基础知识 | 目标检测中Anchor的认识及理解

近期好多同学都在纠结Anchor的设置,而且部分同学私信,可不可以把这个基础知识详细说一次,今天就单独开一次小课,一起来学习Faster R-CNN中的RPN及Anchor。

说到RPN和Anchor,应该立马就能想到Faster R-CNN网络框架,这个我平台在之前就有详细的介绍过。
往期回顾
有兴趣的可以点击进入看看,当作复习一下。首先我先将几类经典的目标检测网络做一个对比,然后开始说说今天要讲的知识。
最开始出现的是R-CNN,如下图:
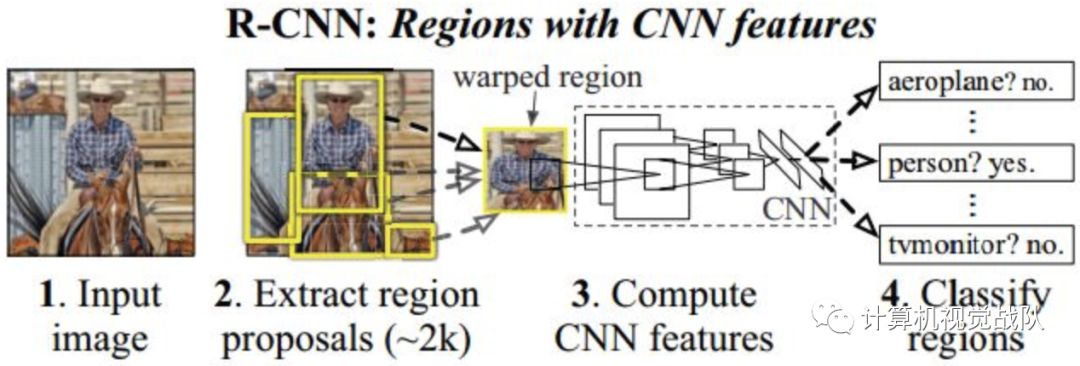
从上图可以看出其框架做了很多重复的计算,在第二步之后,如果有2k个proposals,那后面就要执行2k边,太低效。于是,出现了改进的SSP-Net,如下图:
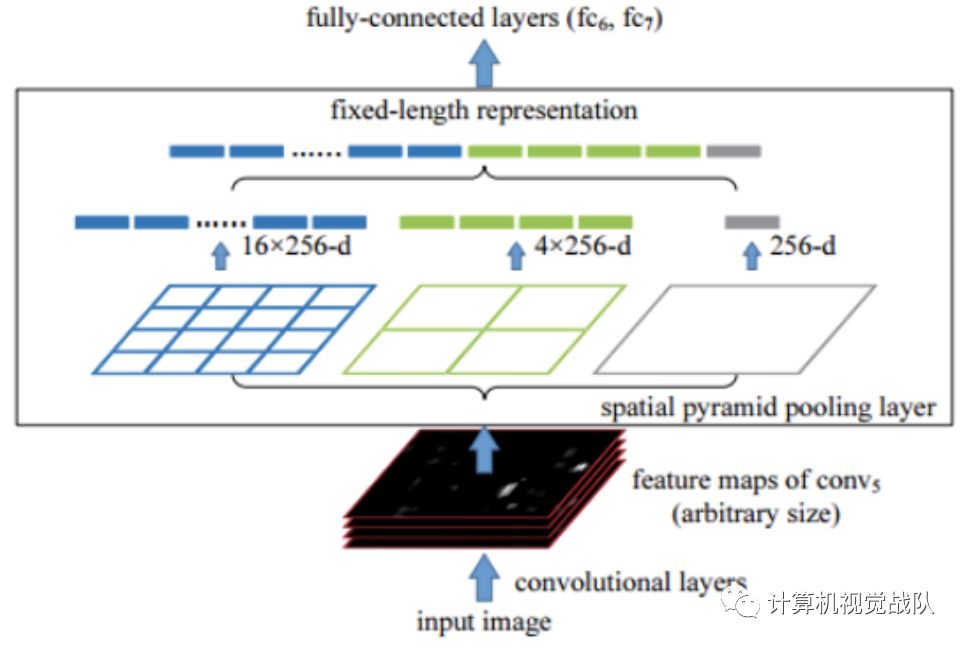
SSP-Ne框架组合了Classification和Regression,做成单个网络,并且可以Een-to-End进行训练,速度上提高许多。但是,SSP-Net还是基于Selective Search产生proposal,之后就出现了Fast R-CNN,其是融合了R-CNN和SPP-Net的创新,并且引入多任务损失函数,使整个网络的训练和测试变得十分方便。
但是Region proposal的提取还是使用了Selective Search,目标检测时间大多消耗在这上面(大约region proposal需2~3s,而提特征分类只需0.32s),这种是无法满足实时应用,而且并没有实现真正意义上的端到端训练测试(因为region proposal使用了Selective Search先提取处来)。
于是就有了直接使用CNN产生region proposal并对其分类,这就是Faster R-CNN框架,如下图:
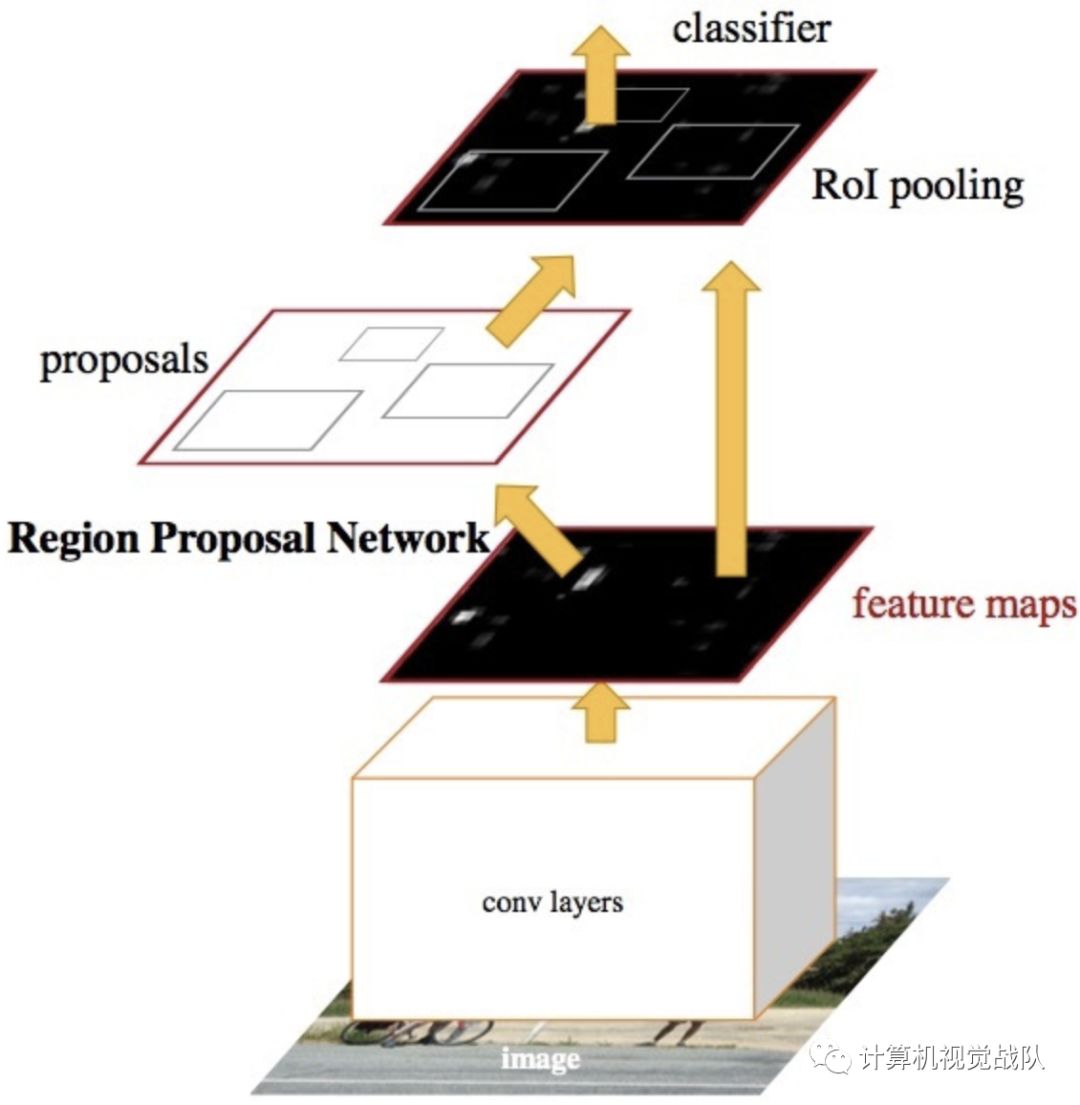
Faster R-CNN将proposals交给了CNN去生成,这样Region Proposal Network(RPN)应运而生。
Faster R-CNN
仔细看看Faster R-CNN框架,其实还保留了Fast R-CNN的框架,其主要就是CNN+RPN。其中RPN主要就是负责生成proposals,然后与最后一层的feature map一起使用,用ROI Pooling生成固定长度的feature vector。具体如下:
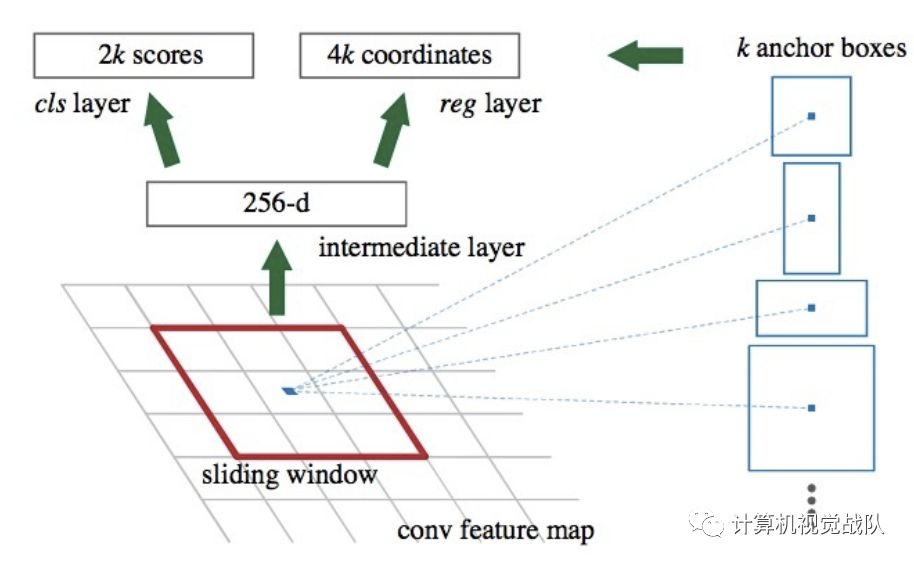
那接下来开始好好的说一下RPN和Anchor!下图是我从网络copy过来的,应该更加能理解整体的流程及内容。
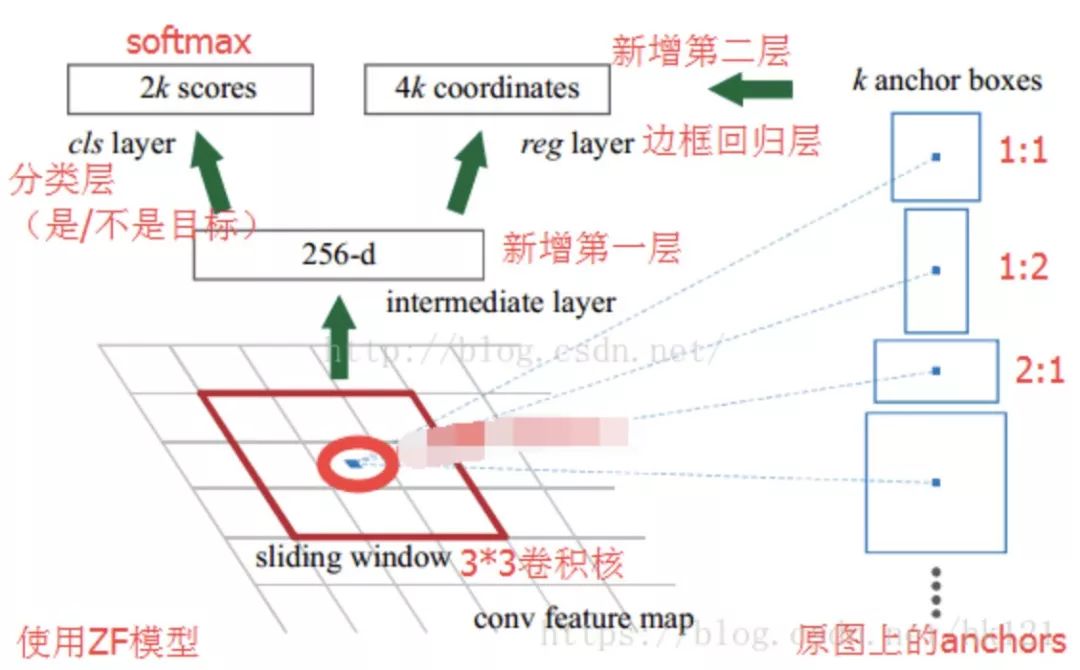
在上图中,红色的3x3红框是其中一个滑窗的操作过程,注意这里的Anchor是原图像像素空间中的,而不是feature map上的。这样的话,就可以很好去知道Anchor的意思,而且Anchor对于RPN非常重要。
现在,我们假设现在的feature map尺寸为W x H x C(13x13x256就是feature map的Width=13,Height=13和Channel=256),在feature map使用滑动窗口的操作方式,当前滑窗的中心在原像素空间的映射点就称为Anchor,并且以Anchor为中心去生成K(paper中default K=9,3个尺寸和3个缩放比例)个proposals。
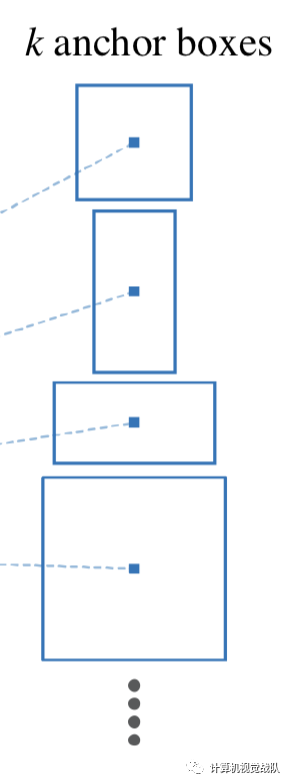
在feature map上滑动一次,得到一个小网络,该网络输入是3x3x256,经过3x3x256x256的卷积,就可以得到1x1x256的低维特征向量。
然后就得到上图的两个分支。
Classification:经过1x1x256x18的卷积核,得到1x1x18的特征向量,分别代表9个proposals的Object的概率(是或不是);
Regression:经过1x1x256x36的卷积核,得到1x1x36的特征向量,分别代表9个proposals的(长宽及中心点坐标)。
注意,上面只是一个小网络,也就是一个3x3滑窗的过程及结果,在网络整体运行的过程中,要将整个feature map都要滑动一遍,最终就会得到两个损失函数:
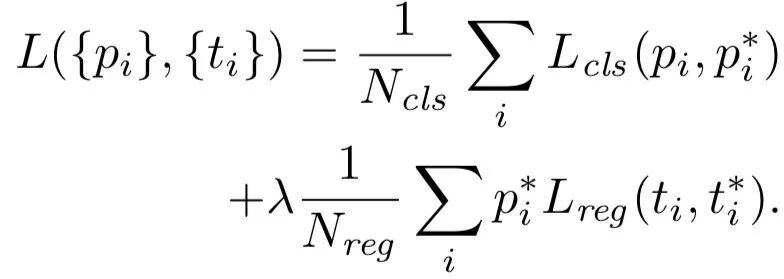
其中就是Classification(Lcls)和Regression(Lreg)两个损失。对于边界框的回归,其是采用以下4个坐标的参数化:
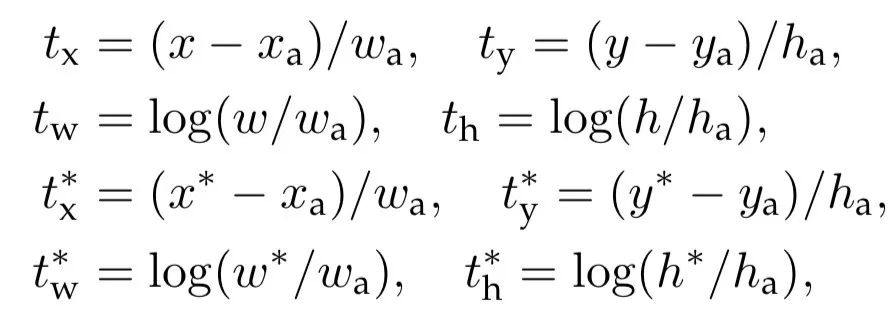
综上,通过滑窗和Anchor机制就可以找到固定比例、一定大小的proposals,这样RPN就可以完美替代低效的Selective Search去产生proposals。

最终,在目标检测领域中,这个框架算是一个里程碑,值得大家学习与深入探索。最后的检测结果也是不错的。

如果想加入我们“计算机视觉战队”,请扫二维码加入学习群。计算机视觉战队主要涉及机器学习、深度学习等领域,由来自于各校的硕博研究生组成的团队,主要致力于人脸检测、人脸识别,多目标检测、目标跟踪、图像分割等研究方向。




