MLPerf权威发榜!英伟达「史上最强GPU」H100,被这个12nm芯片碾压
![]()
新智元报道

新智元报道
【新智元导读】MLPerf Inference v2.1榜单正式公布!中国AI芯片企业首次超越英伟达「史上最强GPU」H100,以95784 FPS的单卡算力,夺得ResNet-50模型算力全球第一。

MLPerf是业内公认的国际权威AI性能基准评测,由图灵奖得主大卫·帕特森(David Patterson)联合谷歌、英伟达 、英特尔、Facebook、浪潮等全球AI领军企业,以及来自哈佛大学、斯坦福大学等学术机构的研究人员创立。
该测评以其标准严格、测评严谨而著称,英伟达、高通等国际AI芯片企业均携最强产品参加测评,竞争十分激烈,各赛道均有数百项产品提交成绩。
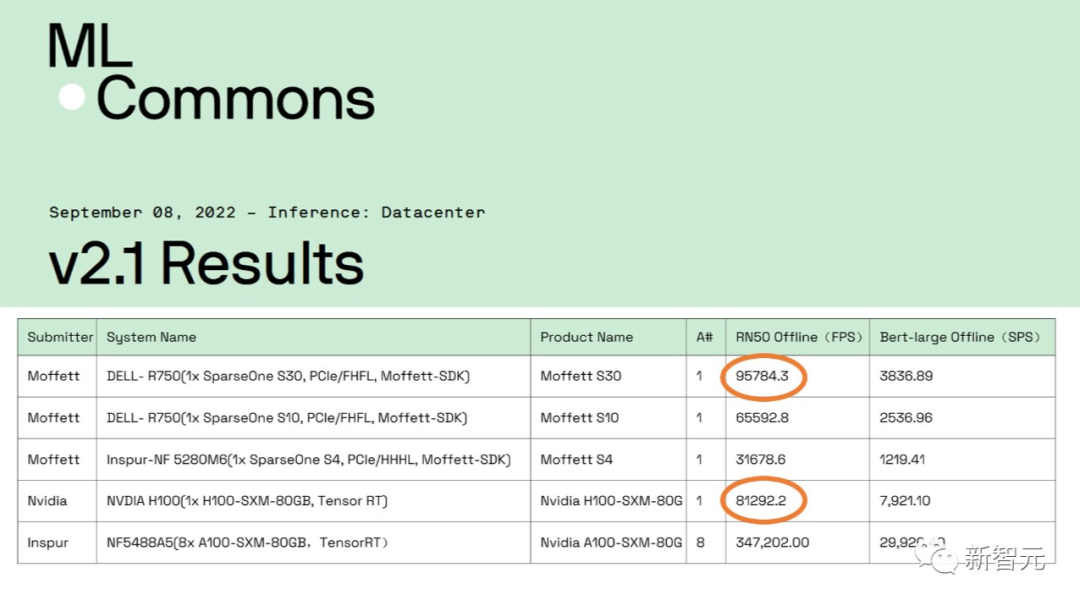
以上数据摘自MLCommons官网MLPerf Inference v2.1测试结果
墨芯首次参赛,单卡算力全球第一
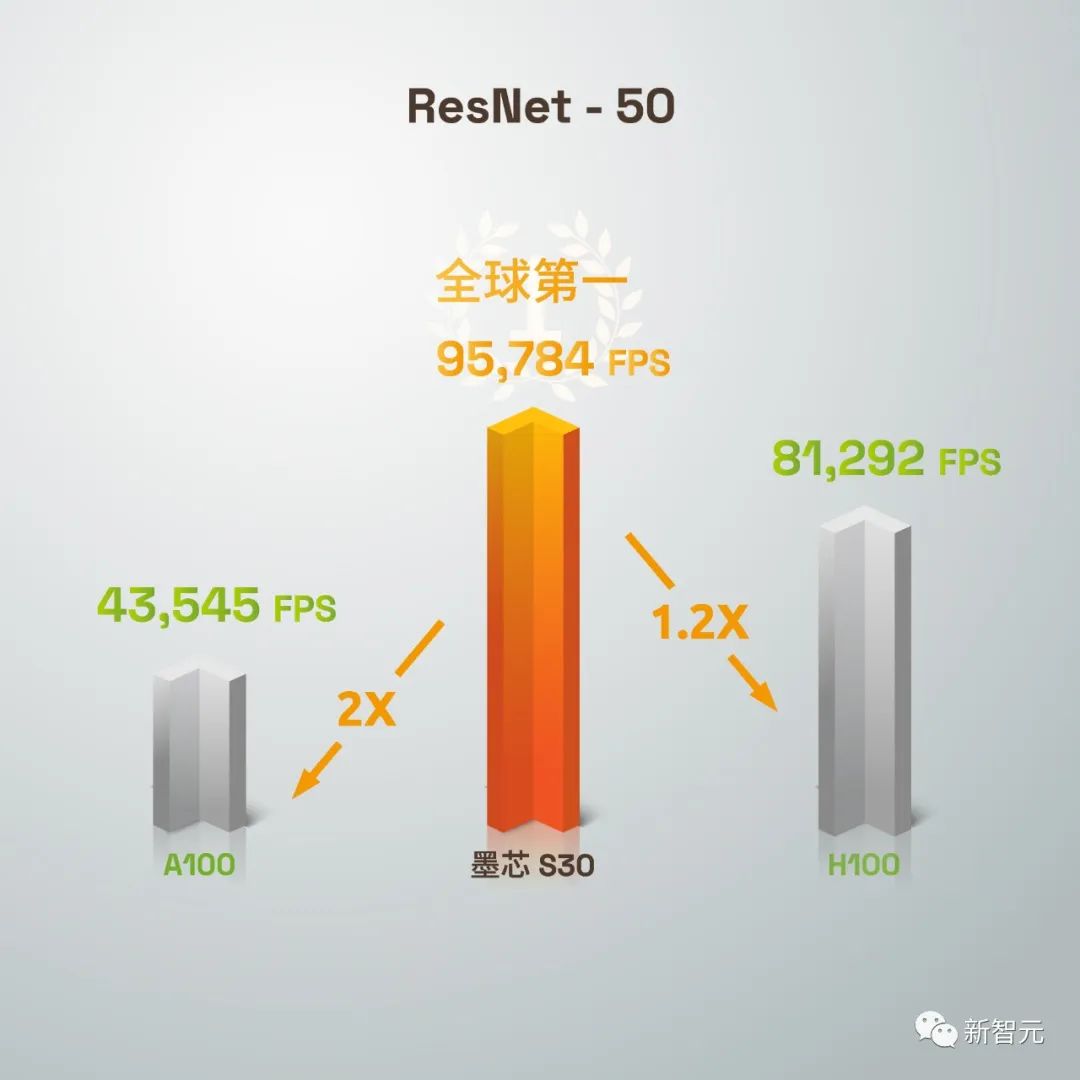
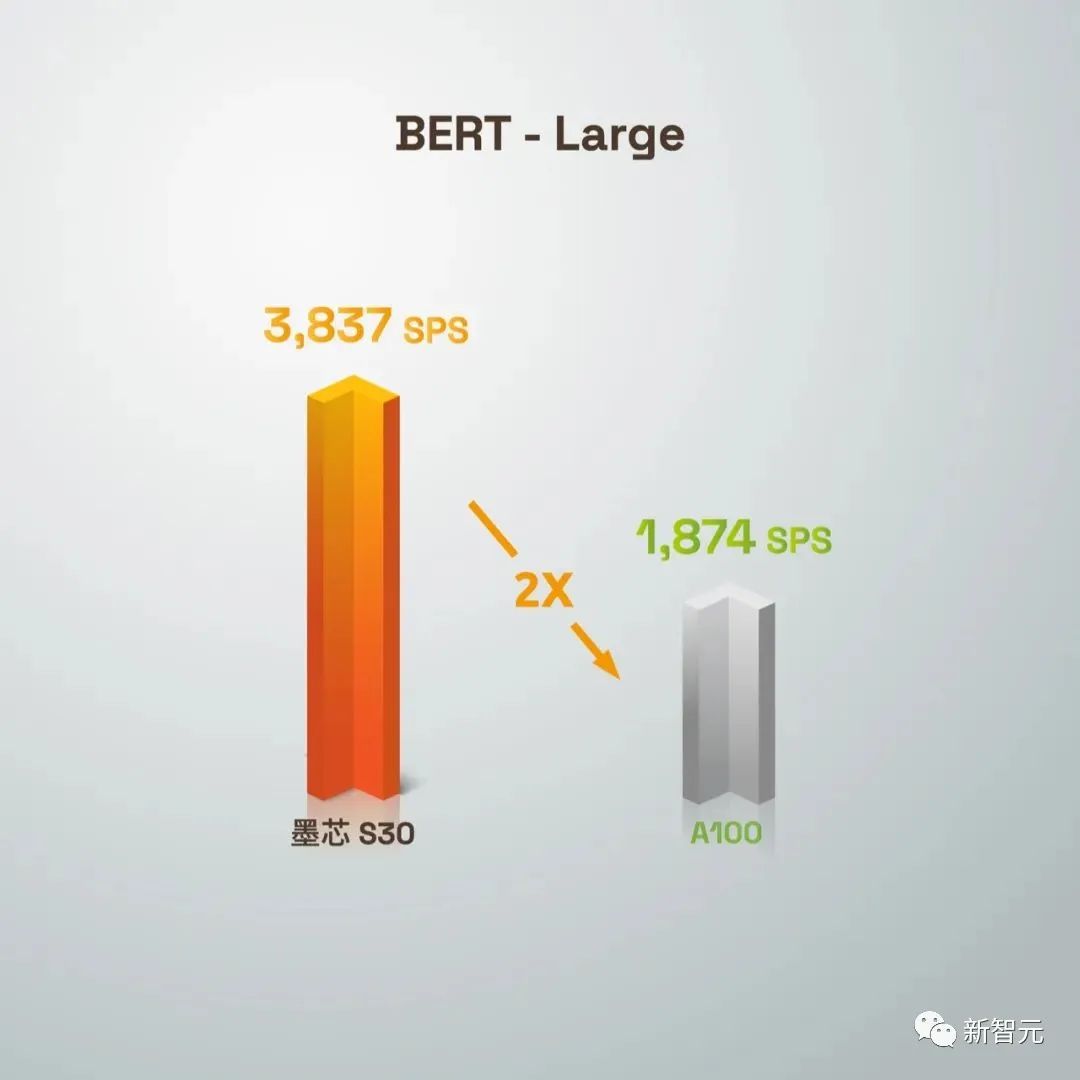

精度要求99%以上,经受严格检验

中秋佳节 好书相赠
转眼又是一个中秋,愿所有人中秋快乐,团圆美满!
为感谢大家一直以来对新智元的关注,我们精选了一批AI好书,作为福利放送给大家~
【领取流程】
关注公众号并在本文留言,前30名获赞者将获得价值68元的《智能革命》一本,截止到9月13日,快来评论吧!


登录查看更多
相关内容

NVIDIA(全称NVIDIA Corporation,NASDAQ:NVDA,发音:IPA:/ɛnvɪdɪə/,台湾官方中文名为輝達),创立于1993年4月,是一家以设计显示芯片和芯片组为主的半导体公司。NVIDIA亦会设计游戏机核心,例如Xbox和PlayStation 3。NVIDIA最出名的产品线是为个人与游戏玩家所设计的GeForce系列,为专业工作站而设计的Quadro系列,以及为服务器和高效运算而设计的Tesla系列。
NVIDIA的总部设在美国加利福尼亚州的圣克拉拉。是一家无晶圆(Fabless)IC半导体设计公司。"NVIDIA"的读音与英文"video"相似,亦与西班牙文evidia(英文"envy")相似。现任总裁为黄仁勋。
专知会员服务
27+阅读 · 2020年4月5日
专知会员服务
13+阅读 · 2019年11月26日
Arxiv
0+阅读 · 2022年11月23日


相关VIP内容
专知会员服务
27+阅读 · 2020年4月5日
专知会员服务
13+阅读 · 2019年11月26日
相关资讯