【AI 幽灵】超 90% 论文算法不可复现,你为何不愿公开代码?

过去几年发表的 AI 顶会论文提出的 400 种算法中,公开算法代码的只占 6%,只有三分之一分享了测试数据,只有一半分享 “伪代码”。这是今年 AAAI 会议上一个严峻的报告。科学家们正在通过“可复现性挑战” 鼓励复现新算法,或研究依据论文自动生成代码的工具。AI 将在未来扮演越来越重要的角色,我们需要信任这些 AI,那么我们必须能够复现它。
一个幽灵正在 AI 领域上空徘徊:复现的幽灵。
科研方法认为,科学研究应该可以让其他研究人员在相同的条件下重现其结果。然而,由于大多数人工智能研究人员不公布他们用来创建算法的源代码,其他研究人员很难做到复现和验证。

同一个算法训练 AI 走路,结果可能千奇百态
顶会论文提出的 400 种算法,只有 6% 分享代码
去年,加拿大蒙特利尔大学的计算机科学家们希望展示一种新的语音识别算法,他们希望将其与一名著名科学家的算法进行比较。唯一的问题:该 benchmark 的源代码没有发布。研究人员不得不从已公开发表的描述中重现这一算法。但是他们重现的版本无法与 benchmark 声称的性能相符。蒙特利尔大学实验室博士生 Nan Rosemary Ke 说:“我们尝试了 2 个月,但都无法接近基准的性能。”
人工智能(AI)这个蓬勃发展的领域正面临着实验重现的危机,就像实验重现问题过去十年来一直困扰着心理学、医学以及其他领域一样。AI 研究者发现他们很难重现许多关键的结果,这导致了对研究方法和出版协议的新认识。法国国家信息与自动化研究所的计算神经科学家 Nicolas Rougier 说:“这个领域以外的人可能会认为,因为我们有代码,所以重现性是有保证的。但完全不是这样。” 上周,在新奥尔良召开的 AAAI 会议上,重现性(reproducibility)问题被提上议程,一些团队对这个问题进行了分析,也有团队提出了减轻这个问题的工具。
最根本的问题是研究人员通常不共享他们的源代码。在 AAAI 会议上,挪威科技大学计算机科学家 Odd Erik Gundersen 报告了一项调查的结果,调查针对过去几年在两个 AI 顶会上发表的论文中提出的 400 种算法。他发现只有 6%的研究者分享了算法的代码。只有三分之一的人分享了他们测试算法的数据,而只有一半分享了 “伪代码”。(许多情况下,包括 Science 和 Nature 在内的期刊上发表的 AI 论文中也没有代码。)
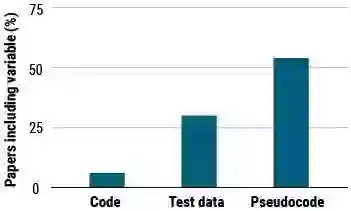
针对主要会议上发表的 400 篇 AI 论文的调查显示,只有 6%的论文包含算法的代码,约 30%包含测试数据,54%包含伪代码。
研究人员说,这些缺失的细节的原因有很多:代码可能是一项正在进行中的工作,所有权归某一家公司,或被一名渴望在竞争中保持领先地位的研究人员紧紧掌握。代码可能依赖于其他代码,而其他代码本身未发布。或者代码可能只是丢失了,在丢失的磁盘上或被盗的笔记本电脑上——Rougier 称之为 “我的狗吃了我的程序” 问题。
假设你可以获得并运行原始代码,它仍然可能无法达到你的预期。在机器学习领域,计算机从经验中获取专业知识,算法的训练数据可以影响其性能。 Ke 推测,不知道那个语音识别基准的训练数据是什么阻碍了她的团队的进展。“每跑一次的结果都充满了随机性,” 她补充说,你可能 “真的非常幸运,跑出一个非常好的数字。”“研究报告中通常写的就是这个。”
击败幽灵:从论文中自动生成代码
在 AAAI 会议上,加拿大麦吉尔大学的计算机科学家 Peter Henderson 表示,通过反复试验学习设计的 AI 的性能不仅对所使用的确切代码高度敏感,还对产生的随机数 “超参数” 也非常敏感——这些设置不是算法的核心,但会影响其学习速度。
他在不同的条件下运行了这些 “强化学习” 算法中的几个,发现了截然不同的结果。例如,运动算法中使用的一个简笔画虚拟“半猎豹”,它可以学习在一次测试中奔跑,但只会在另一次测试中在地板上徘徊。
Peter Henderson 说,研究人员应该记录更多这些关键细节。 “我们正试图推动这个领域有更好的实验程序,更好的评估方法。”
Peter Henderson 的实验是在 OpenAI Gym 强化学习算法测试平台上进行的,OpenAI 的计算机科学家 John Schulman 帮助创建了 Gym。John Schulman 说,Gym 有助于标准化实验。 “Gym 之前,很多人都在进行强化学习,但每个人都为自己的实验做好了自己的环境,这使得大家很难比较各种论文的结果。”
IBM Research 在 AAAI 会议上提出了另一种工具来帮助复现:一种自动重新创建未发布源代码的系统,它为研究人员节省了数天或数周的时间。这个系统是一种由小型计算单元层组成的机器学习算法,类似于神经元,用于重新创建其他神经网络。系统通过扫描一份 AI 研究论文,寻找描述神经网络的图表或图示,然后将这些数据解析为图层和连接,并以新代码生成网络。该工具现在已经复现了数百个已经发布的神经网络,IBM 计划把它们放置在一个开放的在线存储库中。
荷兰埃因霍芬理工大学(Eindhoven University of Technology in the Netherlands)的计算机科学家 Joaquin Vanschoren 为创建了另一个存储库:OpenML。它不仅提供算法,还提供数据集和超过 800 万个实验运行及其所有相关详细信息。 “你运行实验的确切方式充满了无证的假设和决定,很多这些细节从来没有成为论文。”Vanschoren 说。
心理学通过创造一种有利于复现的文化来处理它的再现性危机,AI 也开始这样做。 2015 年,Rougier 帮助启动了一个致力于复现的计算机科学杂志 ReScience,NIPS 已经开始从其网站链接到论文的源代码(如果有的话)。
Nan Rosemary Ke 正在邀请研究人员尝试复现提交给即将举行会议的论文,以实现 “可复现性挑战”。Nan Rosemary Ke 说,近 100 个复现项目正在进行中,大多数是由学生完成的,他们可能因此获得学分。
然而,人工智能研究人员表示,目前的激励措施仍然不符合可复现性。他们没有足够时间在每种条件下都测试算法,或者在文章中记录他们尝试过的每个超参数。因为他们面临发论文的压力——许多论文每天都在网上发布到 arXiv 上,而且也没有同行评审。
此外,许多人也不愿意报告失败的复现。例如,在 ReScience,所有公布的复现项目迄今为止都是正面的。Rougier 说,他也尝试过发表一些失败的项目,但年轻的研究人员往往不希望批评别人,失败的项目也就无人问津了。这就是为什么 Nan Rosemary Ke 拒绝透露她想用作基准的语音识别算法背后的研究人员的原因之一。
Gundersen 说这种文化需要改变。 “这样做不是羞愧” 他说, “这只是说实话。”
如果我们想要信任 AI,必须能够复现它
Gundersen 说,随着人工智能领域的发展,打破不可复现性将是必要的。
复现对于证明实验产生的信息能够在现实世界中一致地使用,并且得到非随机的结果是必不可少的。一个仅由其创建者测试过的 AI 在另一台计算机上运行时或者如果输入不同的数据时,可能不会产生相同的结果。
当涉及到机器学习算法时,可复现性问题会变得尤其突出。有很多原因导致人们不会共享源代码或数据:代码可能正在完成中,或属于公司的专有信息,再加上研究人员担心竞争,因此机器学习算法的可复现性较差。在某些情况下,代码甚至可能完全丢失:电脑破损或被盗、硬盘丢了,或者被狗吃掉(可以找这种借口)。
这种情况对行业的未来不是好消息。人工智能一直在产生令人难以置信的繁荣,并且很可能我们会在未来几年拥有超智能的 AI,它将在社会中扮演越来越重要的角色。如果我们想让这种美好的未来持续繁荣,我们必须信任我们实施的每一个 AI,如果我们想要信任它,就必须能复现它。
参考链接:http://www.sciencemag.org/news/2018/02/missing-data-hinder-replication-artificial-intelligence-studies
https://futurism.com/scientists-cant-replicate-ai-studies/

媒体合作请联系:
邮箱:contact@dataunion.org


