CVPR2020 | 对抗伪装:如何让AI怀疑人生!


想象一下,有一天你坐在自动驾驶汽车行驶在街道上,右前方有个stop的牌子,除了有点旧,看起来并没有什么异样,你没有留心太多,继续专注手头的工作,可是车并没有停下来…
如果你是广大炼丹师的一员,你一定听说过对抗样本,对抗样本作为神经网络出其不意的bug,近年引起很多关注,在你的印象中,ta可能是这样子的:
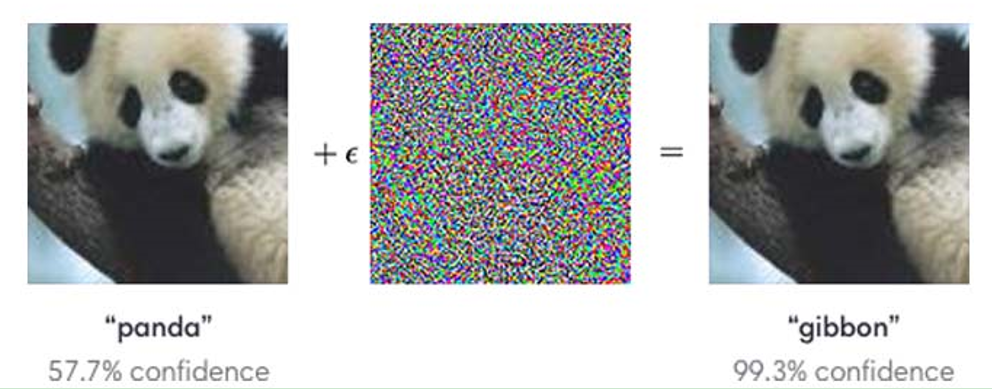
Figure 1. FGSM [1]
这是最初提出的对抗样本的形态[1],与原图相比 (左一),对抗样本(右一) 仅仅增加了非常小的干扰,就使神经网络将熊猫识别为gibbon (长臂猿)。为了凸显计算机视觉系统在人眼看来“普通图片”上截然不同的决策原理,在后续一系列的研究中,研究者们都限制对抗样本只能进行微小 (Lp-norm-bounded) 的修改,以维持改变的不可察觉性。
但是, 由于现实环境的多种因素 (例如光照、拍摄距离等),这种小量的干扰不易被相机等设备捕捉到,从而只能在数字世界里发挥作用。当然,也有一些工作将对抗样本带到现实世界中,并产生威胁,例如Brown等人在2017年提出的adversarial patch [2]:

Figure 2. Adversarial patch [2]
以及应用于交通标志的“对抗贴纸“ [3]:

Figure 4. RP2 [3]
但是,这些工作将对抗样本带到现实世界中同时,过大的干扰形成的诡异图案也变得容易被人察觉。所以, 有没办法能让对抗样本在现实世界中也做到不可察觉呢?
本文介绍一篇CVPR 2020的工作:对抗伪装(adversarial camouflage: hiding physical-world attacks with naturalstyles)。在该项工作中,来自澳大利亚Swinbourne大学、墨尔本大学、以及上海交通大学的研究者们通过一个结合了风格迁移和对抗攻击的框架(AdvCam)可以将对抗样本的风格进行个性化伪装。攻击者可以随意选择自己喜欢的风格和攻击区域进行攻击并伪装。从此,对抗攻击变得更有意思了呢…
例如,下面几张图片,你看出来哪里变了么?



小猎狗 or 熊皮?

Figure5.
不同于之前的工作,通过限定L-p norm要求对抗样本尽可能与原图差别不大,本文作者通过融合风格迁移方法定义了一种新颖的范式来实现对抗样本的不可察觉性:
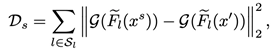
作为攻击者,在确定了攻击目标的周边环境后,攻击者可以通过自定义风格将攻击后的物体进行伪装。例如,对交通指示牌的攻击可以随意伪装成:泥点、褪色或者雪渍等自然常见的样子:
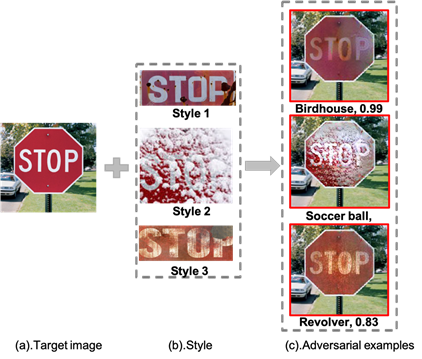
Figure6
在真实物理世界里,这种伪装方式可以让对抗攻击以各种形态伪装在各种角落里。
比如,随意悬挂的一个交通指示牌,其实是一个“理发店”(what??):

再比如,“树皮”也可以被识别为街道标识:

作者还展示了这种伪装的另一个用途:保护个人隐私。例如在各种监控设备的场景下,用户个人可以用定制具有对抗效果的T恤用于避免被深度学习加持监控设备追踪:

Figure7.
当用户身穿这件经过特殊设计的T恤的图片被传到网上后,也可以防止被google image search识别, 该方法也可以防止具有隐私内容的图片被AI工具自动抓取等。趣味性和安全性两不误!下图是Google Image Search的结果:斗牛犬!
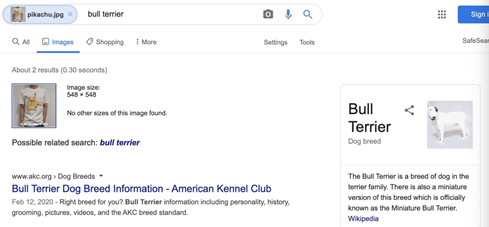
Figure8.
Reference:
[1] ChristianSzegedy, Wojciech Zaremba, Ilya Sutskever, Joan Bruna, Dumitru Erhan, IanGoodfellow, and Rob Fergus. Intriguing properties of neural networks. In ICLR,2013.
[2] TomB Brown, Dandelion Mane, Aurko Roy, Mart ´ ´ın Abadi, and Justin Gilmer.Adversarial patch. In NIPS Workshop, 2017
[3] IvanEvtimov, Kevin Eykholt, Earlence Fernandes, Tadayoshi Kohno, Bo Li, AtulPrakash, Amir Rahmati, and Dawn Song. Robust physical-world attacks on deeplearning models. In CVPR, 2018.
点击“阅读原文” 查看往期直播回放视频



