取的特征是通过图像中的边缘和拐角提供的信息中得出的,更具体地说,是图像中的对象提供的。简而言之,该技术可以识别图像中的边缘(渐变)、角和线的位置,并且还可以获取有关边缘方向的信息。HOG描述符生成一个直方图,其中包含有关边缘分布的信息和从图像中检测到的方向信息。该技术可以在计算机视觉应用程序以及图像处理中找到。
PCA(Principal Component Analysis):一种降维的算法。通过将数据点从较高的维度投影到较低的平面,但仍保持信息并最大程度地减少信息丢失,可以减小维度。
其他的还有:线性插值、无监督聚类(K均值)、视觉搜索等等。
一开始学习我就希望自己能开发出基于计算机视觉的App,对象分类又比较受欢迎,这样相对来说就更容易实现既学知识又能实际应用。另外我的研究过程中是在Matlab上开发视觉搜索系统的。
Matlab是为高效的数值计算和矩阵处理而开发的一种编程语言,并且Matlab库配备了一套算法和可视化工具。
之前JavaScript、Java和Python的编程经验帮我很快搞定了Matlab编程语法,所以我就可以全神贯注的研究计算机视觉。
更多视觉搜索系统的信息
要实现的视觉系统很简单,它就是通过查询图像传递给系统,之后系统将生成一组图像结果,这些结果与传递到系统中的匹配相似图像。要补充一点,该系统有一个存储图像的数据库,是用于从中提取结果图像(先查询图像,然后输出结果图像)。
视觉系统没有使用任何花哨的深度学习技术,就是用了前面提到的一些传统机器学习技术。只需传递转换为灰度的RGB图像,然后在图像上添加特征提取器即可,之后,提取图像描述符并将其表示在N维特征空间上。在此特征空间内,就可以通过计算两个N维点之间的欧式距离来得出相似的图像。
更深层次的应用
计算机视觉的理解不仅局限于图像上,还会涉及到视频中使用的算法和技术。要明白,视频可以理解为图像序列,所以收集和处理输入数据上就不需要学习新的内容。
如果使用诸如YOLO、RCNN等对象检测框架,那在一系列图像中进行对象跟踪似乎就变得非常琐碎。但要认识到,研究计算机视觉不仅是使用预训练的网络和微调。基于我个人在该领域的发展角度来看,扎实学习的最佳方法是随着时间推移,在研究中慢慢积累这些传统技术。
那么,对于对象跟踪任务,引入了以下内容:
Blob追踪器
卡尔曼滤波器
粒子过滤器
马尔可夫过程
与计算机视觉的相关性
老实说,我目前没有使用任何传统机器学习中的分类器,而且我觉得我不会很快使用它。但是值得注意的是,自动驾驶汽车、车牌读取器、车道检测器均采用了上述所提及到了一到两种方法。

深度学习
深度学习是计算机视觉研究的自然发展成果。计算机视觉与我的计算机视觉研究类似的方法,即在转向高级主题和应用程序开发之前,对领域的基础有了深入的了解。
深度学习研究始于对图像、像素的基本构建块的理解。数字图像是包含像素集合并以网格的形式呈现。了解了图像的基础之后,就要继续学习如何将图像存储在系统内存中。帧缓冲区是在系统内存中存储像素的位置的名称(很少有MOOC课程会教你这一点)。
另外,在还不了解卷积神经网络(CNN)的情况下,你是无法学习深度学习的,因为它们是紧密相连的。
我的研究介绍了过去20年(从LeNet-5到RCNN)引入和开发CNN的时间表,以及它们在替代传统管道中完成诸如对象识别之类的典型计算机视觉任务的作用。
在我的研究期间,介绍了深度学习早期提出的不同CNN架构的探索。AlexNet、LeNet和GoogLeNet是案例研究,用于对卷积神经网络的内部知识及其在解决诸如目标检测,识别和分类等任务中的应用的理解。
另外,我学会的一项重要技能是如何阅读研究论文。阅读研究论文并不是直接学习的技能。如果真的想要研究一下深度学习,那么就要选择好信息和研究的来源。
利用深度学习框架提供的预训练模型相当容易。尽管如此,一项高级研究仍希望了解所提出的每种体系结构的技术和组件的内在细节,当然这些信息仅在研究论文中会提出。
在这总结了一些深度学习模块的议题(还是跳过了定义,感兴趣的同学可以看一下):
MLP:多层感知器(MLP)是几层感知器,一个接一个地连续堆叠。MLP由一个输入层,一个或多个TLU层(称为隐藏层)和一个最后一层(称为输出层)组成。
NST:一种涉及利用深度卷积神经网络和算法从一幅图像中提取内容信息并从另一幅参考图像中提取样式信息的技术。在提取样式和内容之后,将生成一个组合图像,其中生成的图像的内容和样式来自不同的图像。
RNN和LSTM:神经网络体系结构的一种变体,可以接受任意大小的输入作为输入,并生成随机大小的输出数据。RNN神经网络架构学习时间关系。人脸检测:这是实施系统任务的一个术语,该系统可以自动识别和定位图像和视频中的人脸。在与面部识别,摄影和运动捕捉相关的应用程序中存在面部检测。
姿势估计:从提供的数字资产(例如图像,视频或图像序列)中推断出人体主要关节位置的过程。姿势估计的形式存在于诸如动作识别,人类交互,为虚拟现实和3D图形游戏创建资产,机器人技术等应用程序中。
对象识别:识别与目标对象关联的类的过程。对象识别和检测是具有相似最终结果和实现方法的技术。尽管识别过程先于各种系统和算法中的检测步骤。
跟踪:一种在一段时间内识别,检测和跟踪图像序列中的关注对象的方法。在许多监控摄像机和交通监控设备中都可以找到系统内跟踪的应用。
对象检测:对象检测与Computer Vision相关联,描述了一种可以识别图像中所需对象或物体的存在和位置的系统。请注意,要检测的对象可能有单个或多个出现。
其他的还包括像神经网络,反向传播,CNN网络架构,超分辨率,手势识别,语义分割等......
出于兴趣,我已经在边缘设备上合并了面部检测,手势识别,姿势估计和语义分割模型。在目前的职位上,我实践,训练和评估了许多深度学习模型。如果你想在先进的公司中使用大量前沿算法,工具,那么深度学习就是一个可以使您站在AI实用商业开发的最前沿的领域。

论文
硕士学位论文的目的就是要利用在学习过程中获得的所有技能、知识和经验,为基于现实生活的问题设计解决方案。
我写的是基于计算机视觉技术对四足动物进行运动分析,运动分析用到的是计算机视觉技术里面的姿势估计。
这是我第一次被引入深度学习框架领域。我对运动分析的解决方案是基于卷积神经网络与深度学习的解决方案。在选择框架时,我曾在Caffe和Keras之间犹豫过,但由于PyTorch具有与任务相关的随时可用的预训练模型,所以我选择了PyTorch。Python是我选择的编程语言。
这是我写完论文后学习到的内容:
转移学习/微调
Python程式设计语言
C#编程语言
姿势估计的理论
有关如何使用Unity3D进行仿真
使用Google Cloud Platform
在这里扩展说一下运动分析:
运动分析是指从清晰的运动图像中获取运动信息和细节,或代表序列到运动序列描述的图像排序。利用运动分析的应用程序和操作的结果以最直接的形式详细介绍了运动检测和关键点定位。复杂的应用程序允许利用顺序相关的图像逐帧跟踪对象。
目前,运动分析及其各种应用形式在时间数据上使用时,可提供更多的信息。不同行业例如医疗保健、制造、机械、金融等行业,都在使用应用运动分析的方法来解决问题或为消费者创造价值。
整个行业对于利用运动分析的多样性,已经间接引入了运动分析的各种子集,例如姿势估计、对象检测、对象跟踪、关键点检测以及其他不同子集。
再说说论文中的其他内容:
论文提出了一种利用计算机视觉和机器学习技术进行运动分析的方法。该方法是使用合成的四足动物图像数据集来训练预训练的关键点检测网络。
Keypoint-RCNN是Pytorch库中的内置模型,它扩展了原始Fast-RCNN和Faster-RCNN的功能。
论文中的方法修改了在COCO 2017对象检测和分割数据集上预训练的Keypoint-RCNN神经网络架构,并使用合成生成的数据集对最后一层进行了训练。
通过扩展用于人体的17个关节的人体关键点检测的基准框架,我提出了该框架的扩展,该框架可以预测几个26个关节产生的四足动物的主要位置。
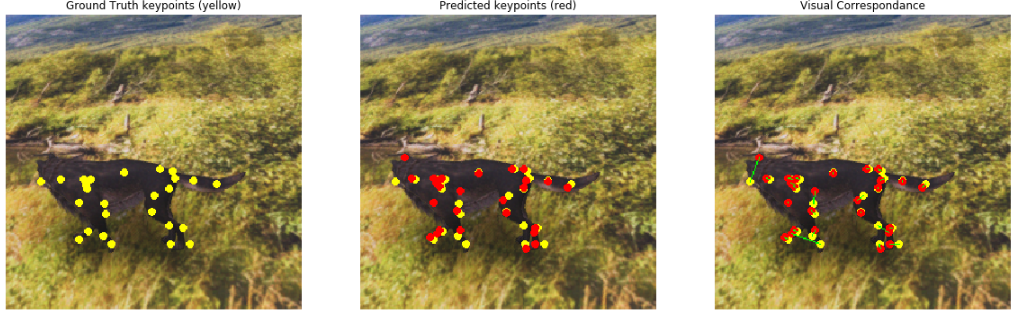
论文的结果节选
定性和定量评估策略可以很明显的改进Keypoint-RCNN体系结构在人工四足动物上预测关键点时的视觉和度量性能。
如果你在研究中已经实现了这些,我就有点班门弄斧。

结论
计算机领域变化太快了,我的课程是从2018年-2019年的,现在已经2020年了,我们会看到大量更多的机器学习领域的贡献,所以,如果没有在我的论文中看到,你在做机器学习过程中看到的或学到的一些议题,也不要惊讶。
不要忘了,在AI领域,你要做的不光是学习一些模型,还要不断地研究,不断地学习。
最后,我希望我的这篇文章对大家有用,欢迎大家留言,说说你在学习ML和CV的时候学到了哪些知识并应用了实际场景中拉~
原文:https://towardsdatascience.com/what-i-learnt-from-taking-a-masters-in-computer-vision-and-machine-learning-69f0c6dfe9df
本文为 CSDN 翻译,转载请注明来源出处。


更多精彩推荐 ☞30名工程师,历时1300天打造,又一“国产”AI框架开源了 ☞支付宝、微信支付回应被反垄断调查;搜狗宣布成立独立特别委员会;GNU nano 5.0 发布| 极客头条 ☞ V神演讲内容曝光!Defi、挖矿、行业应用更多主题大揭秘 ☞ PyTorch 1.6、TensorFlow 2.3、Pandas 1.1同日发布!都有哪些新特性? ☞ 程序员必备基础:Git 命令全方位学习 ☞ 公链还能这样玩?二次元、出圈与社区自治 ![]()
点分享 ![]()
点点赞 ![]()
点在看








