比A100性能高4.5倍!英伟达H100横扫AI推理基准测试

新智元报道
新智元报道
【新智元导读】NVIDIA H100 Tensor Core GPU在MLPerf行业标准AI基准测试中首次亮相,创下了所有工作负载推理的世界纪录,提供的性能比上一代GPU高4.5 倍。
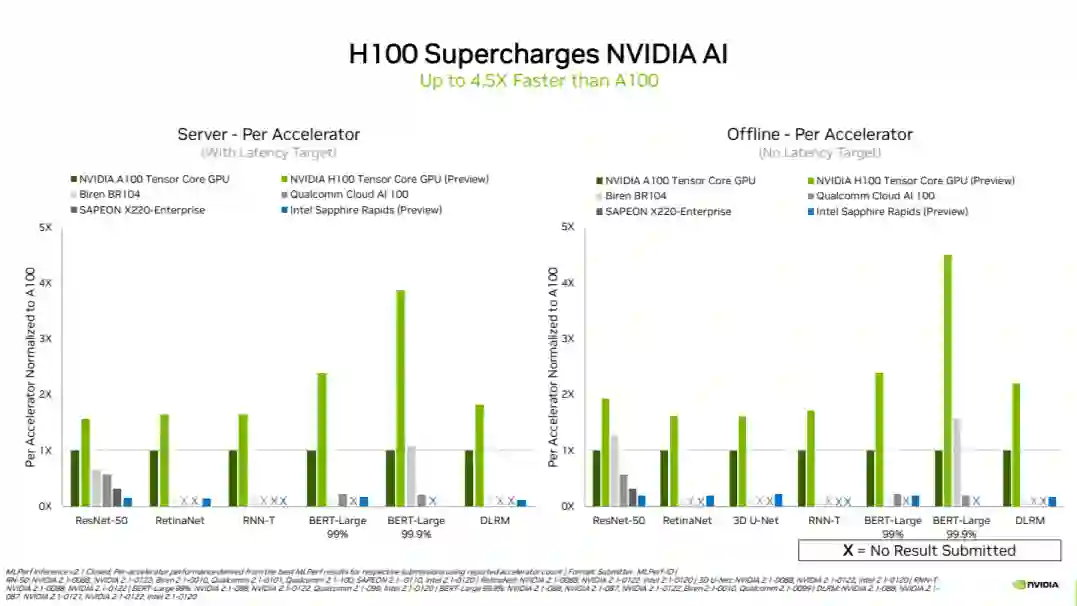
英伟达为何看重MLPerf测试的结果
英伟达在市场上还处于领先地位吗?
此次,对于在MLPerf测试中取得的结果,英伟达还是比较满意的。

登录查看更多
相关内容

NVIDIA(全称NVIDIA Corporation,NASDAQ:NVDA,发音:IPA:/ɛnvɪdɪə/,台湾官方中文名为輝達),创立于1993年4月,是一家以设计显示芯片和芯片组为主的半导体公司。NVIDIA亦会设计游戏机核心,例如Xbox和PlayStation 3。NVIDIA最出名的产品线是为个人与游戏玩家所设计的GeForce系列,为专业工作站而设计的Quadro系列,以及为服务器和高效运算而设计的Tesla系列。
NVIDIA的总部设在美国加利福尼亚州的圣克拉拉。是一家无晶圆(Fabless)IC半导体设计公司。"NVIDIA"的读音与英文"video"相似,亦与西班牙文evidia(英文"envy")相似。现任总裁为黄仁勋。
专知会员服务
61+阅读 · 2019年12月29日




相关VIP内容
专知会员服务
61+阅读 · 2019年12月29日
相关资讯