【CVPR2022】基于粗-精视觉Transformer的仿射医学图像配准

Affine Medical Image Registration with Coarse-to-Fine Vision Transformer
Authors: Tony C. W. Mok, Albert C. S. Chung
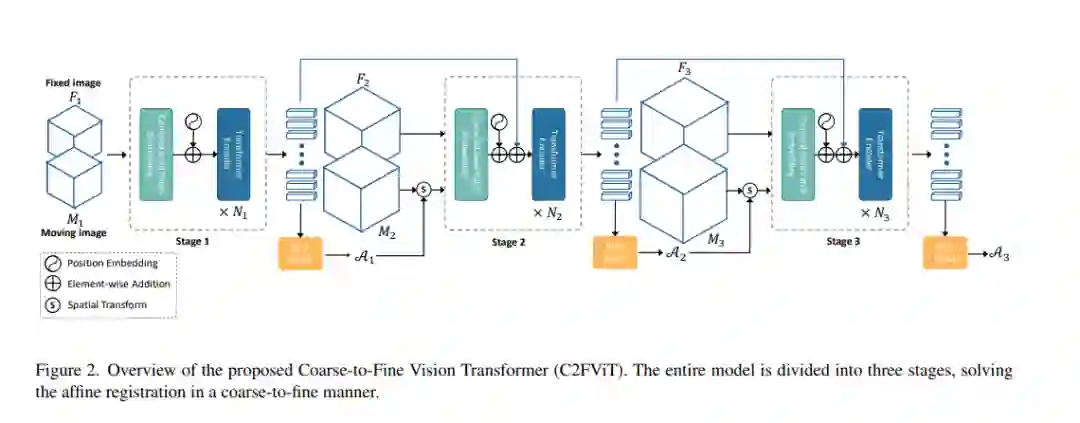
仿射配准是综合医学图像配准过程中不可缺少的环节。然而,关于快速、鲁棒的仿射配准算法的研究却很少。这些研究大多利用卷积神经网络(convolutional neural network, CNNs)学习联合仿射和非参数配准,而仿射子网络的独立性能研究较少。此外,现有的基于CNN的仿射配准方法要么关注输入的局部不对齐,要么关注输入的全局方向和位置来预测仿射变换矩阵,这些方法对空间初始化很敏感,除了训练数据集之外,泛化能力有限。本文提出了一种快速、鲁棒的基于学习的三维仿射医学图像配准算法——粗糙-精细视觉Transformer (C2FViT)。我们的方法自然地利用了卷积视觉转换器的全局连接性和局部性,以及多分辨率策略来学习全局仿射配准。对该方法进行了三维脑图谱配准和模板匹配归一化的评价。综合结果表明,我们的方法在保持基于学习方法的运行时间优势的同时,在配准精度、鲁棒性和通用性方面都优于现有的基于CNN的仿射配准方法。源代码可以在https://github.com/cwmok/C2FViT上找到。
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“AMIR” 就可以获取《【CVPR2022】基于粗-精视觉Transformer的仿射医学图像配准》专知下载链接



登录查看更多
相关内容

相关VIP内容
相关资讯