本文作者:邓淑敏,浙江大学在读博士,研究方向为低资源条件下知识图谱自动化构建关键技术研究。
![]()
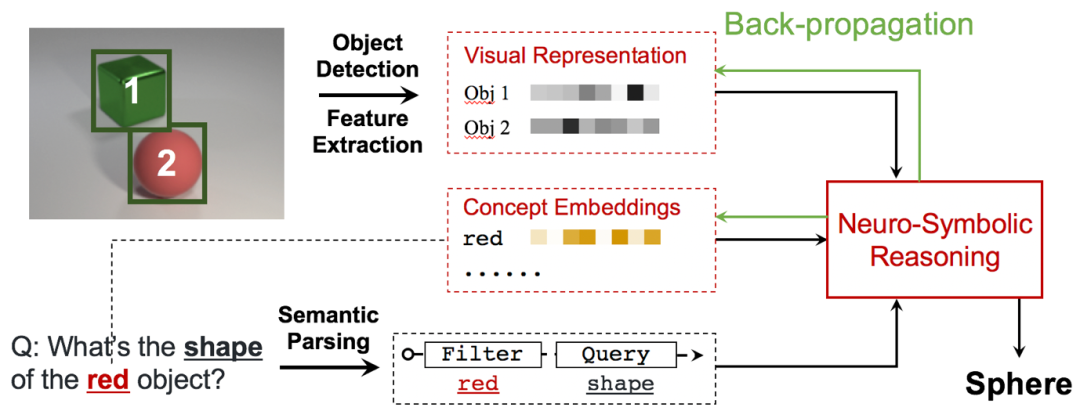
深度学习的高速发展使得模型的表达能力逐步完善,在一些感知任务(例如动作识别和事件检测)上取得了显著成果。但是,如果要开发真正的智能系统,需要弥合感知与认知之间的鸿沟。高度认知的任务,例如抽象,推理和解释,与符号系统紧密相关,但是通常无法适应复杂的高维空间。神经符号计算将深度模型的优势与符号方法相结合,从而显著了减少符号方法的搜索空间。基于此,本文主要介绍一些神经符号推理在自然语言处理中的应用及方法,主要涉及的任务是复杂问题问答,即给定问题(一般是复杂问题),从context中推理答案,context是文本(textQA)或者图片(VQA)。这里引入VQA,是由于目前神经符号推理在纯文本问答中的应用工作有限,但本质上这两种问答任务中的符号推理过程差不多。下面给出复杂问题问答的例子。
![]()
如图1所示,这里的问题可以拆成几个子问题,且必须通过推理才能得到答案。这就非常适合用神经符号推理的方法来解决。解决这类问题需要:理解问题在蕴含答案的文本/图片中做信息抽取符号推理。
接下来我将结合4篇论文简述神经符号推理的方法。
Neural Module Networks for Reasoning over Text
论文链接:https://openreview.net/pdf?id=SygWvAVFPr
这篇文章提出用神经模块网络(NMN)去解决复杂问题问答的任务。先将问题解析成logical form,用强监督的方式将问题转换成结构化的功能模块,然后在蕴含答案的文本中运行这些模块。这里的模块可看成用于推理的可学习的函数,每个模块都是定制的,从离散的定制神经模块集合中可以组成特定于问题的神经网络。
总体来看,复杂问题问答包含的推理可分为两大类:自然语言推理和符号推理。自然语言推理可以看成是文本信息抽取的过程,符号推理就是基于抽取出的结构化知识进行推理判断。这两大类推理中定义的模块如图2所示。
![]()
下面看一个用神经模块网络解复杂问题问答的例子。
第一步:将问题解析成logical form。
![]()
图3. NMN将问题解析成logical form
第二步:在蕴含答案的文本中执行模块。
(1)NMN执行第一个模块:find(),找出得分(touchdown pass)这个实体
(2)NMN执行第二个模块:find-num(),找出得分的数值
(3)NMN执行第三个模块:max-num(),找出最大的得分值
(4)NMN执行第四个模块:extract-argument(),找出得到最大得分的人(这个模块类似于事件抽取中的argument extraction)
那接下来的问题就在于,如何得到这些模块的组合序列,以及如何学习出这些模块。组合这些模块目前主要用一些seq-to-seq的模型,至于学习这些模块,则是用基于attention的方法,模块的输出是权重的分布。
以学习find()模块为例。问题的嵌入用Q表示,蕴含答案的文本嵌入用P表示,find(Q)->P,输入问句的tokens,输出蕴含答案的文本中和输入tokens相同或相似的token分布,如图4所示。
![]()
Compositional Attention Networks for Machine Reasoning
论文链接:https://openreview.net/pdf?id=S1Euwz-Rb
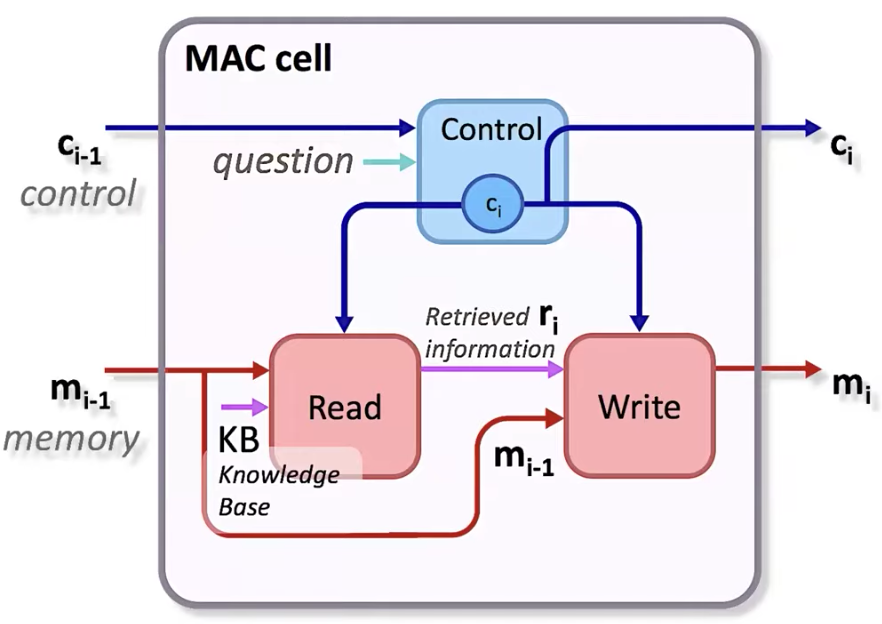
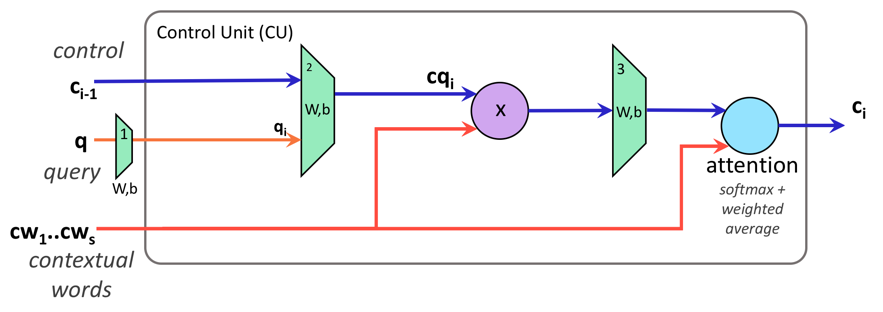
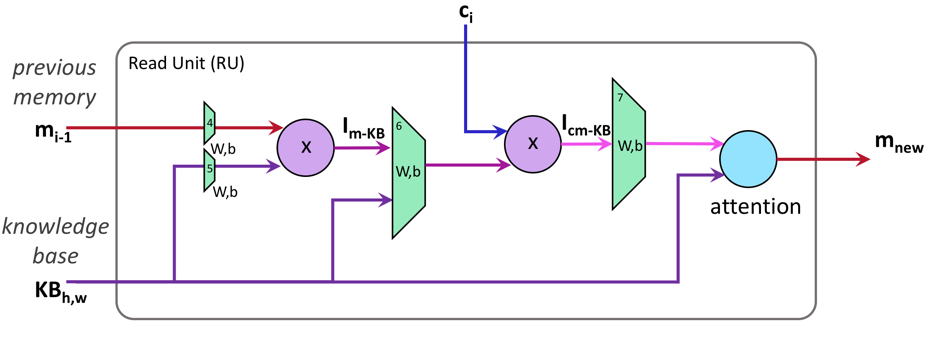
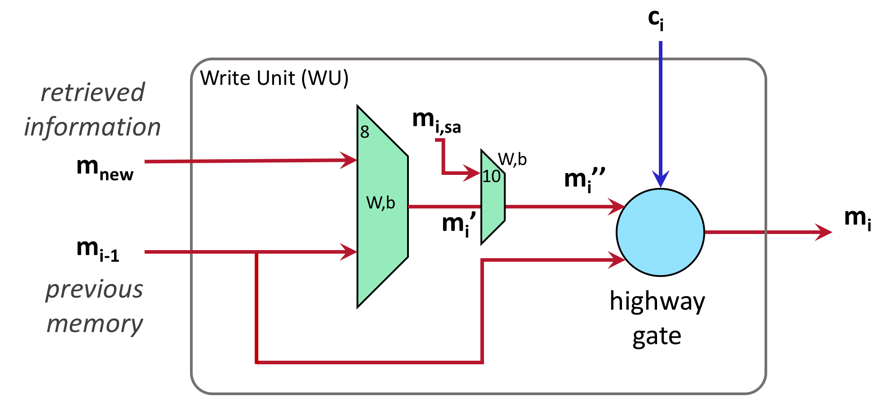
这篇文章提出了MACnet模型去解决VQA任务。MAC,即Memory,Attention,Composition。MACnet是MAC cell的soft-attention序列。一个Mac cell由控制单元、读单元、写单元构成,如图5所示。
![]()
图5. MAC cell内部结构
控制单元负责计算出一个控制状态,通过在问题上实施注意力机制抽取出一个指令。
给定当前的控制状态和当前的记忆信息,读单元负责从图片(KB)中检索信息。
与NMN模型中的模块相比,MAC cell更为通用且功能更为齐全,因为MAC cell可以重复使用。所有cell共享架构和参数,而且可以和蕴含答案的文本/图片适配,完全端到端的设计而且可微,cell之间通过一个基于注意力的架构相联系。
NMN中的模块是离散的而且是任务定制的,每个模块拥有特有的离散参数甚至是特有的架构。
Learning by Abstraction: The Neural State Machine
论文链接:https://papers.nips.cc/paper/8825-learning-by-abstraction-the-neural-state-machine.pdf
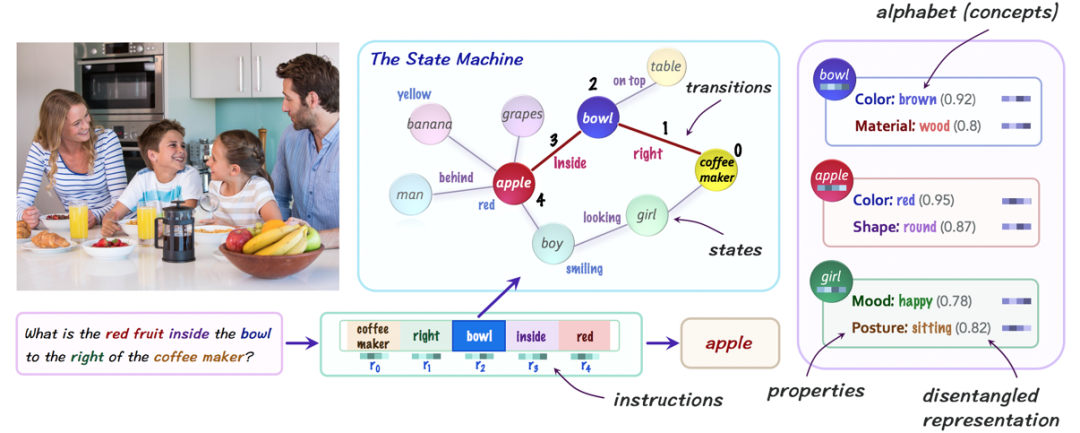
这篇文章提出神经状态机(Neural State Machine,NSM)去解决VQA任务。NSM是一种结合符号主义和连接主义的模型,旨在抹平符号主义和连接主义之间的鸿沟,并对二者进行优势互补,从而更好地完成视觉推理任务。
NSM将问题文本中的词和蕴含答案的图片全部映射为相同语言的嵌入概念,这些概念可以是对象,属性,关系。针对蕴含答案的图片,NSM通过有监督(预训练)的方式,基于图片中的概念构造一个概率图。针对问题文本,NSM会通过基于注意力机制的encoder-decoder模型,将文本翻译成一系列的指令,这些指令也被定义为概念。
然后,NSM对概率图进行时序推理,并迭代遍历其节点,以回答给定问题或者推理得出新结论。这里的推理也是基于注意力机制的,有点类似MACnet,不同的是,表示方式是scene graph(基于图片翻译出的图,如图9中间部分)上的概率分布。
相较于大多数神经架构中感知数据密切交互, NSM 模型在一个抽象的隐空间中运行,将视觉和语言模态转化为基于概念的表征,所以增强了模型的透明性和模块性。而且,NSM模型在多任务场景下具有强大的泛化能力,包括概念的全新组合、答案分布的变化和之前未观察到的语言结构。
The Neuro-Symbolic Concept Learner: Interpreting Scenes, Words, and Sentences From Natural Supervision
论文链接:https://openreview.net/pdf?id=rJgMlhRctm
这篇文章提出神经符号概念学习器(NS-CL)去解决VQA任务。通过从配对的图片、问题、答案三元组中联合学习,在“视觉概念”和“对应的文本语义”之间建立起关联。从而学习出(1)对图片的视觉感知,(2)对视觉概念(如颜色、形状、材质)的表示,(3)对问题的语义分析。
NS-CL的学习准则:1、使用神经符号推理明确显示概念的视觉基础。2、通过发展的课程联合学习概念和语言。模型主要分为三部分:
视觉感知模块,负责从图片场景中提取对象的表示。使用预训练的 Mask R-CNN 和 ResNet-34 来为场景中的每一个Object获取一个表示。由于需要获取到Object在场景中的位置信息,在表示单个Object的时候,同样需要将整个场景作为Context编码进去。由此,场景中的每一个对象都被编码成了一个固定维度的向量。
语义分析模块,负责将自然语言问题翻译成一个程序,程序是由领域特定语言(Domain Specific Language, DSL)中的操作来定义。进行视觉推理需要获取每个对象的属性(例如颜色、形状等),而每个属性类别(Attribute,例如:形状)可以有多个视觉概念(Concept,例如:红色、绿色)的取值。NS-CL将每个属性实现为一个神经网络操作(neural operator)。该操作接收Object的表示向量,将其映射到另一个特定于属性的向量空间中的向量,并且与视觉概念的向量进行相似度匹配,这些视觉概念的向量表示也是联合训练的。
程序执行模块,负责执行语义分析模块给出的程序,得到答案。这里采用了课程学习(Curriculum Learning)的训练方法,先让模型学习简单的例子,然后慢慢扩展到复杂的场景。而且程序执行模块对于视觉感知模块是完全可导的,两者均采用了基于概率的表示方法。
NS-CL可以从没有注释的语言中学习出视觉概念,而且这些概念是可学习的并且可以迁移到其他视觉任务中,此外,NS-CL很高效,且在少量数据上就可以达到不错的效果。
总而言之,这四种神经符号推理的方法各有千秋。在实际应用中,可以根据不同方法的优劣选择合适的神经符号推理模型。当然,神经符号推理的方法也不仅限于这4种,欢迎大家补充,和我们交流。
![]()

浙江大学知识引擎实验室
OpenKG
开放知识图谱(简称 OpenKG)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。
![]()
点击阅读原文,进入 OpenKG 博客。