每秒1000000000000000000次运算!Cerebras新超级计算机打造世界最大1350万核心AI集群

新智元报道
新智元报道
【新智元导读】没有什么问题是一台AI计算机解决不了的,如果有,那就用16台!
明星芯片企业Cerebras带着它餐盘大小的芯片来了,这次有16个!
更大、更快、更好用

Andromeda是一个由16台Cerebras CS-2计算机连接起来的集群,拥有1350万个AI核心,远远超过全球超算TOP500冠军Frontier的870万个核心。

该计算机还采用了18,176个AMD Epyc中央处理单元的芯片。

Andromeda由Cerebras晶圆级引擎Wafer Scale Engine(WSE-2)提供核心算力。
处理器是由被称为晶圆的硅盘制成的。在芯片制造过程中,一块晶圆被分割成几十个长方形,然后每个长方形被变成一个单独的处理器。

但是,Cerebras另辟蹊径,没有将晶圆分割成几十个小处理器,而是将其变成一个拥有数万亿晶体管的大处理器。
WSE-2是有史以来最大的芯片,包含2.6万亿个晶体管,组成85万个内核,面积超过46225平方毫米。Andromeda超级计算的芯片拼起来,有16个餐盘那么大!
相比之下,英伟达最大的GPU只有540亿个晶体管,面积为815平方毫米。

用大芯片赚足眼球后,Cerebras打起了Andromeda的三大招牌。
首先,Andromeda运行AI任务的设置非常简单。在严格的数据并行模式下,Andromeda实现了CS-2简易的模型分配,以及从1到16个CS-2的单键扩展。
Cerebras表示,用户只需3天时间,就可以在不对代码做任何改动的前提下,组装完成16个CS-2,进行AI任务处理。
其次,它的编程很简单。Cerebras的编译器处理了所有的细节和善后工作,用户只需输入一行代码,指定在多少个CS-2上运行,然后就大功告成了。
Andromeda可由多个用户同时使用,这意味着该超算不仅可以供一个用户从事一项工作,还可以同时服务于16个不同的用户从事16项不同的工作,工作效率和灵活度瞬间拉满。
更重要的是,这个系统展示了近乎完美的线性可伸缩性。
「近乎完美」的可伸缩性
如此庞大的模型会遇到算力瓶颈问题,系统需求已经远远超出了单个计算机系统的处理能力。单个GPU的内存约为16GB,而GPT-3等模型所需的内存往往高达几百TB。

像过去一样,单纯进行简单粗暴的算力扩展,已经难以满足需求。
因此,系统集群变得至关重要。而如何实现集群,是一个最关键的问题。要让每台机器都保持忙碌,否则系统的利用率就会下降。
Cerebras 正是为了解决这个问题。
与任何已知的基于GPU的集群不同,Andromeda在GPT级大型语言模型中展现了「近乎完美」的可伸缩性。在GPT-3、GPT-J和GPT-NeoX中,Andromeda的处理能力随CS-2数量的增加呈现了近乎完美的线性增长。
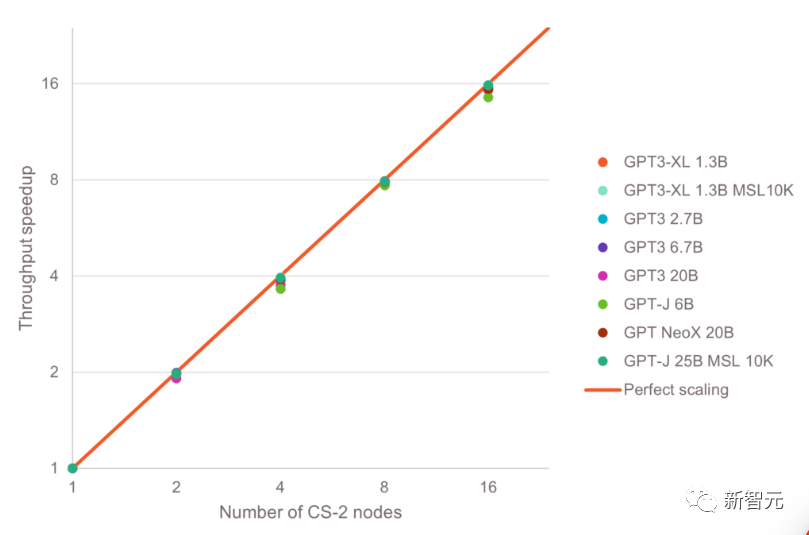
这意味着,在集群中每增加一台CS-2计算机,整体的训练时间会以近乎线性的趋势减少。

做到这一点,离不开芯片与存储、分解和集群技术的协同工作。
Weight Memory & MemoryX:实现极速扩展
这一架构灵活性极强,支持4TB到2.4PB的存储配置,2000亿到120万亿的参数大小。
而通过软件执行模式Weight Memory,可以将计算和参数存储分解,使规模和速度得以独立且灵活地扩展,同时解决了小型处理器集群存在的延迟和内存带宽问题。
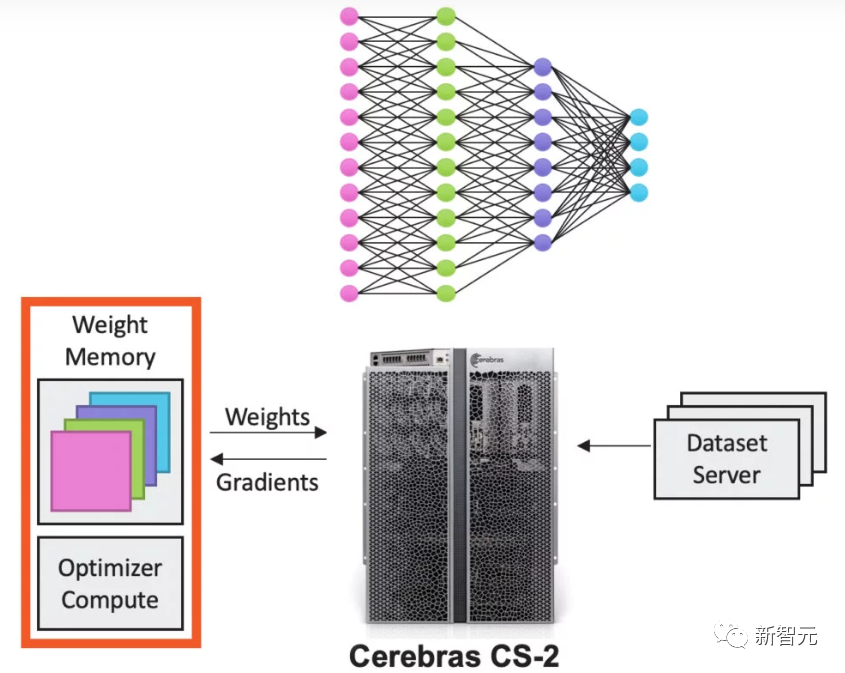
最终,WSE 2可以提供高达 2.4 PB 的高性能内存,CS-2 可以支持具有多达 120 万亿个参数的模型。
Cerebras SwarmX:提供更大、更高效的集群
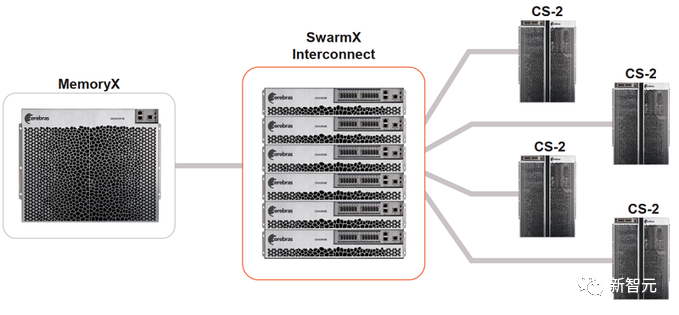
最终,SwarmX 可以将CS-2 系统从2个扩展到192 个,鉴于每个 CS-2 提供85万个 AI 优化内核,Cerebras 便可连接 1.63 亿个 AI 优化内核集群。
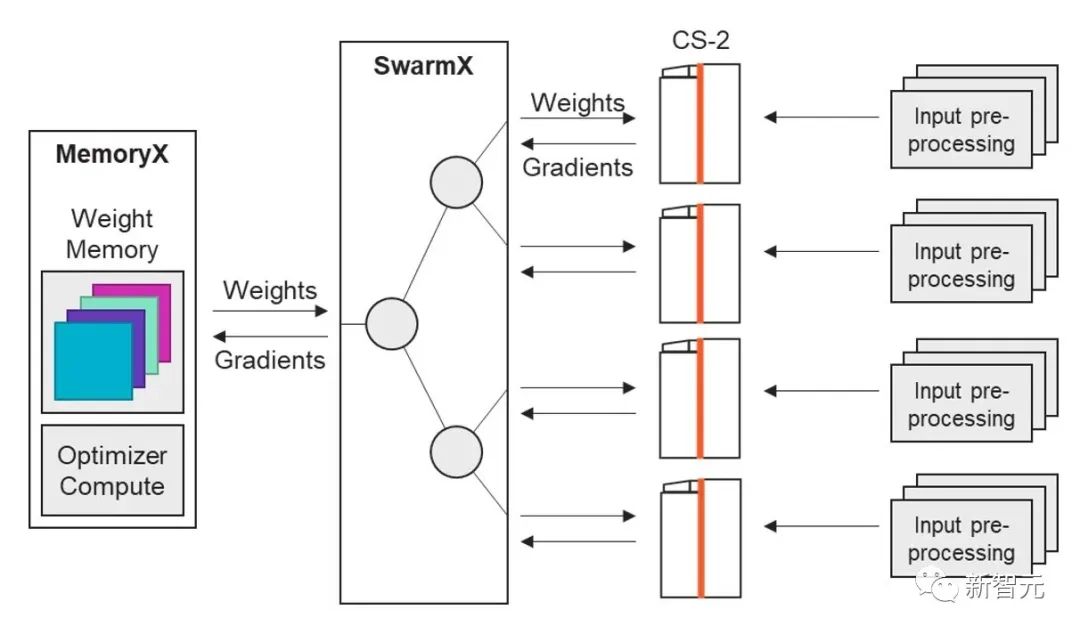
同时,Cerebras WSE-2基于细粒度数据流架构,其 85万个 AI 优化计算内核可以单独忽略零。
Cerebras 架构独有的数据流调度和巨大的内存带宽,使这种类型的细粒度处理能够加速所有形式的稀疏性。这些都是其他硬件加速器,包括GPU,根本无法做到的事情。
Cerebras表示,可以训练超过90%的稀疏性模型,达到最先进的精度。
目前,包括美国阿贡国家实验室、AMD和剑桥大学等多名用户已经使用了Andromeda超算系统,都对其近乎完美的线性可收缩性能力赞不绝口。

其中,与阿贡国家实验室合作的基于HPC的COVID-19研究还入选有「超算领域的诺贝尔奖」之称的戈登·贝尔奖。

拥有世界最大的芯片和协同技术,Cerebras能否挑战目前超算Top 1的Frontier?我们拭目以待。







