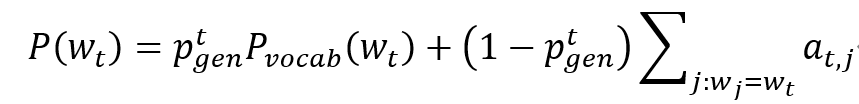![]()
(本文阅读时间:8 分钟)
编者按:数字信息时代人们获取新闻的方式越来越高效,但是获取新闻中关键信息的效率却很低。而 NLP 领域的新闻标题生成任务 (News Headline Generation)则可以基于新闻正文,自动生成包含关键信息的简短标题,使读者可以高效地获知新闻中的重要内容。
为了开展新闻标题生成任务的研究,微软亚洲研究院的研究员们构建了第一个可以离线评测个性化新闻标题生成方法的基准数据集:PENS(PErsonalized News headlineS)数据集;同时还提出了一种个性化新闻标题生成的通用框架,并且对其进行了效果评估。该论文 “PENS: A Dataset and Generic Framework for Personalized News Headline Generation” 已被 ACL 2021 收录。欢迎感兴趣的读者积极留言,交流感想!
在数字信息时代,由于文本信息的数量、传播速度都以指数形式增长,因此导致信息过载问题日趋严重。以新闻为例,每天新发布的新闻消息不计其数,用户难以在有限的时间内,从海量的新闻中筛选出感兴趣的文章进一步阅读,因而用简明的语言概括新闻的关键信息非常重要。在 NLP 领域,新闻标题生成任务(News Headline Generation)可以基于新闻正文,自动生成包含关键信息的简短标题,使读者高效地获知新闻中的重要内容。由于标题本身是对新闻正文的高度概括,因此生成标题的简洁性、流畅性和事实一致性,对该技术来说是一项挑战。
近年来,随着用户个性化服务的普及与人工智能技术的进步,新闻网站等内容平台希望通过标题来吸引读者的阅读兴趣,但同时又要避免“标题党”现象的发生。因此,生成个性化新闻标题成为标题生成领域的一个全新研究方向。
什么是个性化新闻标题呢?举个例子,有一篇报道篮球比赛的新闻,其潜在的用户受众通常是比赛球队的球迷。如果新闻标题不考虑用户的阅读兴趣,只是客观地描述比赛结果,那么输球一方的球迷进一步阅读这条新闻的概率可能较小,因为当他们看到标题时就已经知道自己支持的球队输了比赛,再具体了解输球过程的意愿就会相对较低。但是,如果考虑用户的阅读兴趣,对不同球队的球迷呈现个性化的标题(如图1所示),那么即使是输球方的球迷,可能也愿意去了解这条新闻的内容。比如,以球迷支持的球星为标题的核心词,突出球员的个人表现。
![]()
图1:个性化新闻标题的实例
个性化新闻标题生成任务的定义是:给定用户历史阅读行为数据和候选新闻内容,生成用户专属的不同新闻标题。生成的标题既要引起用户的阅读兴趣,提高用户进一步阅读、获取更高点击和阅读量的可能,又要兼顾新闻标题的事实一致性,保证用户的阅读质量,避免成为标题党。它有
两个重点子任务
:
①学习用户的个性化阅读兴趣:通过用户历史阅读行为信息,可以对用户的个性化阅读兴趣建模,从而学习用户的个性化表示;
②生成个性化新闻标题:将用户的个性化表示算法与新闻标题生成算法融合,实现为不同阅读兴趣的用户生成不同的新闻标题。
因此,以个性化标题展示的新闻,由于更能引起用户的阅读兴趣,进而可能获得更高的点击和阅读量,将成为新闻平台关注的新兴研究领域。
开展个性化新闻标题生成的研究,需要一个大规模的数据集,以开展离线评测。否则,当测试不同算法的表现时,研究者可能需要不断重复线上 A/B 测试,或者通过组织人工评价的方式来观察算法效果,不但实现成本高,而且公平性及可复现性均难以保证。
为了进一步研究个性化新闻标题的生成,微软亚洲研究院的研究员们构建了
PENS(PErsonalized News headlineS)数据集,该数据集是第一个离线评测个性化新闻标题生成方法的基准数据集
,且所有数据基于 Microsoft News 用户的匿名化新闻点击记录构建,同时包含了用户行为信息和新闻语料信息。
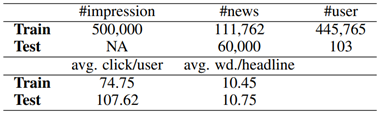
PENS 的新闻语料库包含了约11万则英文新闻文章,每篇新闻文章都由四部分内容组成:新闻ID、新闻标题、新闻正文和新闻类别标签。所有训练和测试数据中出现的新闻,都与语料库中文章的新闻 ID一一对应。
PENS 的训练数据集则包含了匿名用户的新闻曝光日志(Impression Log),其中包括44万名匿名用户的50万次新闻曝光日志,以及每名用户的历史点击信息。具体而言,每一条训练数据都由五部分内容组成:用户 ID、曝光时间戳、点击新闻列表、未点击新闻列表、用户历史点击新闻列表。所有列表中出现的新闻按首次曝光时间排序。
为了满足离线评测的需求,研究员们邀请了103名以英语为母语的高校学生(以下简称“标注者”),人工创建 PENS 的测试数据集。其构造过程分为两个阶段:第一阶段,每位标注者浏览1000条从新闻语料库中随机抽取的新闻标题,并从中选择至少50个自己感兴趣的标题,视为该用户的历史点击行为;第二阶段,每位标注者为另外200篇新闻正文撰写心中的理想标题。这些人工撰写的新闻标题由专业新闻编辑审查质量。低质量的标题会被删除(例如过长、过短或与正文不符),剩余合格的标题作为相应用户的个性化新闻标题的黄金标准。
研究员们认为,这些标注者虽然不具备专业的新闻编辑素养,但其人工撰写的标题能够充分反映他们的个性化阅读兴趣,因此可以作为测试时的“标准答案”。最终,这103名标注者构建的点击行为数据和撰写的2万多个个性化新闻标题构成了 PENS 的测试数据集。在此数据集上,个性化新闻标题生成方法可以采用文本生成中常采用的评价指标来评估其效果,如 BLEU、ROUGE 等。
![]()
表1:PENS数据集统计信息
![]()
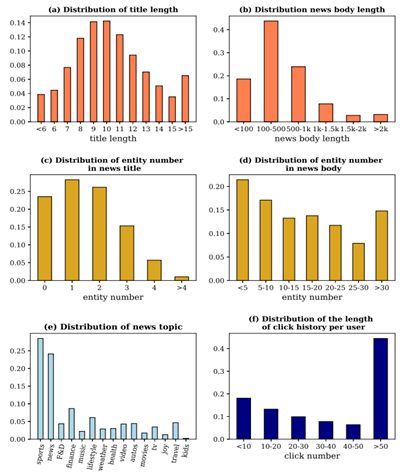
图2:PENS数据集新闻标题和正文长度分布(a,b)
标题和正文中实体数量分布(c,d)、新闻主题分布(e)和用户点击历史长度分布(f)
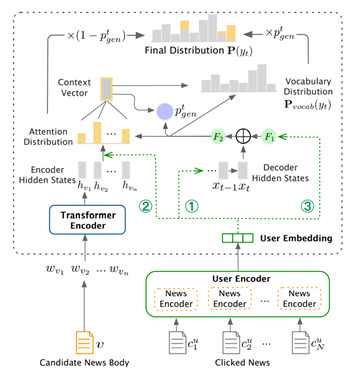
目前,还没有专门的方法来生成个性化新闻标题,为了填补这个空白,微软亚洲研究院的研究员们还提出了一种个性化新闻标题生成的通用框架。研究员们设计了一种以 Transformer 编码器和指针网络解码器为基本模型的新闻标题生成器,并提出了三种通过向基本模型注入用户个性化信息的方法,来生成个性化标题。框架的结构如图3所示:
![]()
图3:个性化新闻标题生成的通用框架
标题生成器,由 Transformer 编码器和指针网络解码器组成。Transformer 编码器编码候选新闻的文本信息,学习新闻正文单词的隐藏表示 h=[h_(v_1),h_(v_2),⋯,h_(v_n)]。在解码过程的第 t 步,指针网络解码器首先会采用注意力机制来计算当前隐藏状态 s_t 对新闻正文单词的注意力分布 a_t=[a_(v_1),a_(v_2),⋯,a_(v_n)];然后基于此注意力分布,加权求和得到上下文向量 c_t;最后,原始词汇表中每个单词生成的概率分布 P_vocab,以及选择原始词汇或直接复制新闻正文单词的指针 p_gen^t,可由 c_t,s_t 等参数得到。最后第 t 步解码词的总体概率 w_t 分布为:
![]()
用户个性化注入,所提出的框架共设计了三种形式:①将用户个性化表示( User Embedding ) 作为指针网络解码器的初始隐藏状态,进而实现影响生成词语的总体概率分布 P(w_t);②将 User Embedding 加入到对正文单词注意力分布 a_t 的计算中,区分不同用户对正文单词的关注程度,从而影响解码器从原文复制单词的概率分布 P_copy;③将 User Embedding 加入到 p_gen^t 的计算中,从而影响解码阶段的单词是来自词表生成还是来自正文复制。
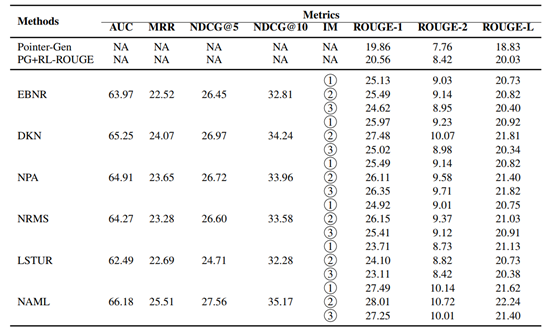
研究员们在 PENS 数据集上验证了该框架的效果。为了对比个性化与非个性化的差异,研究员们首先对比了两种代表性的标题生成方法:基本的指针生成网络(用 Pointer-Gen 表示)和用强化学习框架拓展的指针生成网络(用 PG+RL-ROUGE 表示)。由于论文中提出的框架并未限制用户表示的学习方法(它们通常可由个性化新闻推荐算法学习得到),因此研究员们采用了6种代表性的个性化新闻推荐算法:EBNR、DKN、NPA、NRMS、LSTUR 和 NAML。这6种个性化新闻推荐算法按照本文框架中的三种注入方式,分别注入研究员们提出的标题生成器,从而可以得到18种具体的个性化新闻标题生成方法。
评价指标上,实验以 AUC、MRR、nDCG@5 和 nDCG@10 作为用户兴趣建模性能的评价指标,以 ROUGE-1,ROUGE-2,ROUGE-L 的 F1 均值作为个性化标题生成质量的评价指标。这里采用 ROUGE 系列指标是因为研究员们更关注召回率,即用户撰写的标题内容出现在生成结果中的比率。对比结果请见表2。
![]()
表2:实验结果(IM指用户个性化表示的注入方式)
①所有个性化新闻标题生成方法的表现都优于普通标题生成方法。这是因为该方法能够根据学习到的用户兴趣来生成个性化的新闻标题,个性化标题与用户撰写的新闻标题具有更高的相似度。通过表3的样例所示,该个性化标题生成方法可以从用户的历史点击行为中捕捉到个性化阅读兴趣的信息,并根据不同用户的兴趣,为同一篇新闻生成不同的个性化标题。
![]()
表3:个性化标题生成样例
②用户的个性化建模方法在个性化标题生成任务中起到了重要作用。更好的用户建模方法可以从用户行为历史中获得更丰富的个性化信息,进而生成更好的个性化标题。如 NAML 方法在用户兴趣建模的4项指标上均得到了最高分,同时也在3种个性化注入方式中取得了最高的 ROUGE 分数,这意味着该方法生成的个性化新闻标题质量更好。
③第二种用户兴趣注入方式在大多数用户建模方法中表现最好。这可能是因为用户的阅读兴趣很可能具体表现为对正文中的人名、地名、事件等重点信息的关注,这些单词有更大的概率是通过指针网络解码器中的拷贝机制生成至标题中的,所以让用户兴趣表示直接去影响从正文复制单词的概率分布,也许是最直接、有效的一种方法。但是第二种方式并没有在所有用户建模方法中达到最佳效果(如 NPA、LSTUR)。因此,更好的用户个性化注入方式还有待进一步探索。
本文针对个性化新闻标题生成进行了研究,并构建了名为 PENS 的数据集,这是第一个可以采用离线方式评测个性化新闻标题生成方法的基准数据集;此外,研究员们还提出了一个通用的个性化新闻标题生成方法框架,以三种不同的方式将用户兴趣注入到编码器-解码器结构的标题生成器中,用于生成个性化新闻标题。最后,研究员们也比较了用户建模和标题生成的 SOTA 方法,用以提供 PENS 的基准分数。结果表明,该提出的方法及通用框架均达到了满意的效果,不过目前仍存在一些问题,更好的用户个性化注入方式还有待进一步探索。
https://www.microsoft.com/en-us/research/publication/pens-a-dataset-and-generic-framework-for-personalized-news-headline-generation/
https://msnews.github.io/pens.html
8月4日(今天),我们将邀请微软亚洲研究院自然语言计算组实习生徐毅恒和闫坤在 ACL 2021 分享专场中,为大家深度解读论文,届时欢迎大家扫码观看。
你也许还想看:
![]()