BERT和ERNIE谁更强?这里有一份4大场景的细致评测
允中 发自 凹非寺
量子位 报道 | 公众号 QbitAI
BERT和ERNIE,NLP领域近来最受关注的2大模型究竟怎么样?
刚刚有人实测比拼了一下,结果在中文语言环境下,结果令人意外又惊喜。
具体详情究竟如何?不妨一起围观下这篇技术评测。
1. 写在前面
随着2018年ELMo、BERT等模型的发布,NLP领域终于进入了“大力出奇迹”的时代。采用大规模语料上进行无监督预训练的深层模型,在下游任务数据上微调一下,即可达到很好的效果。曾经需要反复调参、精心设计结构的任务,现在只需简单地使用更大的预训练数据、更深层的模型便可解决。
随后在2019年上半年,百度的开源深度学习平台PaddlePaddle发布了知识增强的预训练模型ERNIE,ERNIE通过海量数据建模词、实体及实体关系。相较于BERT学习原始语言信号,ERNIE直接对先验语义知识单元进行建模,增强了模型语义表示能力。
简单来说,百度ERNIE采用的Masked Language Model是一种带有先验知识Mask机制。可以在下图中看到,如果采用BERT随机mask,则根据后缀“龙江”即可轻易预测出“黑”字。引入了词、实体mask之后,“黑龙江”作为一个整体被mask掉了,因此模型不得不从更长距离的依赖(“冰雪文化名城”)中学习相关性。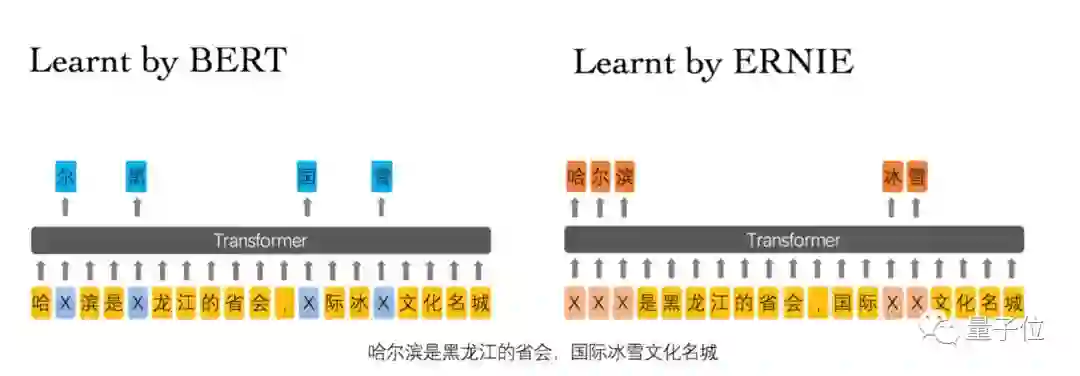
2. 亲测
到底百度ERNIE模型所引入训练机制有没有起到作用,只有实践了以后才知道。为此,我亲自跑了BERT和ERNIE两个模型,在下面的几个场景中得到了预测结果。
2.1 完形填空
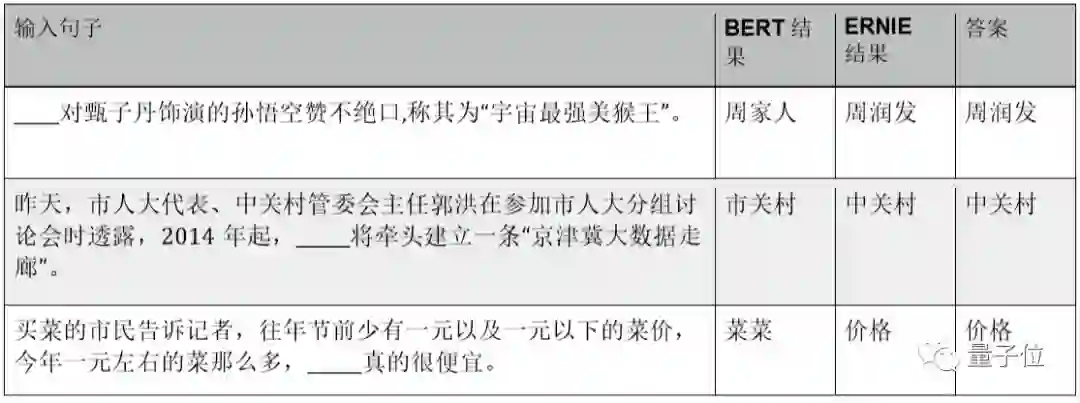
完形填空任务与预训练时ERNIE引入的知识先验Mask LM任务十分相似。从下图的比较中我们可以看到,ERNIE对实体词的建模更加清晰,对实体名词的预测比BERT更准确。例如BERT答案“周家人”融合了相似词语“周润发”和“家人”结果不够清晰;“市关村”不是一个已知实体;“菜菜”的词边界是不完整的。ERNIE的答案则能够准确命中空缺实体。
2.2 NER (命名实体识别)
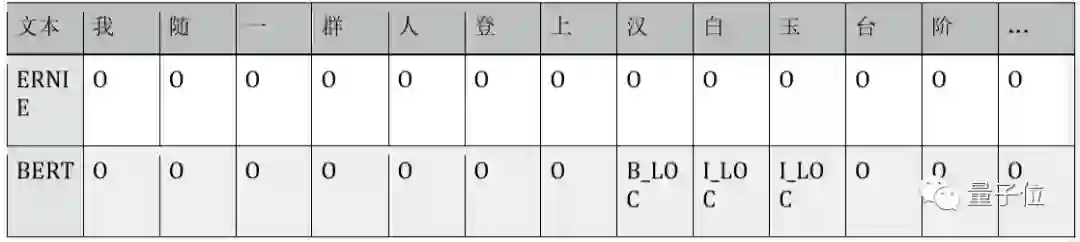
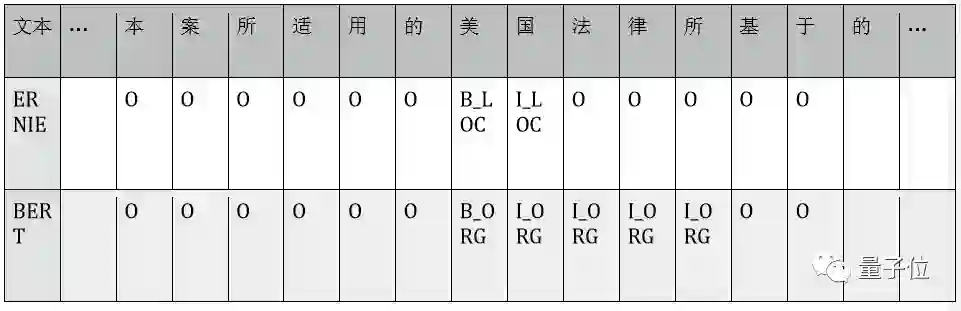
在同样为token粒度的NER任务中,知识先验Mask LM也带来了显著的效果。对比MSRA-NER数据集上的F1 score表现,ERNIE与BERT分别为93.8%、92.6%。在PaddleNLP的LAC数据集上,ERNIE也取得了更好的成绩,测试集F1为92.0%,比BERT的结果90.3%提升了1.7%。分析二者在MSRA-NER测试数据中二者的预测结果。可以观察到:
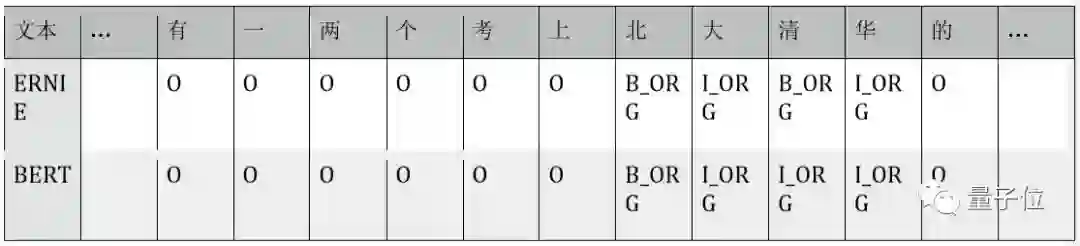
1.)ERNIE对实体理解更加准确:“汉白玉”不是实体类型分类错误;
2.)ERNIE对实体边界的建模更加清晰:“美国法律所”词边界不完整,而“北大”、“清华”分别是两个机构。
Case对比:摘自MSRA-NER数据测试集中的三段句子。B_LOC/I_LOC为地点实体的标签,B_ORG/L_ORG为机构实体的标签,O为无实体类别标签。下表分别展现了 ERNIE、BERT模型在每个字上的标注结果。
2.3 相似度
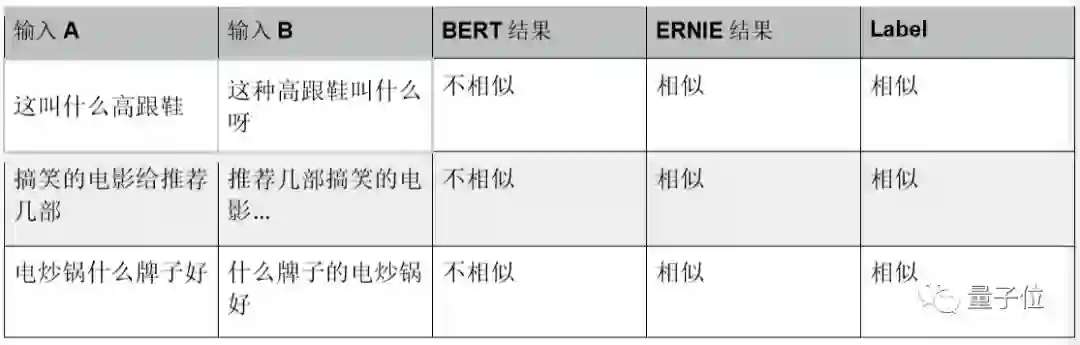
ERNIE在训练中引入的DLM能有效地提升模型对文本相似度的建模能力。因此,我们比较文本相似度任务LCQMC数据集上二者的表现。从下表的预测结果可以看出,ERNIE学习到了中文复杂的语序变化。最终ERNIE与BERT在该任务数据的预测准确率为87.4%、87.0%.
2.4 分类
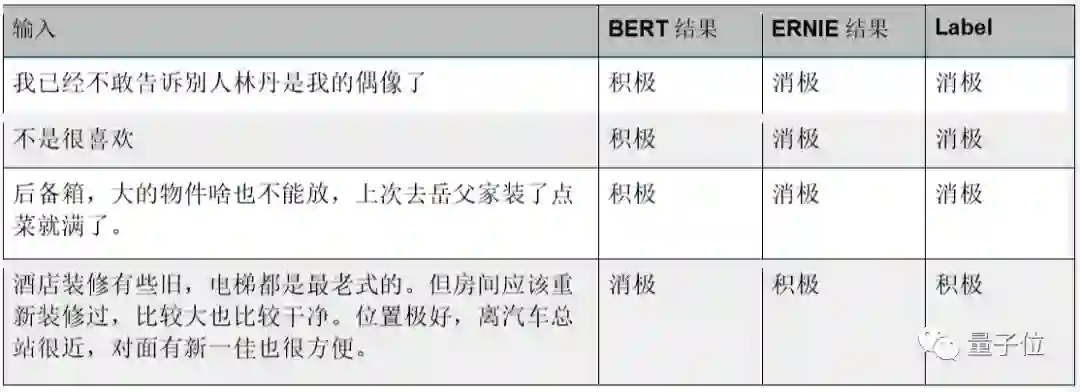
最后,比较应用最广泛的情感分类任务。经过预训练的ERNIE能够捕捉更加细微的语义区别,这些句子通常含有较委婉的表达方式。下面展示了PaddleNLP情感分类测试集上ERNIE与BERT的打分表现:在句式“不是很…”中含有转折关系,ERNIE能够很好理解这种关系,将结果预测为“消极”。在ChnSentiCorp情感分类测试集上finetune后ERNIE的预测准确率为95.4%,高于BERT的准确率(94.3%)。
从以上数据我们可以看到,ERNIE在大部分任务上都有不俗的表现。尤其是在序列标注、完形填空等词粒度任务上,ERNIE的表现尤为突出,一点都不输给Google的BERT。有兴趣的开发者可以一试:
https://github.com/PaddlePaddle/LARK/tree/develop/ERNIE
— 完 —
小程序|全类别AI学习教程

AI社群|与优秀的人交流


量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态
喜欢就点「在看」吧 !




