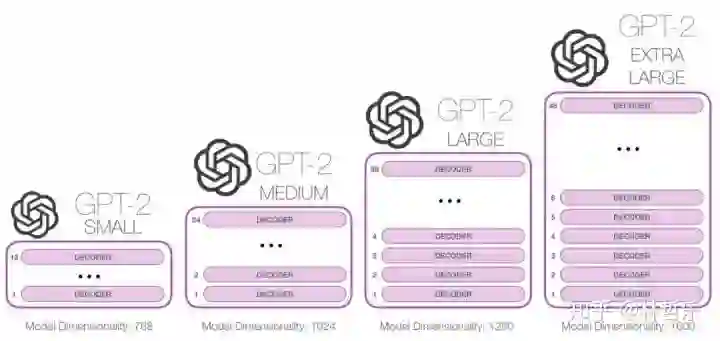
按照时间线帮你梳理10种预训练模型

ELMO 2018.03 华盛顿大学
GPT 2018.06 OpenAI
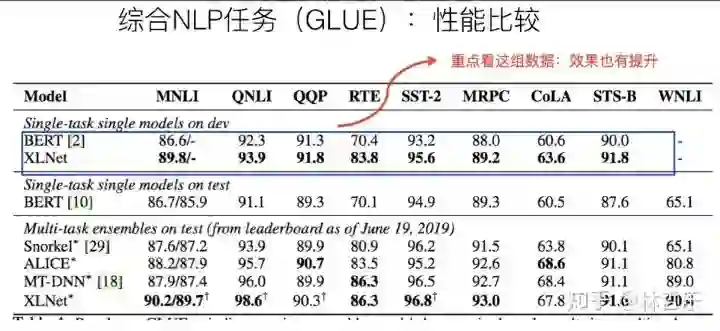
BERT 2018.10 Google
XLNet 2019.6 CMU+google
ERNIE 2019.4 百度
BERT-wwm 2019.6 哈工大+讯飞
RoBERTa 2019.7.26 Facebook
ERNIE2.0 2019.7.29 百度
BERT-wwm-ext 2019.7.30 哈工大 +讯飞
ALBERT 2019.10 Google

单向特征、自回归模型(单向模型):
ELMO/ULMFiT/SiATL/GPT1.0/GPT2.0
双向特征、自编码模型(BERT系列模型):
BERT/ERNIE/SpanBERT/RoBERTa
双向特征、自回归模型“
XLNet
『各模型之间的联系 』
传统word2vec无法解决一词多义,语义信息不够丰富,诞生了ELMO
ELMO以lstm堆积,串行且提取特征能力不够,诞生了GPT
GPT 虽然用transformer堆积,但是是单向的,诞生了BERT
BERT虽然双向,但是mask不适用于自编码模型,诞生了XLNET
BERT中mask代替单个字符而非实体或短语,没有考虑词法结构/语法结构,诞生了ERNIE
为了mask掉中文的词而非字,让BERT更好的应用在中文任务,诞生了BERT-wwm
Bert训练用更多的数据、训练步数、更大的批次,mask机制变为动态的,诞生了RoBERTa
ERNIE的基础上,用大量数据和先验知识,进行多任务的持续学习,诞生了ERNIE2.0
BERT-wwm增加了训练数据集、训练步数,诞生了BERT-wwm-ext
BERT的其他改进模型基本考增加参数和训练数据,考虑轻量化之后,诞生了ALBERT
「 1.ELMO 」
特点:传统的词向量(如word2vec)是静态的/上下文无关的,而ELMO解决了一词多义;ELMO采用双层双向LSTM
缺点:lstm是串行,训练时间长;相比于transformer,特征提取能力不够(ELMO采用向量拼接)
使用分为两阶段:预训练+应用于下游任务,本质就是根据当前上下文对Word Embedding进行动态调整的过程:
1. 用语言模型进行预训练
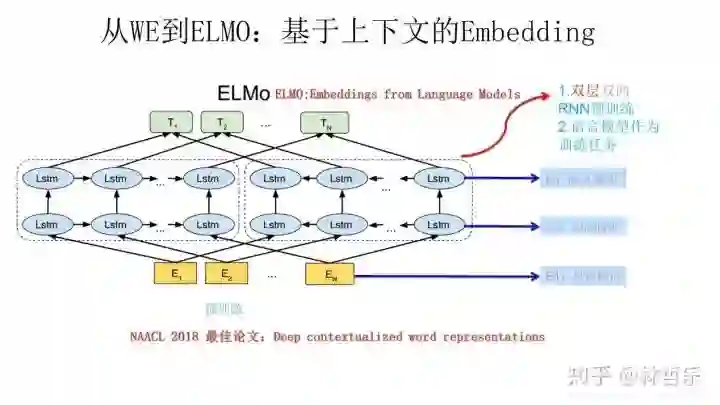
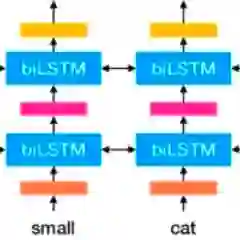
左边的前向双层LSTM是正方向编码器,顺序输入待预测单词w的上文;右边则是反方向编码器,逆序输入w的下文
训练好之后,输入一个新句子s,每个单词都得到三个Embedding:①单词的Word Embedding ②第一层关于单词位置的Embedding ②第二层带有语义信息的Embedding(上述的三个Embedding 、LSTM网络结果均为训练结果)
2. 做下游任务时,从预训练网络中提取对应单词的网络各层的Word Embedding作为新特征补充到下游任务中。 如QA任务:输入Q/A句子,对三个Embedding分配权重,整合生成新的Embedding
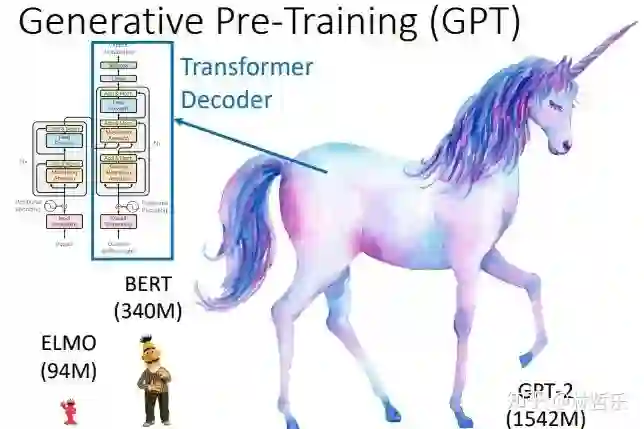
「 2.GPT 」
优点:Transformer捕捉更长范围的信息,优于RNN;并行,快速
缺点:需要对输入数据的结构调整;单向
特点:
依然两段式:单向语言模型预训练(无监督)+fine tuning应用到下游任务(有监督)
自回归模型
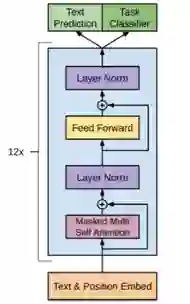
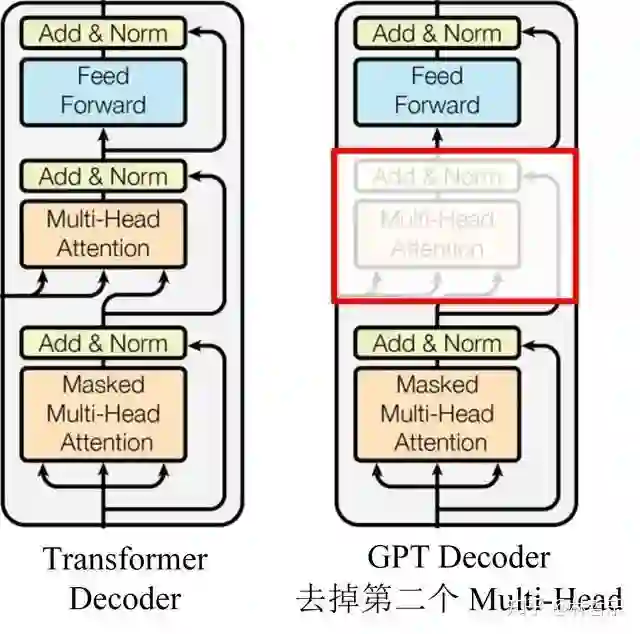
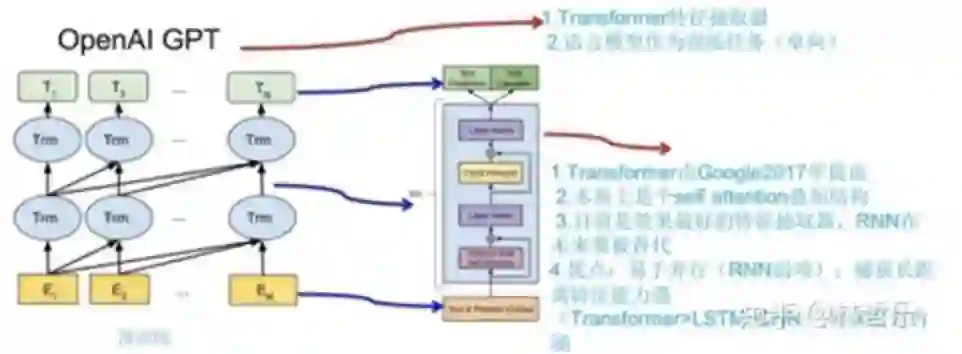
transformer的decoder里面有三个子模块,GPT只用了第一个和第三个子模块,如下图:
与ELMO的不同:
GPT只用了transformer的decoder模块提取特征,而不是Bi-LSTM;堆叠12个
单向(根据上文预测单词,利用mask屏蔽下文)
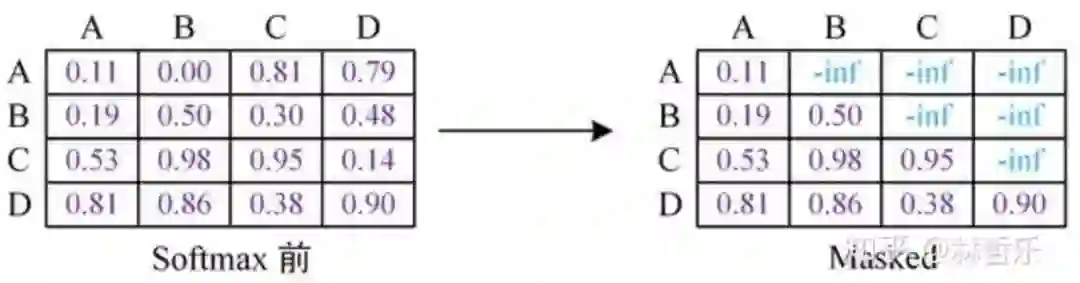
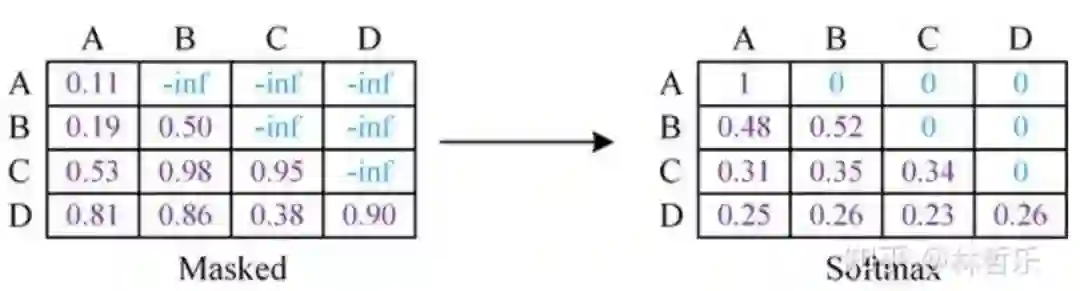

对于分类问题,不用怎么动,加上一个起始和终结符号即可;
对于句子关系判断问题,比如 Entailment,两个句子中间再加个分隔符即可;
对文本相似性判断问题,把两个句子顺序颠倒下做出两个输入即可,这是为了告诉模型句子顺序不重要;
对于多项选择问题,则多路输入,每一路把文章和答案选项拼接作为输入即可。从上图可看出,这种改造还是很方便的,不同任务只需要在输入部分施工即可。

「 3.BERT 」
与GPT的区别:
双向
用的是transformer的encoder(GPT用的是decoder,ELMO用的是Bi-LSTM)
多任务学习方式训练:预测目标词和预测下一句
优点:效果好、普适性强、效果提升大
缺点:硬件资源的消耗巨大、训练时间长;预训练用了[MASK]标志,影响微调时模型表现
预训练分为以下三个步骤:
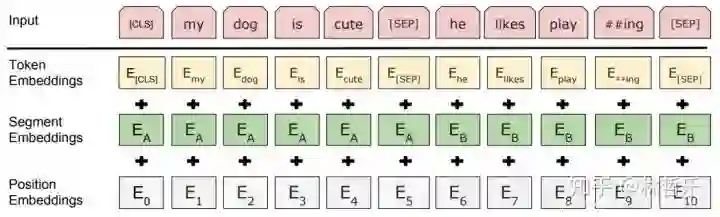
Embedding
三个Embedding 求和而得,分别是:
a.Token Embeddings:词向量,首单词是[CLS]标志,可用于分类任务
b.Segment Embeddings:用[SEP]标志将句子分为两段,因为预训练不光做LM还要做以两个句子为输入的分类任务
c.Position Embeddings:和之前文章中的Transformer不同,不是三角函数而是学习出来的
预测目标词Masked LM
随机挑选一个句子中15%的词,用上下文来预测。这15%中,80%用[mask]替换,10%随机取一个词替换,10%不变。用非监督学习的方法预测这些词。
预测下一句 Next Sentence Prediction
选择句子对A+B,其中50%的B是A的下一句,50%为语料库中随机选取
BERT的微调(fine tuning)参考参数:
Batch Size:16 or 32
Learning Rate: 5e-5, 3e-5, 2e-5
Epochs:2, 3, 4
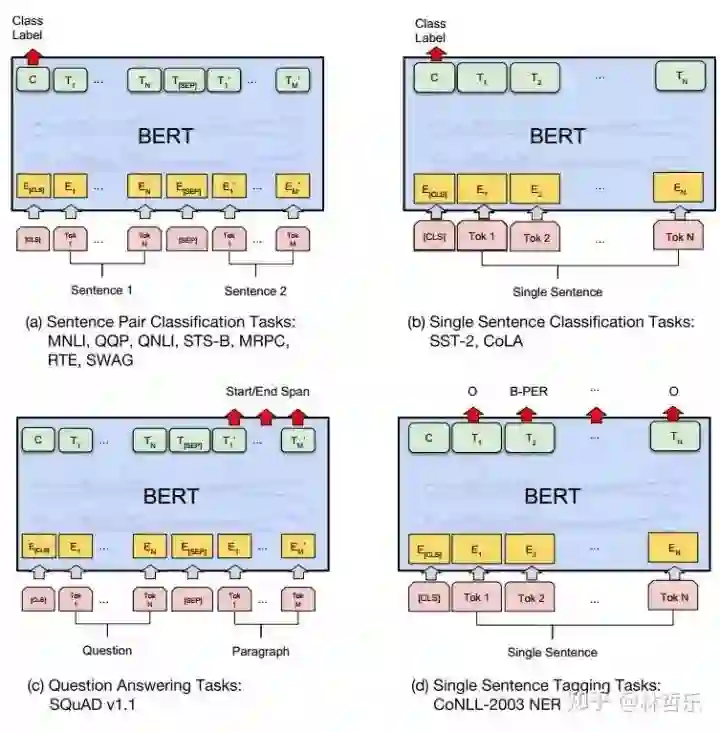
BERT非常强大,在 11 项 NLP 任务中夺得 SOTA 结果,这11项任务可分为四大类:
句子对分类任务
单句子分类任务
问答任务
单句子标注任务
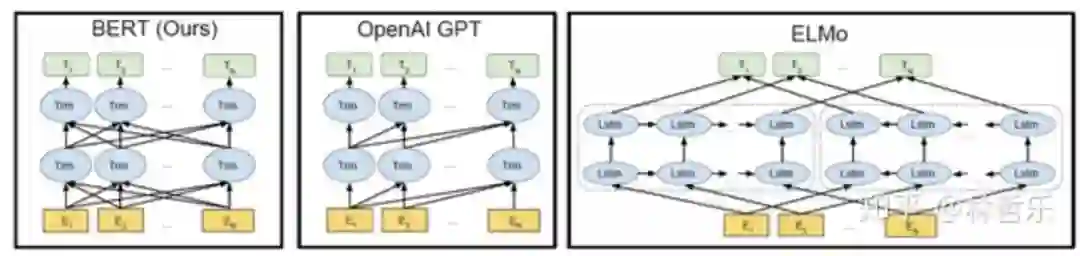
ELMO用Bi-LSTM,GPT用transformer的decoder,BERT用transformer的encoder
ELMO:双向,GPT,单向,BERT:双向
ELMO:解决一词多义,GPT,特征更丰富,BERT:双向/多任务训练/能捕捉更长距离的依赖
GPT:适合文本生成等任务(NLG任务),BERT:适合预测任务(NLU任务)
GPT-2,以及一些诸如 TransformerXL 和 XLNet 等后续出现的模型,本质上都是自回归模型,而 BERT 则不然,虽然没有使用自回归机制,但 BERT 获得了结合单词前后的上下文信息的能力,从而取得了更好的效果。而其中XLNet虽然使用了自回归,但引入了一种能够同时兼顾前后的上下文信息的方法,即双流自注意力。
「 4.XLNet 」
基本思路:通过排列组合的方式将一部分下文单词放到上文单词的位置,但实际形式还是一个从左到右预测的自回归语言模型。
优化:
采用自回归(AR , Autoregressive)模型替代自编码(AE , Autoencoding )模型,解决bert中mask带来的负面影响(预训练和微调数据的不统一)
双流注意力机制(新的分布计算方法,来实现目标位置感知)
引入transformer-XL
自回归,时间序列分析或者信号处理领域常用词汇,根据上文预测当前词
自编码,是无监督的,mask掉一个词,然后根据上下文来预测这个词
content representation内容表述,下文用
表示,同时编码上下文和


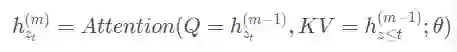
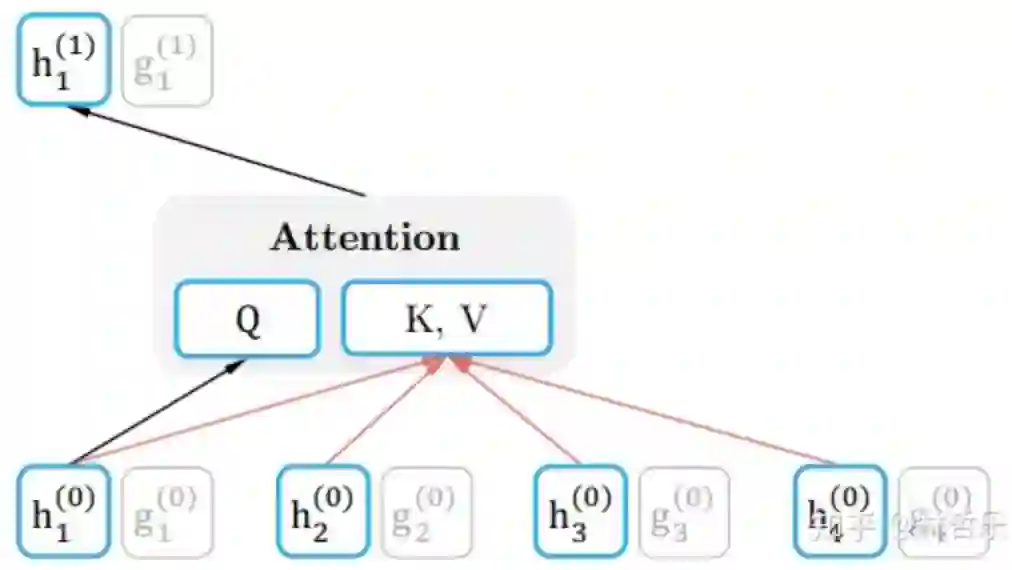
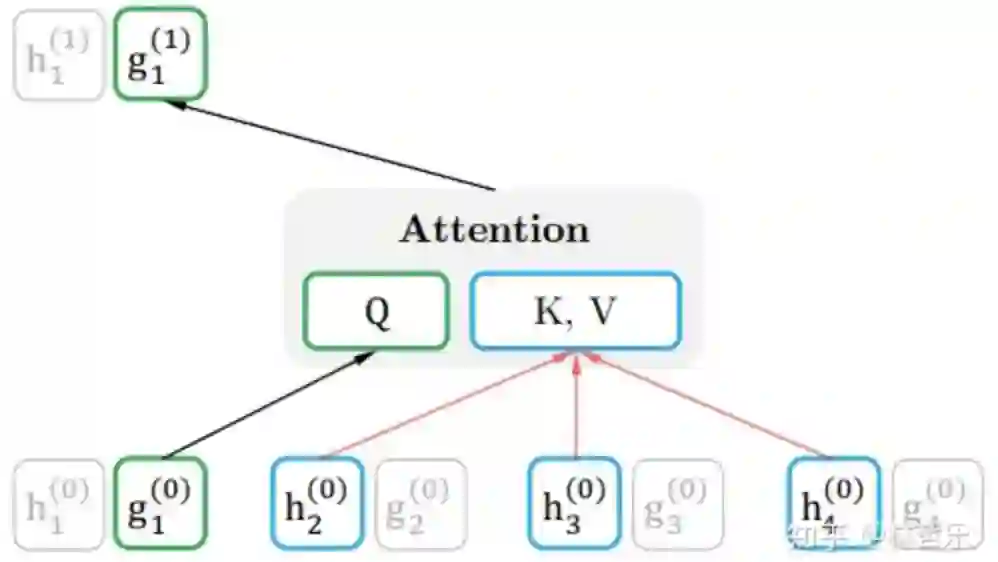
query representation查询表述,下文用
表示,包含上下文的内容信息
和目标的位置信息
,但不包括目标的内容信息



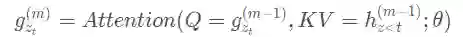
相对位置编码:为了区分某个位置编码到底时哪一个片段里的。此值为训练所得,用来计算注意力的权值。(bert采用绝对位置编码)
片段循环机制:解决了超长序列的依赖问题,因为前一个片段被保留了,不需重新计算;同时加快了训练速度
「 5.ERNIE 」
Transformer: 6 encoder layers, 512 hidden units, 8 attention heads
ERNIE Base: 12 encoder layers, 768 hidden units, 12 attention heads
ERNIE Large: 24 encoder layers,1024 hidden units, 16 attention heads
训练数据:中文维基百科、百度百科、百度新闻、百度贴吧,大小分别为 21M,51M,47M,54M;
对BERT的优化:
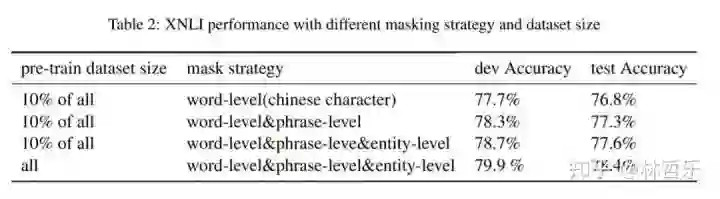
三种mask:字层面、短语层面、实体层面(引入外部知识,模型可获得更可靠的语言表示)
用大量中文数据集、异质数据集
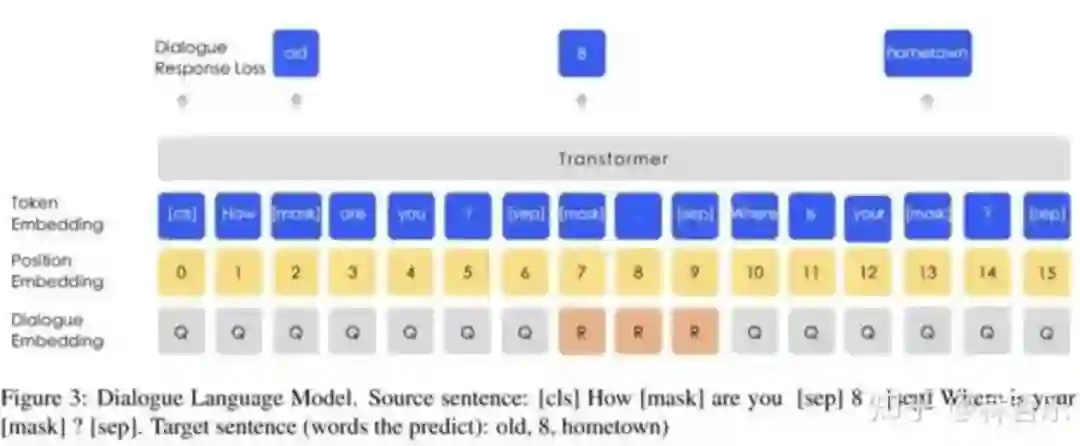
为适应多轮的贴吧数据,引入对话语言模型(DLM ,Dialogue Language Model)的任务
预训练过程:
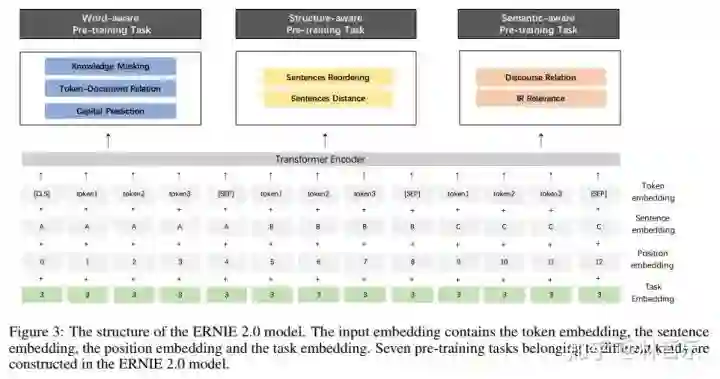
连续用大量的数据与先验知识连续构建不同的预训练任务(词法级别,语法级别,语义级别)
不断的用预训练任务更新ERNIE 模型
ERNIE的mask与BERT的不同:
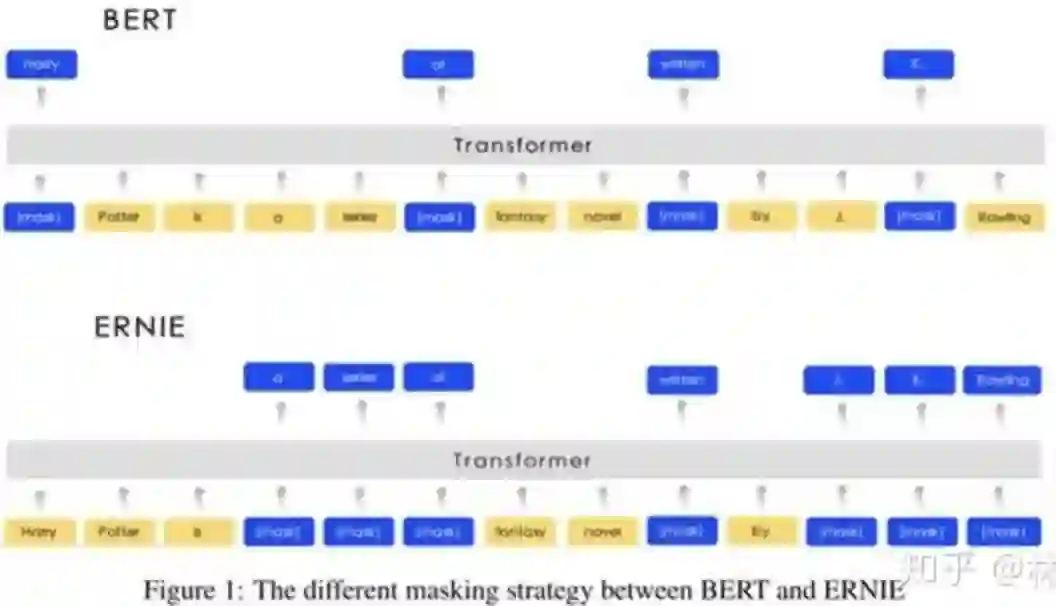
ERNIE的mask策略分三个阶段(附图):
第一阶段,采用BERT的方式,字级别,即basic-level masking,随机mask中文某字
第二阶段,词组级别的mask,即phrase-level masking,mask掉句子中一部分词组(预测这些词组的阶段,词组信息被编码到词向量中)
第三阶段,实体级别的mask,即entity-level masking,如人名、机构名等(模型训练完后,学到实体信息)先分析句子的实体,然后随机mask

「 6.BERT-wwm 」

BERT-wwm-ext与BERT-wwm
BERT-wwm使用的语料:中文维基+通用数据(百科、新闻、问答等数据,总词数达5.4B)
BERT-wwm-ext使用的语料:中文维基
与ERNIE相比:
「 7.RoBERTa 」
训练数据更多(160G),bert是16G
batch size更大(256到8000不等),训练时间更长
训练序列更长
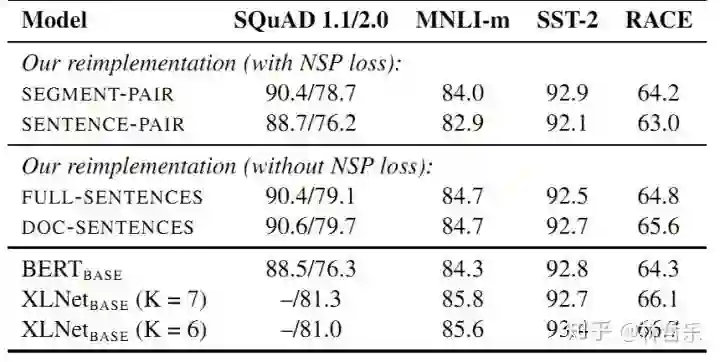
不在使用NSP(Next Sentence Prediction)任务,移除了next predict loss
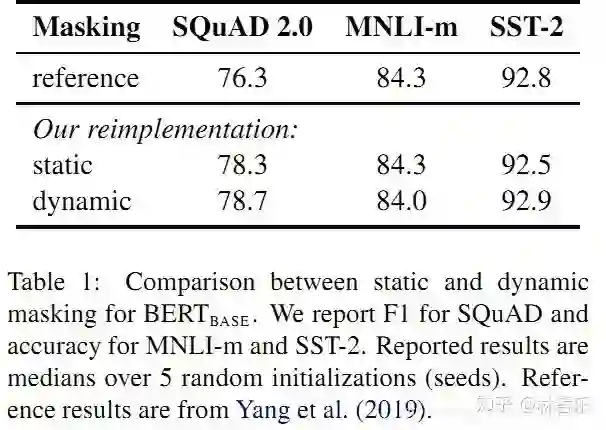
动态Masking,让数据不重复
文本编码采用更大的字节级别的BPE词汇表(Byte-Pair Encoding)而Bert是字符级
SEGMENT-PAIR + NSP:输入包含两部分,每个部分是来自同一文档或者不同文档的 segment (segment 是连续的多个句子),这两个segment 的token总数少于 512 。预训练包含 MLM 任务和 NSP 任务。这是原始 BERT 的做法。
SENTENCE-PAIR + NSP:输入也是包含两部分,每个部分是来自同一个文档或者不同文档的单个句子,这两个句子的token 总数少于 512 。由于这些输入明显少于512 个tokens,因此增加batch size的大小,以使 tokens 总数保持与SEGMENT-PAIR + NSP 相似。预训练包含 MLM 任务和 NSP 任务。
FULL-SENTENCES:输入只有一部分(而不是两部分),来自同一个文档或者不同文档的连续多个句子,token 总数不超过 512 。输入可能跨越文档边界,如果跨文档,则在上一个文档末尾添加文档边界token 。预训练不包含 NSP 任务。
DOC-SENTENCES:输入只有一部分(而不是两部分),输入的构造类似于FULL-SENTENCES,只是不需要跨越文档边界,其输入来自同一个文档的连续句子,token 总数不超过 512 。在文档末尾附近采样的输入可以短于 512个tokens, 因此在这些情况下动态增加batch size大小以达到与 FULL-SENTENCES 相同的tokens总数。预训练不包含 NSP 任务.

「 8.ERNIE2.0 」
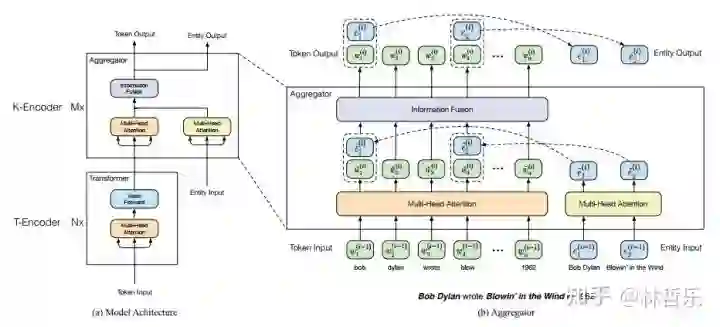
「 9.BERT-wwm-ext 」
预训练数据集做了增加,次数达到5.4B;
训练步数增大,训练第一阶段1M步,batch size为2560;训练第二阶段400K步,batch size为2560。
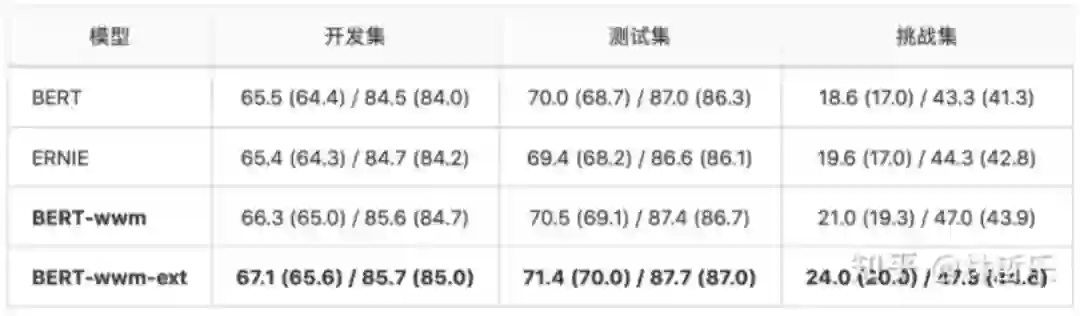
数据:CMRC 2018,哈工大+讯飞发布的中文机器阅读理解数据
任务:根据指定问题,从篇章中抽取出片段作为答案
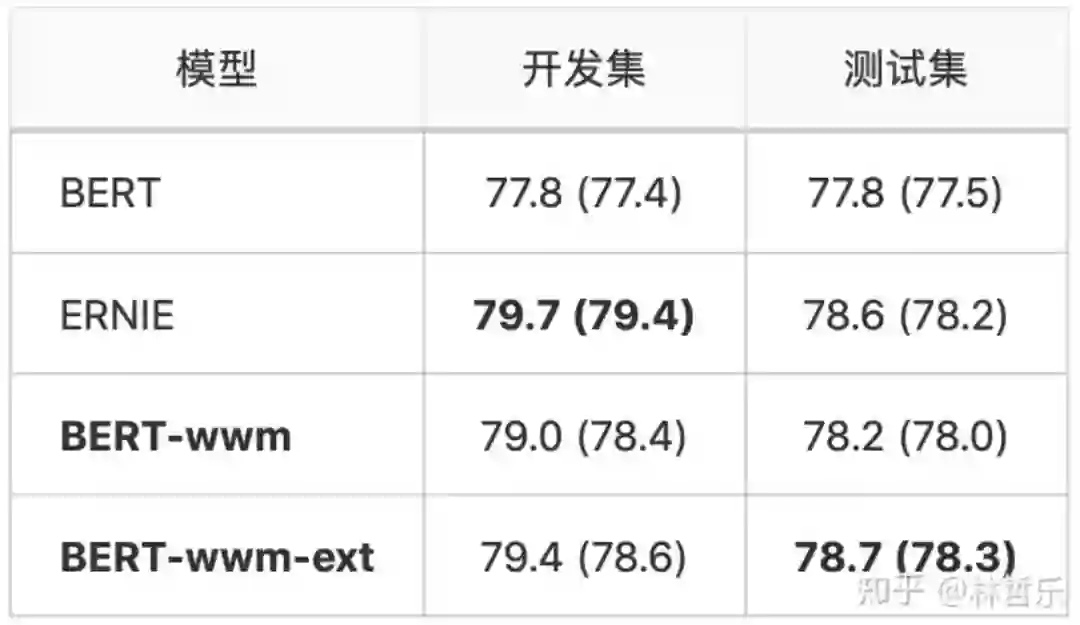
与BERT和ERNIE的对比:
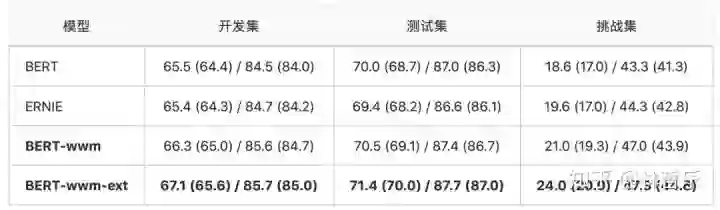
数据 :DRCD,中国台湾台达研究院发布的数据集
BERT-wwm-ext带来非常显著的性能提升:
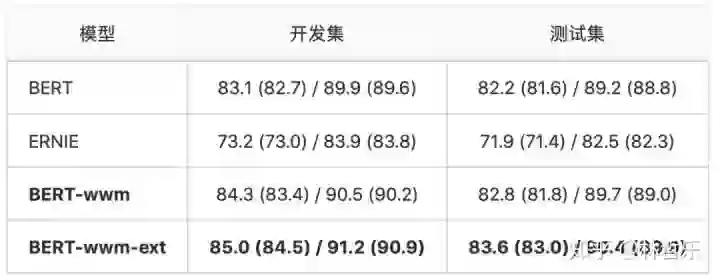
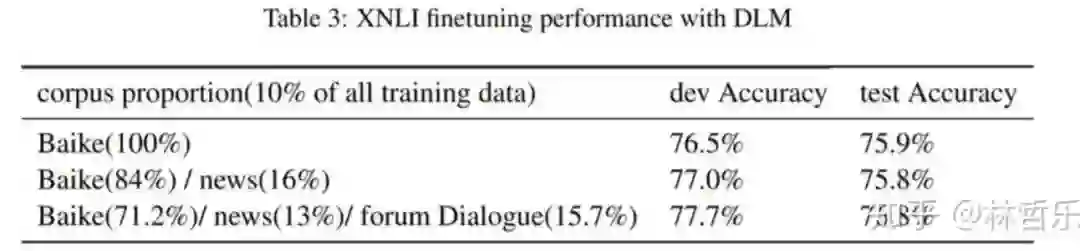
数据 :XNLI,
BERT-wwm-ext与ERNIE在该任务上的效果较好:
「 10.ALBERT 」
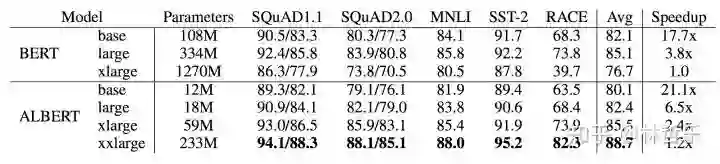
ALBERT的改进/贡献:
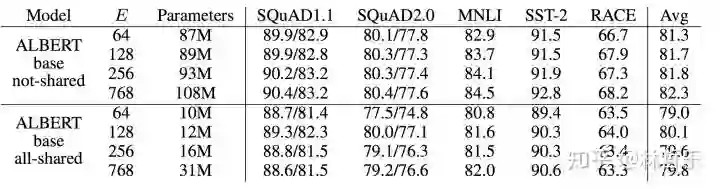
提出了两种减少内存的方法(因式分解、参数共享)
改进了BERT中的NSP的预训练任务,提升了训练速度
提升了模型效果
ALBERT的改进有三个方面:
对Embedding进行因式分解
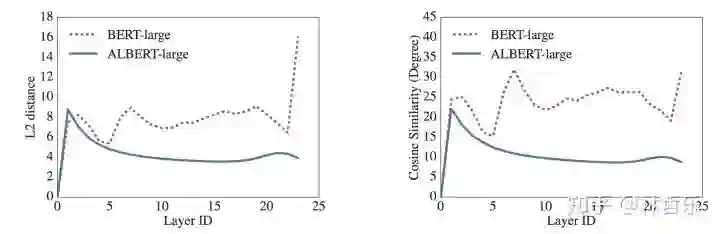
跨层参数共享(性能轻微降低,参数大量减少)
句间连贯性损失(SOP)

ELMO:
https://arxiv.org/pdf/1802.05365.pdf
GPT:
https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/languageunsupervised/language_understanding_paper.pdf
BERT:
https://arxiv.org/pdf/1810.04805.pdf
XLNet:
https://arxiv.org/pdf/1906.08237.pdf
ERNIE:
https://arxiv.org/pdf/1904.09223.pdf
BERT-wwm:
https://arxiv.org/pdf/1906.08101.pdf
RoBERTa:
https://arxiv.org/pdf/1907.11692.pdf
ERNIE2.0:
https://arxiv.org/pdf/1907.12412.pdf
ALBERT:
https://openreview.net/pdf?id=H1eA7AEtvS
ELMO:
https://github.com/allenai/allennlp
GPT:
https://github.com/openai/gpt-2
BERT:
https://github.com/guotong1988/BERT-tensorflow
XLNet:
https://github.com/zihangdai/xlnet
ERNIE:
https://github.com/PaddlePaddle/ERNIE
BERT-wwm:
https://github.com/ymcui/Chinese-BERT-wwm
RoBERTa:https://github.com/brightmart/roberta_zh(中文)
https://github.com/pytorch/fairseq(英文)
ERNIE2.0:https://github.com/PaddlePaddle/ERNIE
BERT-wwm-ext:
https://drive.google.com/file/d/1buMLEjdtrXE2c4G1rpsNGWEx7lUQ0RHi/view
ALBERT:
https://github.com/brightmart/albert_zh
(1)点击页面最上方"AINLP",进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心![]() 。
。
欢迎加入预训练模型交流群
进群请添加AINLP小助手微信 AINLPer(id: ainlper),备注预训练模型
![]()
推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。
![]()
阅读至此了,分享、点赞、在看三选一吧🙏