浅谈最广泛应用的金融风控算法-评分卡
信用是一切社会金融体系的根本,有了每个人的信用我们才可以进行放贷、共享充电宝、共享单车等业务。如果可以准确的给每个社会成员的信用做一个打分,将对金融业务的推进有很大作用,很多相关业务的企业也在探索如何实现信用分。

目前业内最通用的方案是评分卡算法,这个算法底层其实就是简单的二分类模型,将逻辑回归或者xgboost进行封装。但是为什么不能直接使用xgboost甚至深度学习算法做信用评估呢?因为金融业务有自己的特殊性,要求模型需要有强解释性,所以评分卡解决方案经常包含分箱和评分两个模块。就是为了做到每个分数的强解释性。
通过一个例子介绍什么叫强解释性。以下图为例:
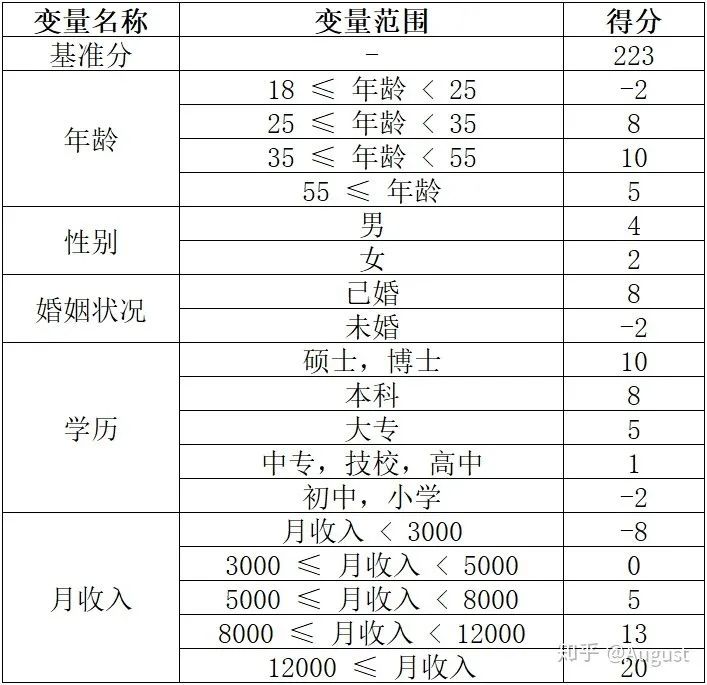
这是一个评分卡算法的部分特征数据展示,有年龄、性别、婚姻状况、学历、月收入。评判每个人的分数也很容易:
客户分=基准分+年龄分+性别分+婚姻状况分+学历分+月收入分
所以在评分卡体系中,每个人的分数都会拆分成很多子模块,这些子模块的分数的和,跟基准分加到一起就是信用评分。接下来介绍下评分卡的执行流程。
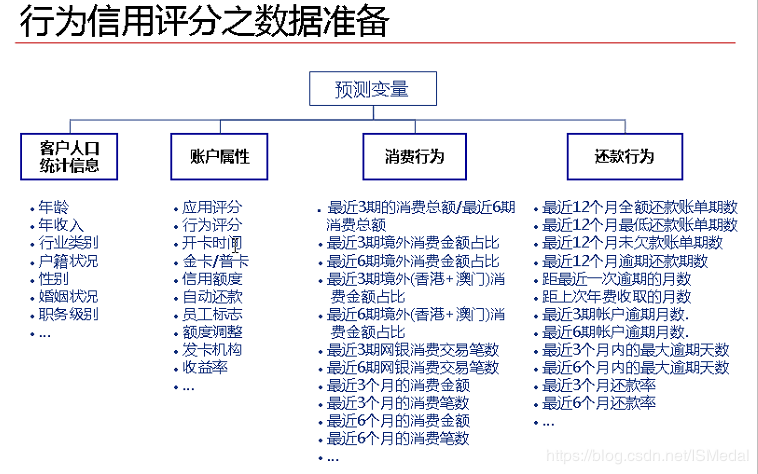
通常评分卡模型的数据需要包含四个方面,分别是客户统计信息、账户属性、消费行为和还款行为。
根据数据目标的不同,可以分为ABC三种评分卡:
贷前:申请评分卡(Application score card),又称为A卡
贷中:行为评分卡(Behavior score card),又称为B卡
贷后:催收评分卡(Collection score card),又称为C卡
分箱算法是将每个字段按照不同的模式进行离散化处理。分箱有很多模式,分为有监督模式和无监督模式。
有监督分箱:通过训练二叉树模型,将IV大的切分点找出来实现分箱
无监督分箱:利用等频、等距等模式进行分箱
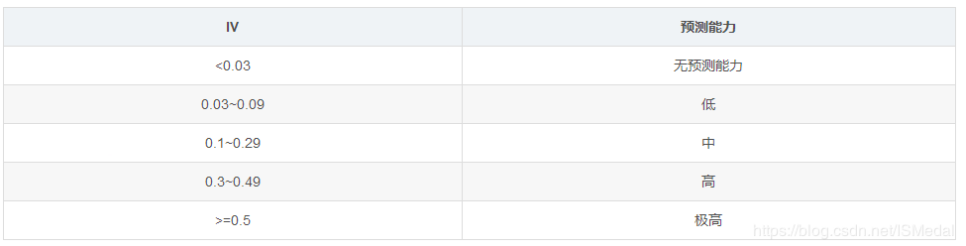
分箱出来的分箱结果需要进行评估,并且不断调整分箱。评估方式是要计算WOE和IV指标。

WOE指的是该组好的客户和所有好的客户的比例,WOE的值最终会影响IV的值,IV的公式:

IV的值越大,说明这个分箱模式对结果的预测越重要,所以分箱的目的是尽可能的提升每组分箱结果的IV值。
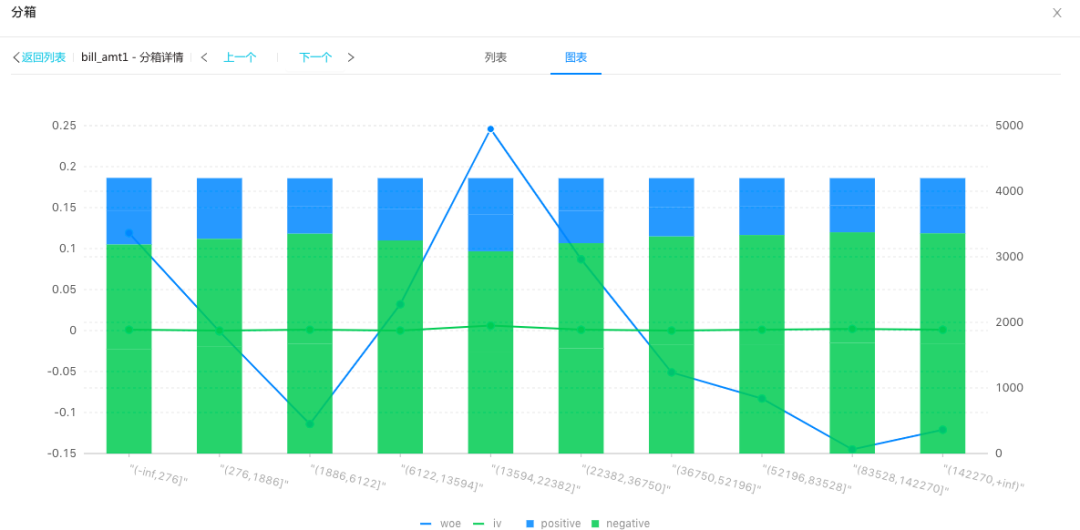
通常分箱算法会提供一个WOE和IV的展示图:
评分算法相对就比较简单,其实就是训练一个逻辑回归或者XGboost模型,将模型系数跟对应的分箱的WOE值做加权。
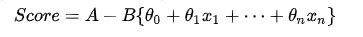
其中A是个基准分,B为常量,量系数 

参考文献:
[1]https://zhuanlan.zhihu.com/p/36539125
[2]https://blog.csdn.net/ISMedal/article/details/89380396
[3]https://www.jianshu.com/p/c3fa53c54cca





