人工神经网络算法及其简易R实现
作者:鲁伟
一个数据科学践行者的学习日记。数据挖掘与机器学习,R与Python,理论与实践并行。个人公众号:数据科学家养成记 (微信ID:louwill12)

引子
一直在琢磨怎样把这些看起来高大上的数据挖掘和机器学习算法给大家用稍微通俗点的语言介绍出来,后来又觉得这要取决于我自己对算法的理解程度有多深以及会不会以一个传道授业解惑的角度来看待自己,所以就尽量做到自己的推文能让人看起来更友好一点。
人工神经网络(Artificial Neural Network)简单而言是一种分类算法。作为机器学习的一个庞大分支,人工神经网络目前大约有几百种算法,其中包括一些著名的ANN算法:感知器神经网络(Perceptron Neural Network), 反向传递(Back Propagation), Hopfield网络和自组织映射(Self-Organizing Map, SOM)等等,这篇文章我们只介绍最基本的人工神经网络算法原理及其简易的R语言实现方式。
在前几期的推文中,我们介绍的朴素贝叶斯和贝叶斯网络算法就是一种分类算法,先给两个例子让大家对分类这个概念有直观的认识。
· 是否拖欠银行贷款:银行根据一个人有房与否,婚姻状况和年收入来 判断客户是否会拖欠贷款。
· 垃圾邮件分类:机器会根据邮件里面的词汇来判断一封邮件是否为垃圾邮件。
如果一个机器能对输入的内容进行分类的话这个机器就称为分类器。分类器的输入是一个数值向量,叫做属性或者特征。在是否拖欠银行贷款的例子中,我们的输入是有房(1)无房(0)、已婚(1)未婚(0)收入区间这样的一个向量;垃圾邮件分类中我们的输入向量是一些0/1值,表示每一个单词是否出现。分类器的输出也是数值,拖欠贷款输出为1,不拖欠输出为0;垃圾邮件输出为1,非垃圾邮件输出为0。
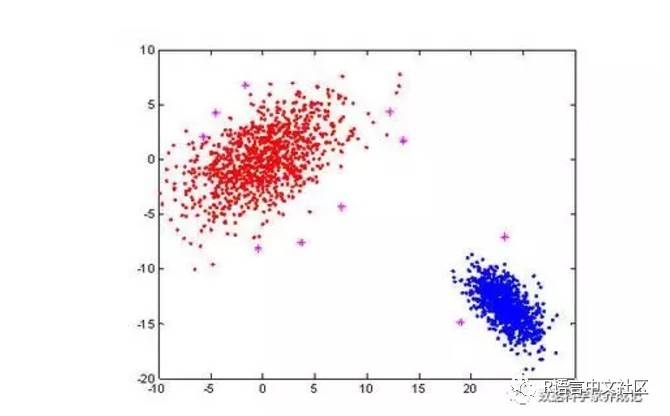
分类器的目的就是要使正确分类的可能性尽可能的高,错分的概率尽可能的低,一般我们会人为的划分一些样本做好标记作为训练样本,训练好的样本拿来对测试样本进行检验,这就是一个分类算法的基本原理。人工神经网络作为一种分类算法,其背后的原理大抵如此,因训练样本中要有标记,所以人工神经网络是一种监督分类算法。
神经网络简介
人工神经网络是在现代神经科学的基础上提出和发展起来的一种旨在反映人脑结构及功能的抽象数学模型。它具有人脑功能基本特性:学习、记忆和归纳。
除去输入层和输出层之外,一般神经网络还具有隐藏层,隐藏层介于输入层和输出层之间,这些层完全用于分析,其函数联系输入层变量和输出层变量,使其更好地拟合训练样本。隐藏层的功能主要是增加ANN的复杂性,使算法能够模拟更为复杂的非线性关系,但隐藏层过多会导致过度拟合的问题。
神经网络的基本原理:(编辑器不方便输入公式,只好从word里截图放上来。另f(x)为传递函数。)

简单神经网络的拓扑结构如图所示:
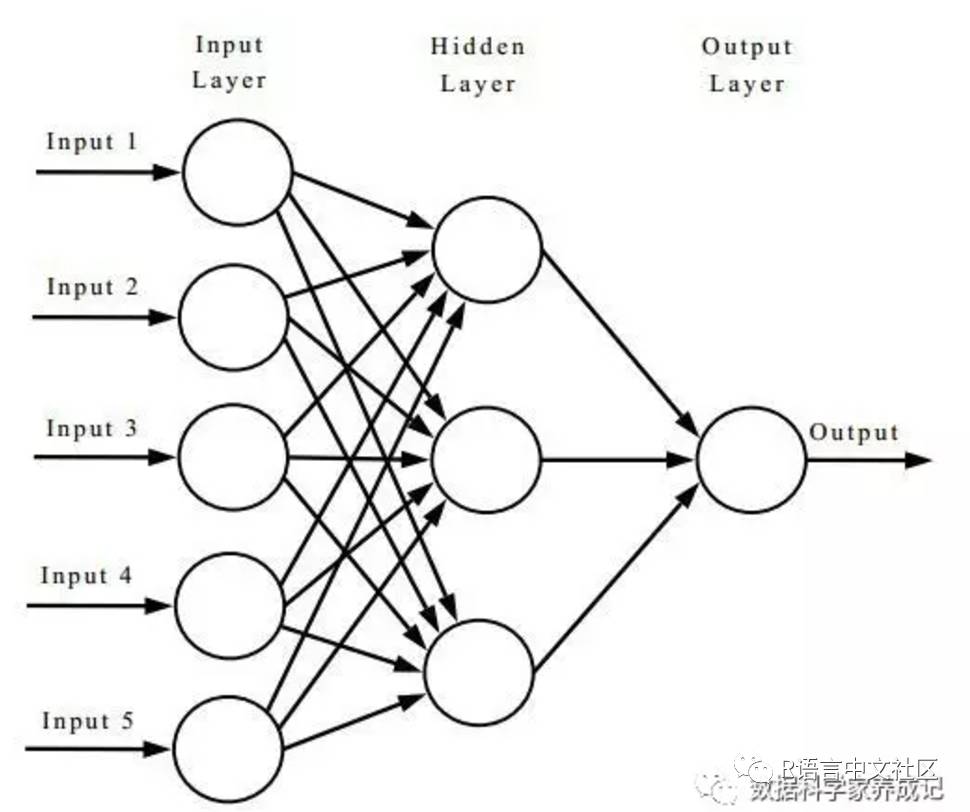
神经网络的训练:
人工神经网络在进行学习前,必须建立一个训练样本使ANN在学习过程有一个参考,训练样本的建立来自于实际系统输入与输出或是以往的经验。举个简单的例子:
洗衣机洗净衣服的时间与衣服的衣料、数量和肮脏程度等因素有关,因此我们必须针对不同的衣料、数量和肮脏程度统计出洗衣所需时间,建立一个训练样本,不同衣服的衣料、数量和肮脏程度就是ANN的输入,而洗衣所需时间则为ANN的目标值,即输出。
ANN的学习就是不断调整权重的过程:
1) 通过输入节点将输入变量加以标准化,标准化后的变量数值落在0和1之间,或者-1到1之间。
2) 将网络权重的初始值设定为0(或随机产生),通过各节点的函数来估计数据的目标变量值。
3) 比较实际值和估计值之间的误差,并根据误差值重新调整各权重的偏置。
4) 反复执行步骤2,一直到实际值和估计值之间的误差最小,此时停止学习以获得最佳权重。
ANN常用传递(激活)函数包括线性函数、阶梯函数、Sigmoid函数、分段线性函数以及高斯函数和双曲正切函数等,具体函数类型可自行查找。一些传递函数如图所示:
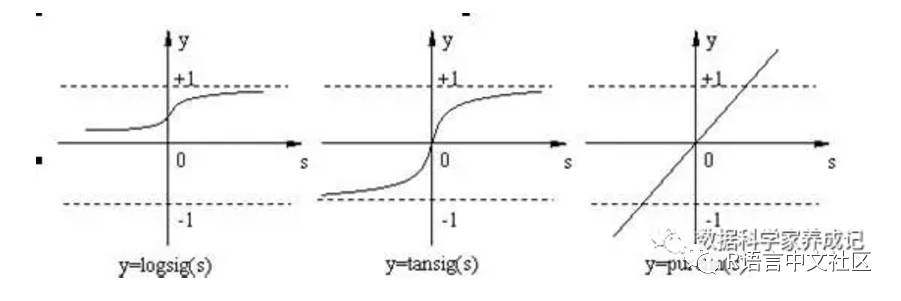
简单而言,含有隐藏层的神经网络使得我们能够处理较为复杂的分类问题。
人工神经网络的简单R语言实现
R语言中已经有多个关于神经网络的学习包,包括nnet、AMORE、neuralnet和RSSNS包,nnet提供了最常见的前馈反向传播神经网络算法。AMORE包则更进一步提供了更为丰富的控制参数,并可以增加多个隐藏层。neuralnet包的改进在于提供了弹性反向传播算法和更多的激活函数形式,而RSNNS包则扩充了其它拓扑结构和网络模型。
我们使用数据挖掘导论一书中的简单数据例子,利用AMORE包来实现简单的BP神经网络。数据如图所示:
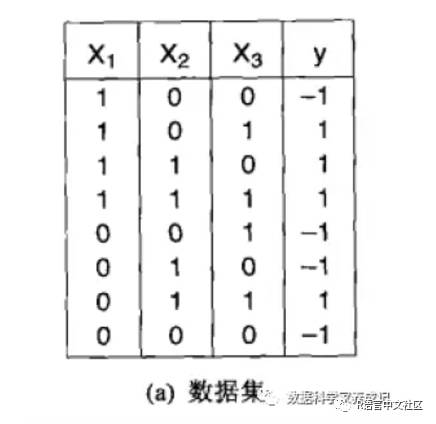
对该数据集进行神经网络的训练,代码如下:
library(AMORE) #加载AMORE包
x1=c(1,1,1,1,0,0,0,0)
x2=c(0,0,1,1,0,1,1,0)
x3=c(0,1,0,1,1,0,1,0)
y=c(-1,1,1,1,-1,-1,1,-1)#导入数据
p<-cbind(x1,x2,x3)
target=y#设定输入层和输出层
net <- newff(n.neurons=c(3,1,1),
learning.rate.global=1e-2,momentum.global=0.4,
error.criterium="LMS",Stao=NA,hidden.layer="tansig",
output.layer="purelin",method="ADAPTgdwm")
#指定3个输入点,隐藏层和输出层节点数各为1,隐藏层传递函数为tansig,输出层传递函数为purelin,收敛判据为最小平方法,这样一个BP神经网络模型就构建起来了。
result <- train(net,p,target,error.criterium="LMS",
report=TRUE,show.step=100,n.shows=5)#对构建好的模型进行样训练
a<-sim(result$net,p)#查看结果

对比输出的a值和数据中的y值,可见神经网络的建模结果与实际完全符合。
结语
这些看似高深莫测的算法,背后的数学原理实则并不吓人,当然了,神经网络是一个博大精深的算法群,现在热门的深度学习其实就是神经网络的一种拓展,要想在机器学习和人工智能领域有所突破,深究这些算法的基本原理和编程实现方式是必不可少的。



微信回复关键字即可学习
回复 R R语言快速入门免费视频
回复 统计 统计方法及其在R中的实现
回复 用户画像 民生银行客户画像搭建与应用
回复 大数据 大数据系列免费视频教程
回复 可视化 利用R语言做数据可视化
回复 数据挖掘 数据挖掘算法原理解释与应用
回复 机器学习 R&Python机器学习入门





