南大发布首篇《健壮深度半监督学习》综述论文,全面阐述现有RDSSL中分布、特征与标签损坏方法体系与进展
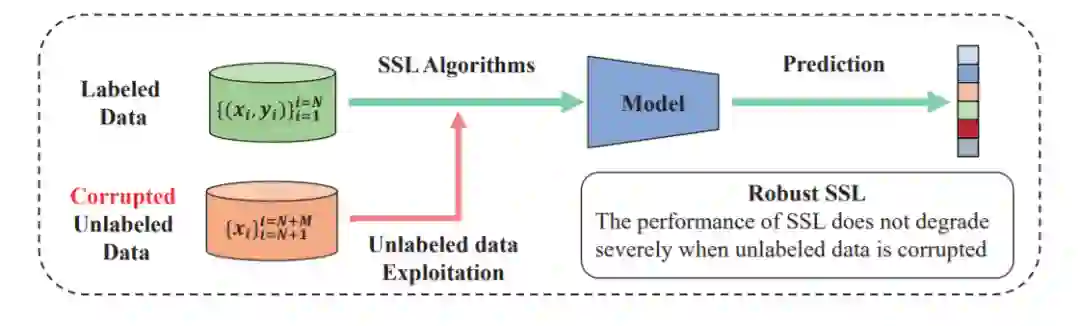
半监督学习(Semi-supervised learning, SSL)是机器学习的一个分支,其目的是在标签不足的情况下利用未标记的数据来提高学习性能。南京大学李宇峰团队发布首篇《健壮深度半监督学习》综述论文,探讨了学习分布损坏、特征损坏和标签损坏的未标签数据方法体系。

https://arxiv.org/abs/2202.05975
-
我们瞄准了关键但却被忽视的健壮SSL问题。 从机器学习的角度,给出了健壮SSL的形式化定义。 该定义不仅具有足够的普遍性,可以包括现有的健壮SSL方法,而且具有足够的特殊性,可以阐明健壮SSL的目标是什么。
-
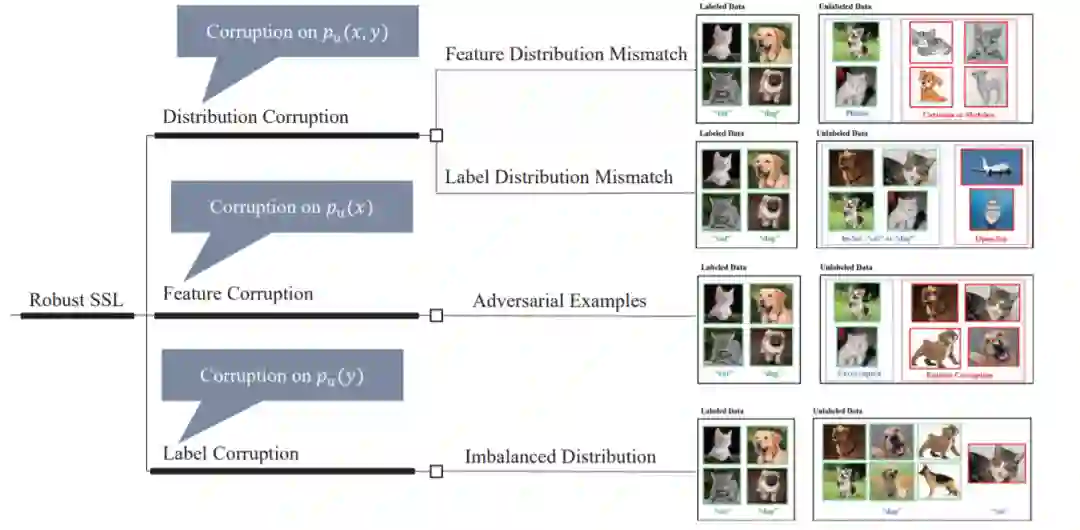
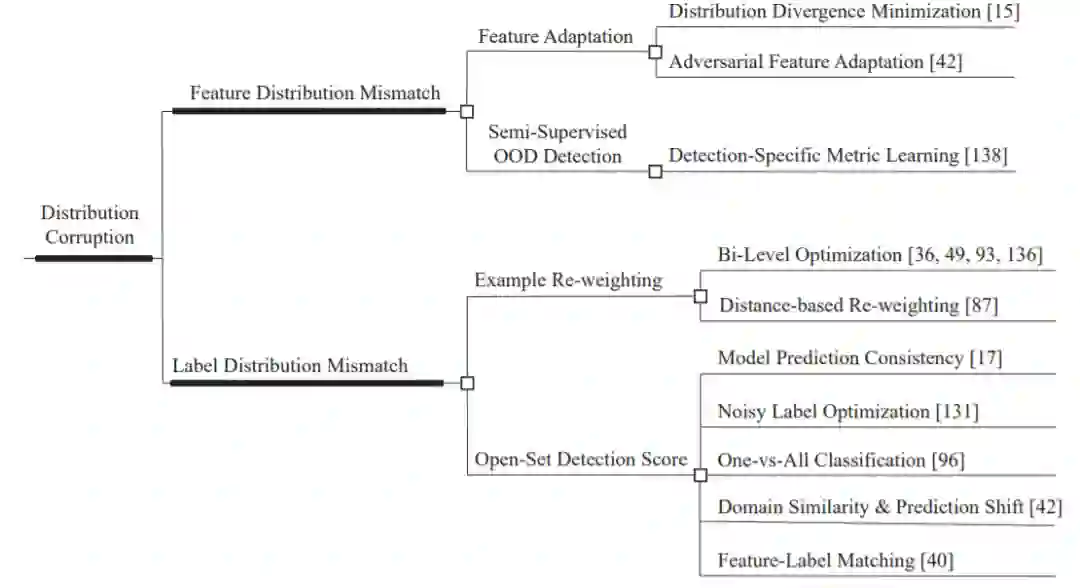
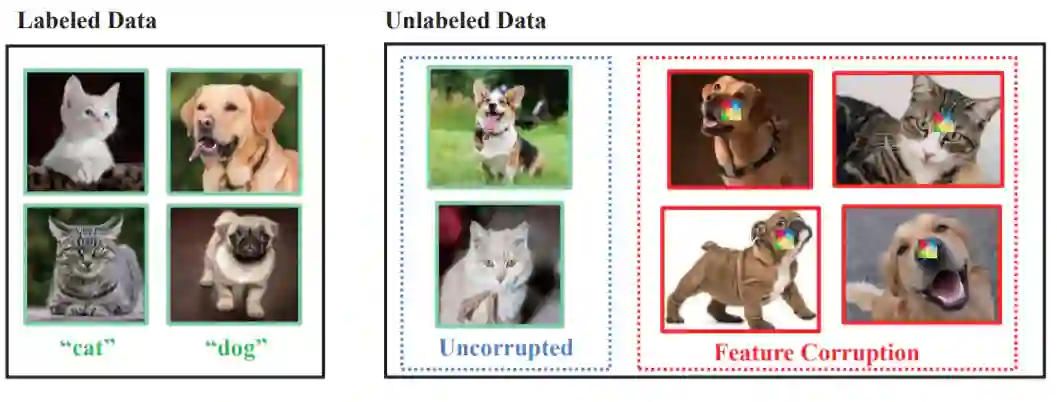
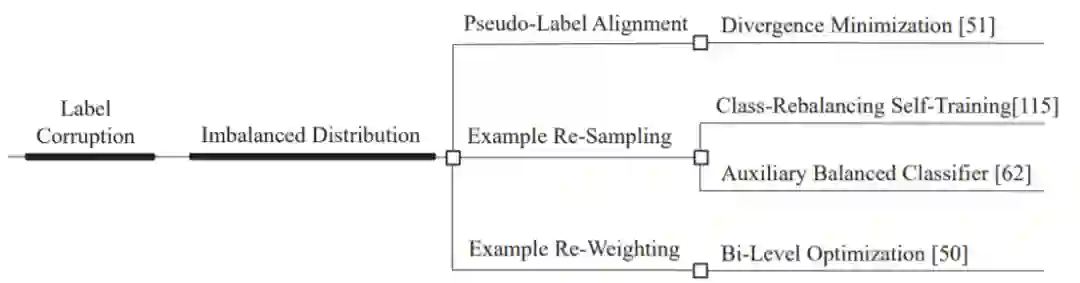
我们指出,无标签数据损坏是对SSL的健壮性威胁,并提供了一个完整的分类无标签数据损坏类型,即分布损坏、特征损坏和标签损坏。 我们给出了每个问题的形式化定义和标准化描述。 这有助于其他研究人员清楚地理解健壮的SSL。 -
对于每一种健壮性威胁,我们都对最近构建健壮SSL模型的工作进行了全面的回顾。 他们的关系,pros, and cons也被讨论。 您可以很快掌握健壮SSL的前沿思想。 -
在现有的健壮SSL研究之外,我们提出了几个有前景的未来方向,如健壮的通用数据类型,健壮的复合弱监督数据,健壮的SSL与领域知识,在动态环境中学习,以及构建真实的数据集。 我们希望它们能够为健壮的SSL研究提供一些见解



专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“RDSL” 就可以获取《南大发布首篇《健壮深度半监督学习》综述论文,全面阐述现有RDSSL中分布、特征与标签损坏方法体系与进展》专知下载链接



登录查看更多
相关内容

Arxiv
16+阅读 · 2021年5月26日
Arxiv
100+阅读 · 2020年2月20日



相关VIP内容
相关资讯
相关论文
Arxiv
16+阅读 · 2021年5月26日
Arxiv
100+阅读 · 2020年2月20日