美国重夺全球超算第一!人类实现百亿亿次E级超算,Frontier屠榜全球Top500

新智元报道
新智元报道
编辑:好困 David 袁榭
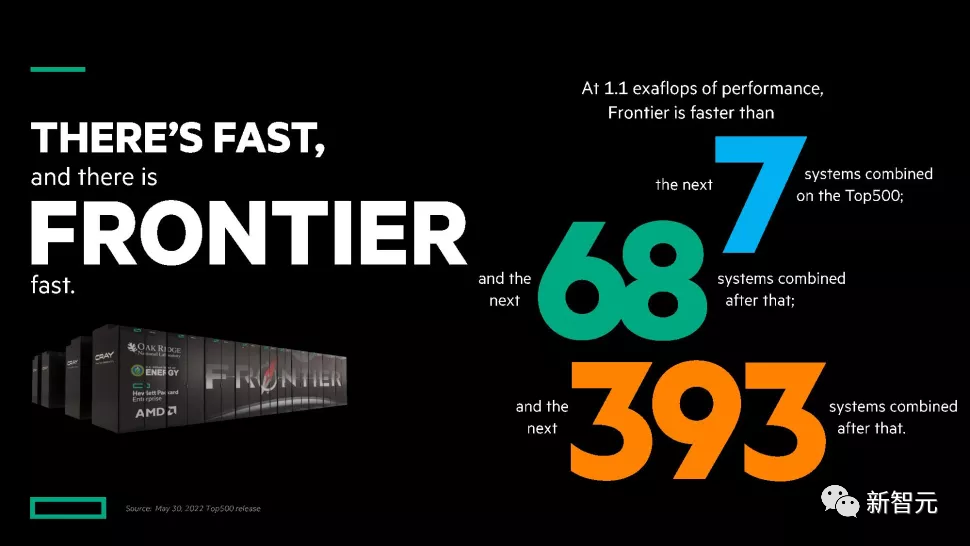
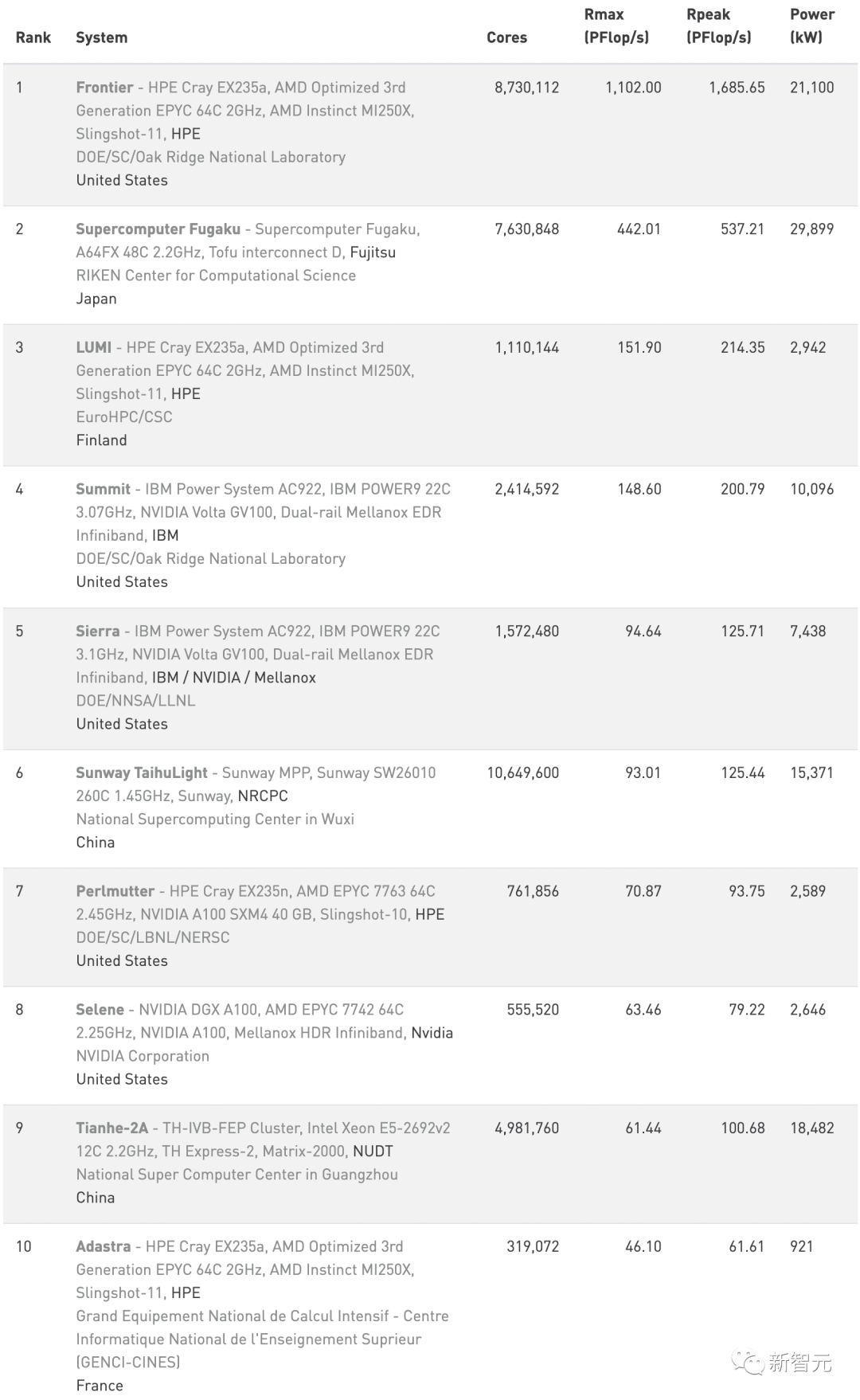
【新智元导读】最新超算Top500榜单揭晓!美国的性能怪兽Frontier以横扫之势拿下第一,算力超过身后468台的总和。
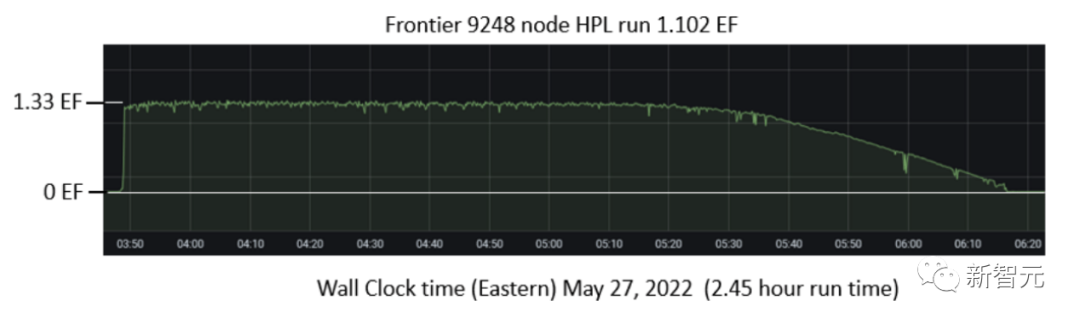
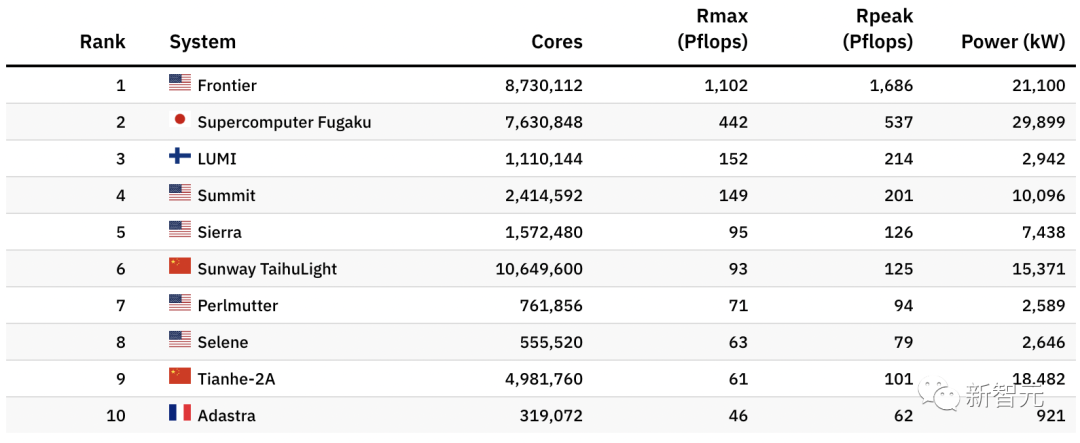
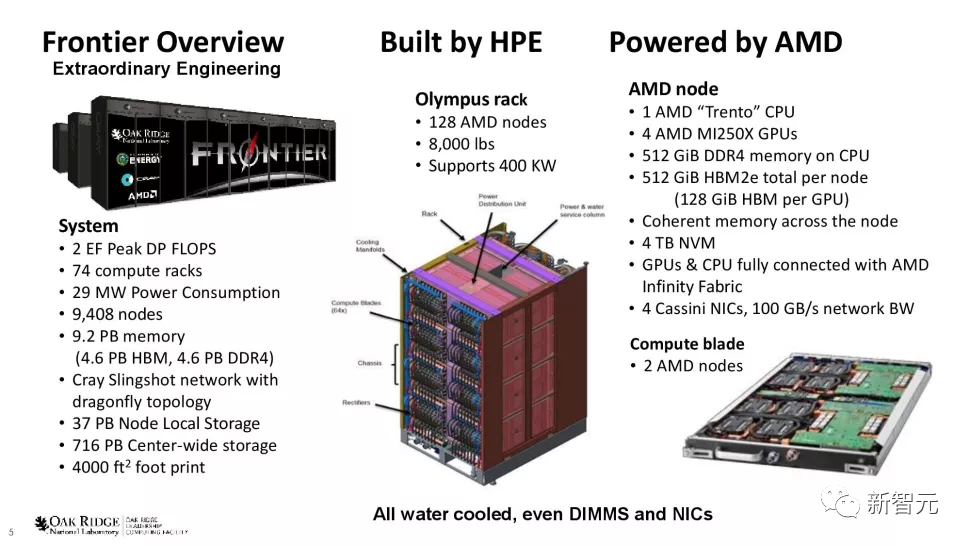
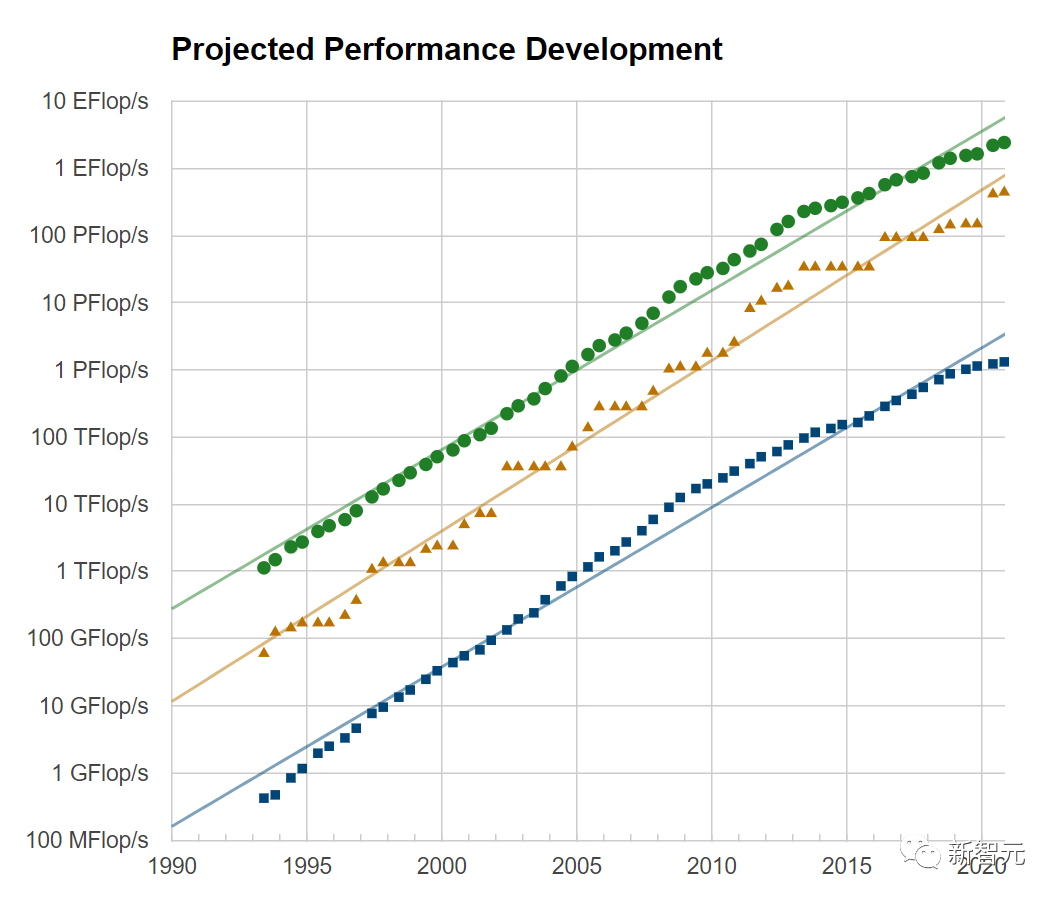
Frontier:突破百亿亿次
Frontier:突破百亿亿次




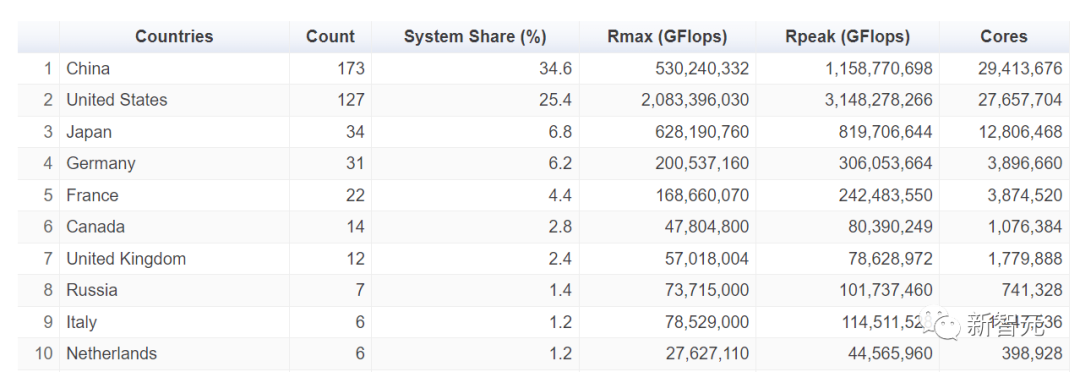
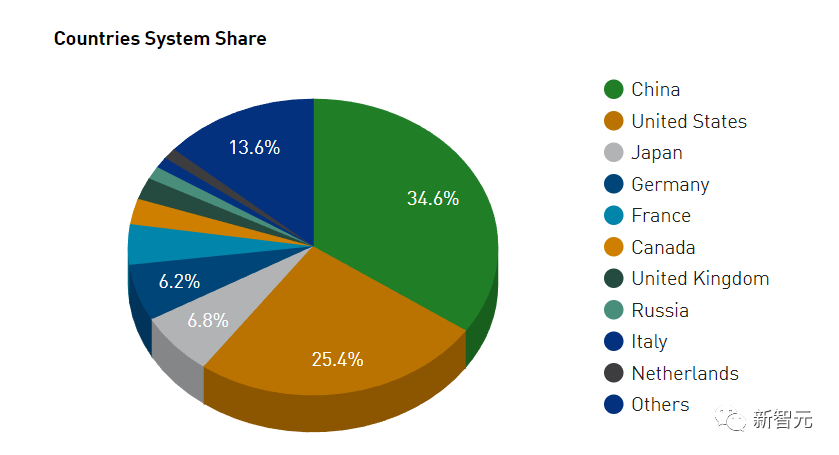
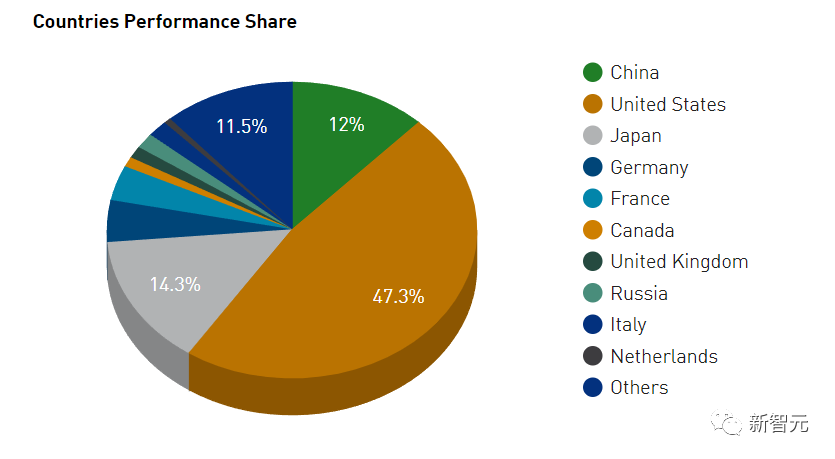
中国:玩你们的,我就看看
在新一期榜单上,中国和美国仍然是上榜最多的国家。
中国:玩你们的,我就看看
欧洲崛起:Top10占据7席
美国并不是唯一取得显著成绩的地区。
欧洲也表现良好,从总排名上看,美、中、日占据前3,前十中剩余的七席则全部为欧洲国家占据。
欧洲崛起:Top10占据7席
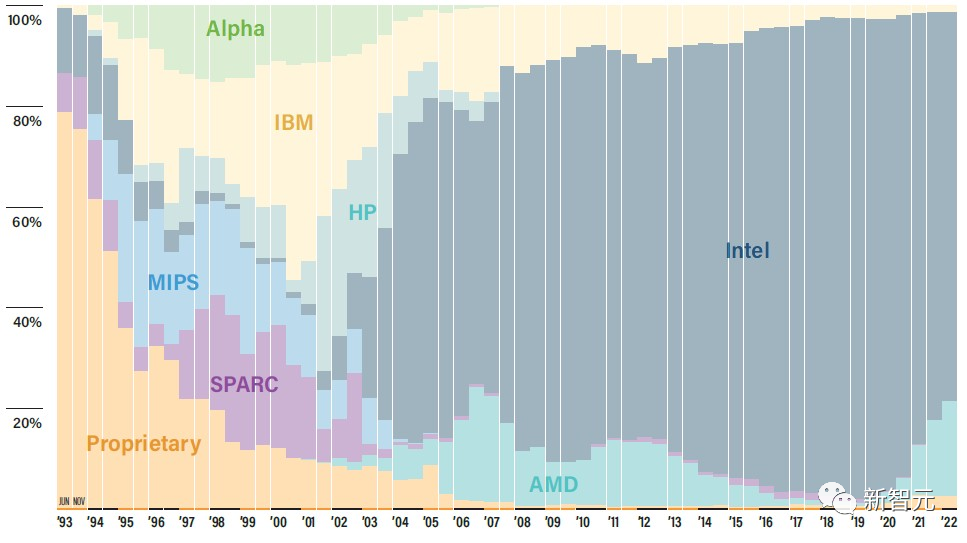
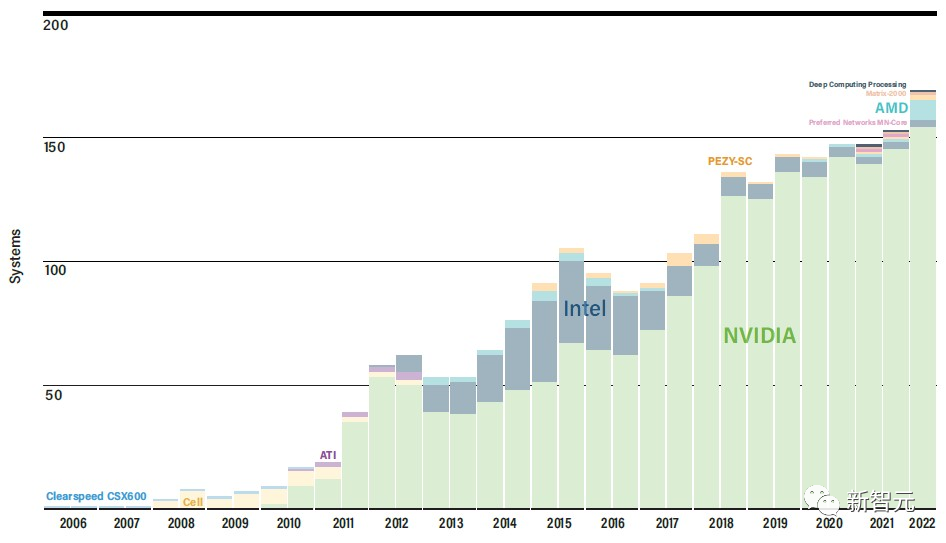
为啥不用GPU加速:还是差钱
长
久以来,AMD第一次在Top500中的系统内的主机CPU中占有代表性的份额,但英特尔至强处理器仍然占主导地位。
为啥不用GPU加速:还是差钱
参考资料:

登录查看更多
相关内容
Arxiv
0+阅读 · 2022年7月26日
Arxiv
0+阅读 · 2022年7月25日
Arxiv
16+阅读 · 2020年3月30日



相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2022年7月26日
Arxiv
0+阅读 · 2022年7月25日
Arxiv
16+阅读 · 2020年3月30日