TPUv4开放使用!谷歌新一代TPU性价比有多高?

新智元报道
新智元报道
【新智元导读】性能比TPUv3提高2.23倍,价格只涨61%
谷歌如今能保持人工智能领域霸主地位,很大程度上依赖于自主研发的TPU。
自去年开始,谷歌就开始不断放风TPUv4,在论文中描述新一代TPU的架构设计,从前几代TPU设计中不断吸取经验。

5月19日,谷歌正式推出新一代人工智能ASIC芯片TPUv4,运算效能是上一代产品的2倍以上,由4096个TPUv4单芯片组成的pod运算集群,可释放高达1exaflop(每秒10的18次方浮点运算)的算力,超过了目前全球运算速度最快的超级计算机。
前段时间谷歌发布的5400亿参数语言模型PaLM就是用两个TPUv4 pods训练了大约64天得到的。
10月11日,谷歌举办Google Cloud Next 2022大会,正式面向大众开放第四代TPU使用权限。

有外媒记者与TPU的幕后人员进行深入交流,并研究大量的论文和技术报告后,写成了一篇TPUv4最全面、深入的报道,对第四代TPU的计算引擎及其相关系统进行概述。
第四代TPU
第四代TPU
早在2013年,当谷歌正在为Google搜索引擎开发语音激活搜索功能时,谷歌研究员Jeff Dean在一张废纸上做了一会数学计算,发现如果这种人工智能辅助搜索投入生产,那么谷歌将不得不将其数据中心的规模扩大一倍。
题外话,Jeff Dean参与了许多谷歌的关键技术开发,包括谷歌的网络爬虫、索引、查询系统、AdSense、谷歌翻译的设计与实现、TensorFlow等等。

扩容数据中心对于一个「免费」的产品来说,并不会让搜索广告客户突然增加两倍,因此,谷歌必须努力为人工智能训练和推理建立一个更好的数学引擎。
TPU的目标是在一个特定领域对芯片进行体系结构设计,在去年发布的一篇论文中,谷歌详细介绍了TPUv4i的各项参数及性能,专门为推理进行调整优化,其中i就代表了推理。

论文链接:https://www.gwern.net/docs/ai/2021-jouppi.pdf
事实证明,TPUv4i推理芯片的生产大大领先于TPUv4通用引擎,其生产方式与Nvidia相反,这也表明了一个事实:谷歌真的非常需要廉价的推理引擎来驱动数十个应用程序,有TPU加持的人工智能可以扩展到更丰富的应用场景。
Google并没有准确的时间表报告何时将完整TPUv4的系统投入生产,据猜测大约是在2021年第四季度。
谷歌并不耻于在TPU设计上多留下一两个节点,这样做反而可以保持芯片设计和生产的低成本。
前沿计算引擎的成本很大一部分来自于高精尖设计工艺的不良率,虽然可以通过在设计中添加备用组件来降低成本,但是这同样也是有成本的。
而具有多个向量的芯片更便宜,也更容易通过供应链进入谷歌手中。
TPUv4i 推理晶片采用台积电公司的七纳米工艺制造,一年半前投产,作者猜测通用的TPUv4也是采用同样的七纳米工艺。

并且作者预测TPUv5i和TPUv5计算引擎将会采用5纳米进程,几乎可以肯定的是,这些引擎即将开始测试了,如果Google生产了 TPUv4i和TPUv4,以及 Google Cloud上的客户能够普遍使用 TPUv4的话。
TPU 核心的基本结构是,它有一个标量和并行向量处理机的前端,带有一个自主开发的矩阵数学单元,可以进行 BF16(谷歌为其 TPU 发明的一种格式)乘法和 FP32累加运算(有时还可以根据模型进行 INT8推理)。
最初的 TPUv1处理器有一个256 × 256的矩阵数学单元,这个单元非常庞大,而且正如 Google设计过程中改进的,这并不是最佳配置。
事实证明,谷歌自己的人工智能应用程序也不是64 × 64的数组。
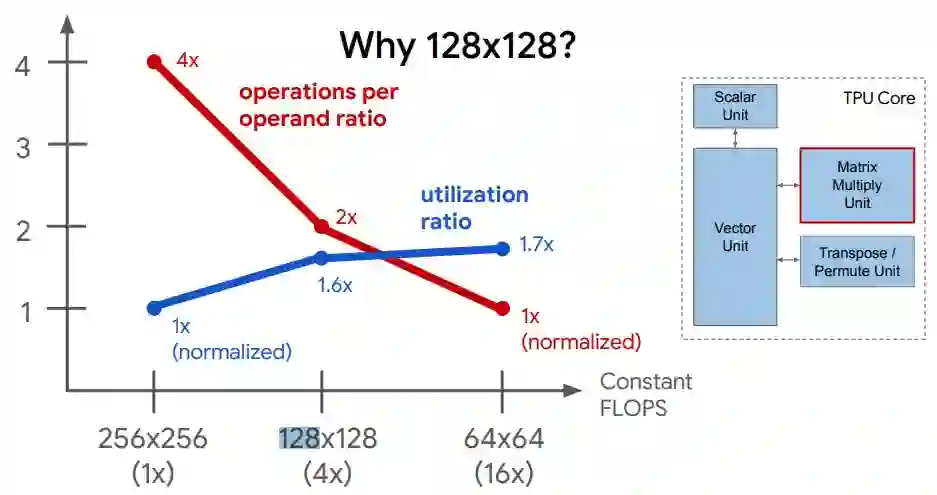
矩阵吞吐量和利用率之间的最佳点是128 × 128数组,至少对于 Google 自己的代码来说是这样的。
Google发现了这一点之后,公司通过增加TPU核心(其中嵌入了 MXU 单元)或者在每个核心中增加 MXU 单元来扩大 TPU 的规模。
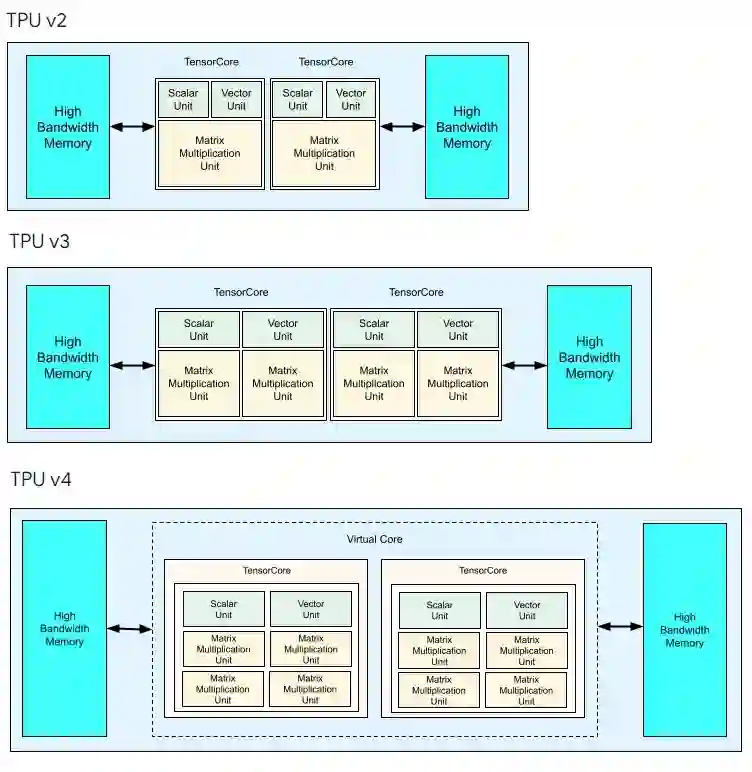
为了实现这个配置,每一代TPU的服务器板的样式都有变化。

在 TPUv4服务器板的右侧,可以看到一些相邻的芯片。这是一个6端口6 Tb/秒的交换机作为网络接口卡和3D 环形曲面网络(torus network)的基础。
刚听到TPUv4芯片消息的时候,大家并不确定Google是否会增加内核或者扩展 MXUs,而事实证明,Google一直将内核数量保持在2,并且再次将每个内核内的MXUs数量翻了一番。
除非有什么变化,否则这也将是Google创建TPUv5、 TPUv6等所有后代的设计方式。
在某个时候点,谷歌采用四核心取决于其自主开发的XLA机器学习编译器能做什么,但目前,提供更少数量的核是扩展应用程序最简单的方法。
可以注意到,TPUv4i 推理芯片本身就相当强大,单个TPU 核心就有四个128 × 128 MXU,运行频率为1.05 GHz,但只占用了400平方毫米的面积。

根据一些平面图估计,在单个内核上将 MXU 计数增加一倍,缓存也增加一倍,并添加一些其他的非核心特性来创建单个内核的全功能 TPUv4,可能只会将芯片尺寸增加到563平方毫米左右。
但是不管出于什么原因,可能与 XLA 编译器中双核 TPU 的优化有关,Google 做了一个双核心TPUv4 AI训练引擎,它的面积大约在780平方毫米左右。
可以看到,这两个核心TPUv4芯片表现为一个逻辑核心,一个32GB HBM 内存空间。
所以有理由怀疑它是一个整体设计,但它可能是由两个 TPUv4芯片捆绑在一个插口(socket)上,可以降低成本,但可能影响性能,具体取决于插口内互连。
中杯、大杯、超大杯
在过去三代TPU核心中,考虑向量规模的话,TPUv3是对TPUv2的一次渐进式「中年升级」,在输入和速度上提高了30%左右,在同样的16纳米工艺下 ,晶体管数量和芯片尺寸只有名义上的11%增加,芯片性能提高了2.67倍,HBM 主存容量提高了2倍(可以输入更大的数据集)。
除此之外,最大的区别在于2D 环面互连从 TPUv2芯片中的256个芯片扩展到TPUv3代中的1024个芯片,这也导致pod处理能力增加了10.7倍,从12petaflops增加到126petaflops(在 BF16操作中测量)。

TPUv4是计算引擎的真正升级,进程从16纳米缩小到7纳米,并且具有其他所有优点:MXU 的数量再次增加了一倍,缓存内存增加了九倍达到244 MB,HBM2内存带宽增加了33%到1.2 TB/秒,但有趣的是,HBM2内存容量保持在32 GB。
谷歌之所以能够做到这一点,是因为它可以疯狂地扩展TPUv4 pods,比如Nvidia 吹嘘自己可以将多达256个Hopper GH100 GPU与其NVSwitch结构紧密耦合,但新的3D 环面互连首次与带宽更大、基数更高的 TPUv4连接,可以将4096个TPUv4引擎紧密耦合在一起,总计达到1.126 exaflops 的 BF16计算。
其中8个 TPUv4 pods位于谷歌俄克拉荷马州梅斯县的数据中心,能够产生9 exaflops的原生人工智能计算速度。
TPUv4 总览
TPUv4 总览
谷歌云 TPU 产品的出境产品经理Vaibhav Singh表示,在大部分情况下,工程师使用64个芯片,甚至更少,TPUv4做的一件有趣的事情是多维数据集级别的环绕连接,其中一个多维数据集的单位是四乘四乘四,因为就最常见的工作负载大小而言,这也是最优的尺寸。
从而可以构造出由四乘四乘四组合而成更大的切片。
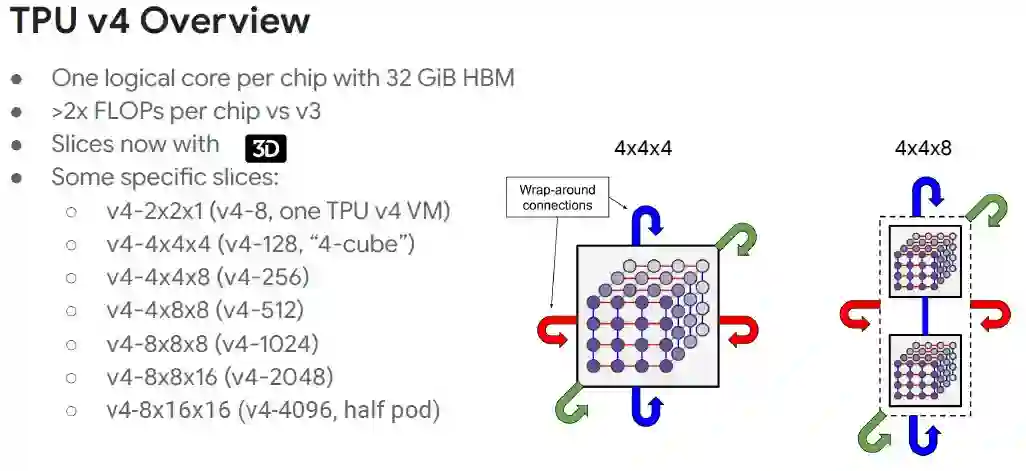
在上面的表格中,立方体切片的大小是计算核心,而不是芯片,切片大小是动态配置的。
Singh还补充道,当我们讨论的模型不适用于单个芯片,必须分布在数百个芯片上时,对物理拓扑结构的认识,以及你的软件在计算和通信重叠方面实际上尝试进行某些优化后,会对系统的整体性能产生巨大的影响。
高性能计算机用户非常清楚3D 和更高维环形互连的好处—— IBM 的 BlueGene 超级计算机有一个3D 环形,富士通的Tofu互连用于K和 Fukagu 的超级计算机是6D 环形/网状互连——即使如果加入机器,重新接线是件痛苦的事情,通常需要升级和重新连接的系统选择 Clos 或蜻蜓拓扑。

TPUv4i 和 TPUv4,特别是与它们的前辈相比,以及与同样针对人工智能训练和推理的竞争性图形处理器相比,展示了极简主义设计的价值,这种设计架构只为了做一件事:用于人工智能处理的矩阵数学计算。
尽管也有一些研究人员正试图利用 TPU 来运行加速 HPC 模拟和建模应用程序。
随着 Hopper GPU的普及,Google 使用 TPUv4引擎与其他加速器进行的比较必然要与Nvidia 的安培 A100图形处理器进行比较。
谷歌系统和服务基础设施副总裁 Amin Vahdat 提供了一张图,通过运行不同的神经网络模型,展示了 TPU与A100的对比结果,以及谷歌云上的 TPUv4 pod如何与微软 Azure 上的类似规模的 A100集群对抗。
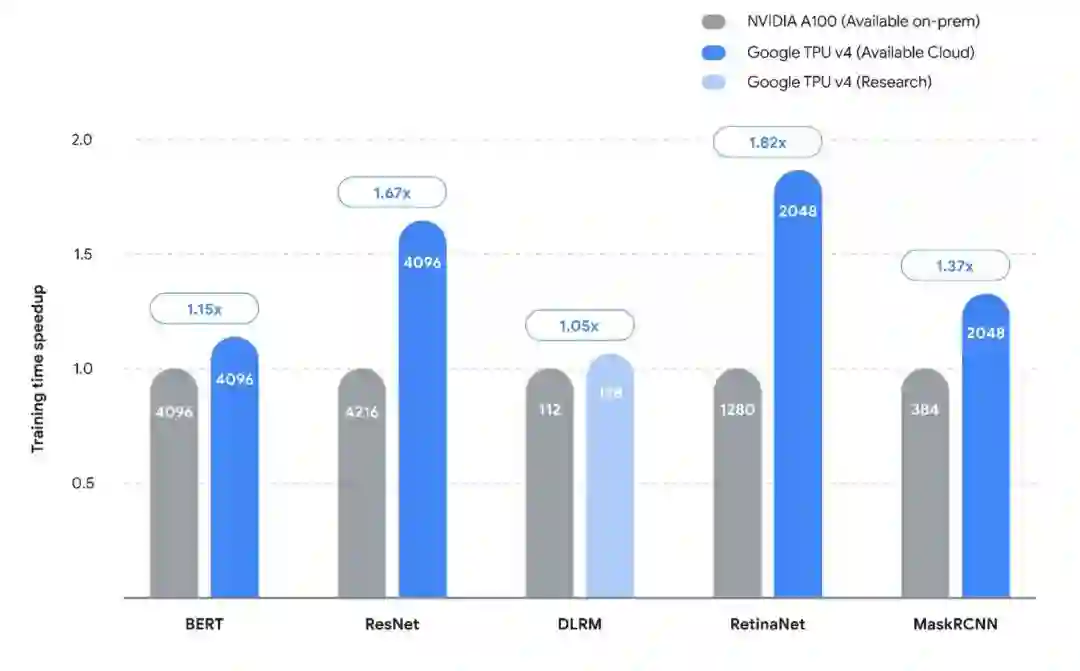
在较低规模的模型中,性能差异并不像Meta平台的深度学习推荐模型(DLRM)那样大。
Vahdat 说,平均而言,TPUv4在 MLPerf 测试中的表现比 Nvidia A100s 高出40% ,有趣的是,Google 在这五个测试中提交的 MLPerf 2.0结果比使用 MLPerf 1.0套测试的 TPUv4高出50%
归根结底,比硬件供应和速度更重要的是人工智能训练的成本,使用4096个TPUv4 pod和一个同样堆叠规模的Nvidia A100 GPU对比。
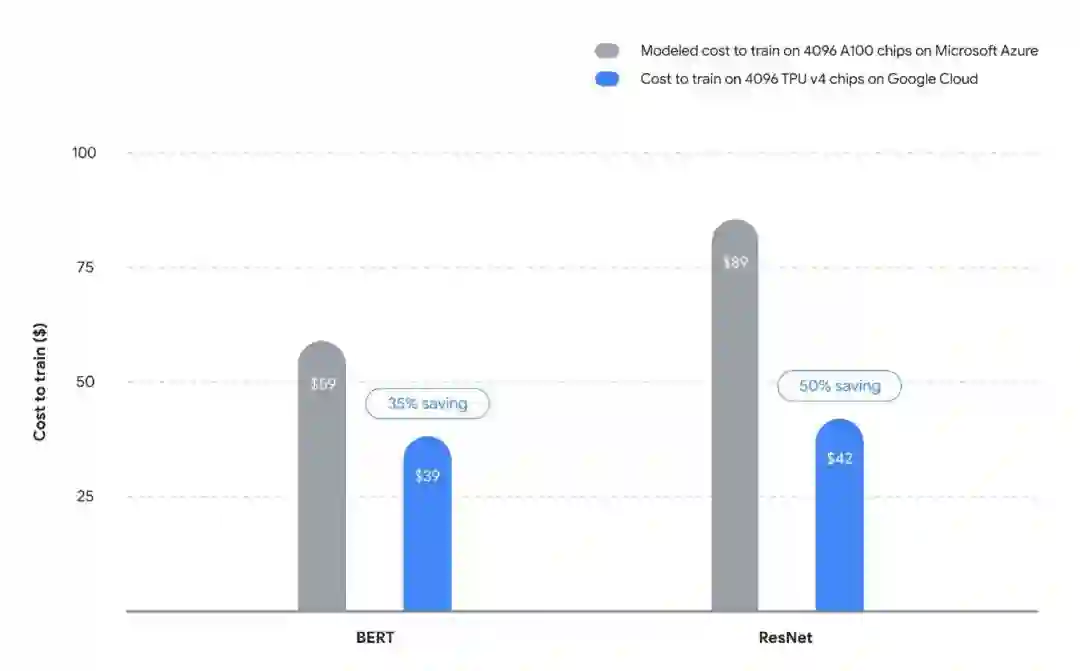
Vahdat的团队根据提交的 MLPerf 结果以及他们自己对 BERT 和 ResNet 如何在 GPU 上扩展的了解建立了成本模型。
目前还不清楚与 H100GPU 加速器相比会是什么样子。Nvidia 可能提供3到6倍的性能(取决于工作负载) ,成本为2.5到3倍。
在价格上,TPUv4芯片上花费一个小时的价格比在TPUv3芯片上花费的价格高出61% ,但是它提供的性能是TPUv3芯片的2.23倍,也就是说性价比提高了28%
在TPUv2到 TPUv3的跃升时,性能提高了2.67% ,性价比提高了33.5%






