语言技术平台(LTP)更新:基于Bi-LSTM的语义角色标注系统
作者:刘洋,郭江,车万翔
1. 引言
对句子进行深入的语义分析,一直是自然语言处理所追求的目标。例如[1]:
• 昨天 , 张三 用球拍 打了 李四 。
• 李四 昨天 被 张三 用球拍 打了 。
• 昨天 ,用一个球拍, 张三 把 李四 打了。
这些句子尽管结构不同,依存句法树也不同,但表达的语义却是相同的。其中都有相同的谓词、时间、施事和受事者。语义分析即是通过句子中的句法信息和词语含义,推导出反应这个句子含义的某种形式表示,而本文的研究重点—语义角色标注[2,3] (Semantic Role Labeling,简称SRL),正是通过对这些语义角色进行标注,研究语义问题的一个简单直接的方法。
语义角色标注是自然语言处理的底层技术,可以被应用于多种语言处理任务中。如果语义角色标注问题能够被有效地解决,将对自动问答、机器翻译、自动文摘、信息抽取等任务产生直接而有力的帮助。而且语义角色标注是一个浅层的语义分析技术,其发展必将带动其他深层语义任务的进步。
近年来,深度学习在机器学习领域有了较大的进展,已经被广泛的应用于自然语言处理的很多领域上。这种方法的使用将人们从特征工程的工作中解放出来。同时,如LSTM、GRU等深度循环神经网络也能够更加科学的在句子上进行计算,有效地缓解句子中长距离依赖的问题。在很多自然语言处理的问题中,深度学习已经表现出其强大的优势。
在之前学者对SRL的研究中,需要进行大量特征工程工作,这也导致了模型的泛化能力不足。在最近的研究中,人们发现使用深度学习方法和循环神经网络模型,可以较好地表示上下文和句法特征,能够有效地减少特征工程工作,同时模型也能够得到更好的泛化效果。本文将LSTM循环神经网络模型应用于SRL,以对上下文和句法路径特征建模,在模型中自动学习解决问题的有效特征,从而达到减少特征工程,提高模型泛化能力的效果。
2. 什么是语义角色标注
2.1 任务定义
语义角色标注任务在信息抽取中定义为标注一个事件的构成,即事件的施事者、受事者、事件、地点、方式等等。在计算语言学中定义为对句中给定谓词(动词、形容词等)标注其论元,并赋予这些论元一个语义角色来描述他们相对于谓词的语义含义。
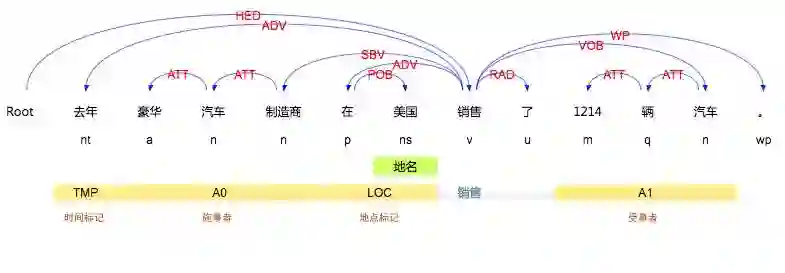
图1 语义角色标注示例
该方法不对整个句子进行详细的语义分析,只对给定谓词进行语义角色的标定。也就是说此任务是基于谓词的,不考虑谓词改变但是语义不变的情况,例如“豪华汽车制造商去年销售了1214辆汽车。”和“豪华汽车制造商去年汽车的出售量是1214辆。”虽然语义相同,但是谓词不同,那么语义标注结果也不同,如果需要得到相应的信息就需要进一步的处理。另外语义角色标注任务不关心谓词的时态信息,例如“豪华汽车制造商将要销售大量汽车。”和“豪华汽车制造商已销售了大量汽车。”的标注结果应是相同的。
LTP系统SRL部分除了传统的SRL任务,还实现了谓词识别(Predicate Identification,PI)系统。在传统的语义角色标注任务定义中,是不包括谓词的识别的,模型的输入数据已经包含需要标注的谓词信息,但在LTP系统希望实现从生文本生成各个阶段分析结果,SRL模块只依赖词性和句法树,需要模块标注谓词,才能进行之后的语义角色标注,于是谓词识别也是系统工程的一部分。
2.2 基本方法
传统的语义角色标注大致分为四个步骤进行[4,5]。
1. 将问题给出的句子进行句法分析得到句法树。并对句法树进行剪枝,去掉不可能成为语义角色的标注单元。
2. 使用分类器给选出的候选论元。
3. 对论元进行分类,类别为所有的语义角色标签。有些系统中也将2、3步骤合为一步,也就是将非语义角色也作为一个分类标签,在本文中就是使用的这种方法。
4. 后处理。在此步骤中,常常做一些强制的一致性限制。
可以看出,语义角色标注的核心就是对论元进行语义标签的分类。语义角色标注的不同方法,其实就是针对这个问题设计不同的更加高效的分类器。
3. 基于Bi-LSTM的语义角色分类器
基于我中心2016年论文《A Unified Architecture for Semantic Role Labeling and Relation Classification》[6]中所提出的基于Bi-LSTM的SRL模型,我们更新了LTP中的SRL模块,以下是模型的具体介绍。
3.1 Bi-LSTM
由于序列问题的数据中序列长度有差距,很难使用之前的方法固定维度输入,人们设计循环神经网络RNN(recurrent neural network)来处理序列问题。但是普通的RNN存在两个问题。一是长距离依赖,序列该位置的输出可能依赖于之前较远位置的输入。二是梯度消失和梯度爆炸,这种问题在处理长序列的时候尤为明显。
为了解决以上问题,人们提出了LSTM(Long-Short term memory)模型[7]。这种RNN架构专门用于解决RNN模型的梯度消失和梯度爆炸问题。隐藏的神经元由多个记忆块(memory block)实现,由三个乘法门控制记忆块的激活状态:输入门(input gate)、输出门(output gate)、忘记门(forget gate)。这种结构可以使之前输入的信息保存在网络中,并一直向前传递,输入门打开时新的输入才会改变网络中保存的历史状态,输出门打开时保存的历史状态会被访问到,并影响之后的输出,忘记们用于清空之前保存的历史信息。LSTM模型的结构决定了该模型有能力处理以上描述的RNN存在的两个问题。现在已经被广泛使用在各种序列问题之中。
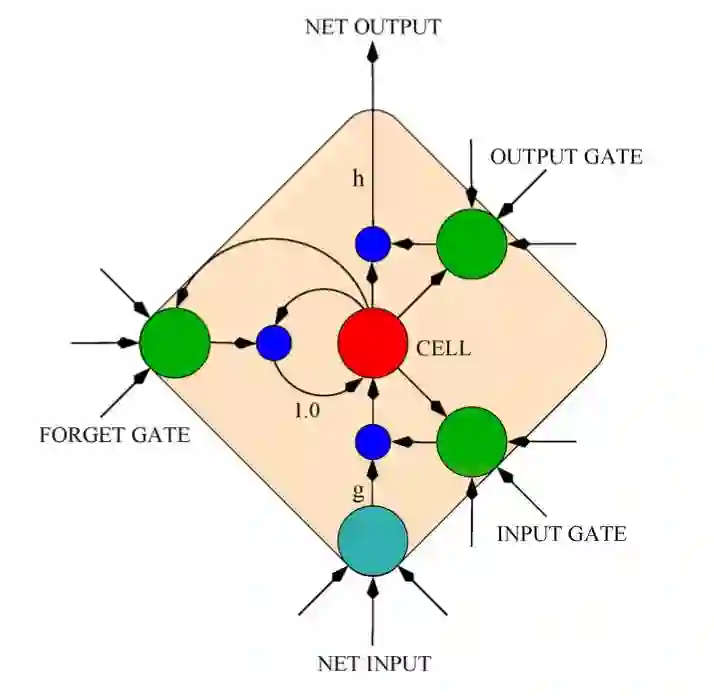
图2 LSTM记忆块单元[7]
由于LSTM的输入是单方向的,往往忽略了未来的上下文信息。双向LSTM的基本思想是使用一个训练序列向前向后各训练一个LSTM模型。再将两个模型的输出进行线性组合,以达到序列中每一个节点都能完整的依赖所有上下文信息。
3.2 上下文表示和句法路径表示
本文介绍的模型使用的词向量的表示是由预训练的词向量(常量,在训练时不更新)和随机初始化的词向量(模型参数,训练时更新)拼接得到的。将表示词、词性的向量(随机初始化)的拼接,按照句子中词顺序传入双向LSTM。得到LSTM在每个输入词位置的输出得到该词的上下文表示。句中词

其中

LSTM的输入可表示为:


其中
随着深度机器学习技术的发展,其也被应用于NLP任务进行特征的表示。最近,Roth等人使用LSTM来表示句法路径特征[8]得到了不错的效果。本文基于的分类器也是用了LSTM表示的句法路径特征,我们发现判定谓词和论元关系时,谓词和论元在句法树中的相对位置至关重要。我们认为使用句法路径信息是解决语义角色标注中长距离依赖问题的关键。这里使用路径表示论元相对谓词的句法关系。句法路径即为在语法树上从论元走到论元的路径,由于树结构的限制,该路径仅有一条,而且该路径中和根节点最近的一点也唯一,即两个点的最近公共祖先(nearest common ancestor)这里用





其中


语义角色标注模型用到了上下文表示和句法路径表示,将所有用到的特征表示线性组合,之后通过一个激活函数。最后通过


整体结构如图3所示。
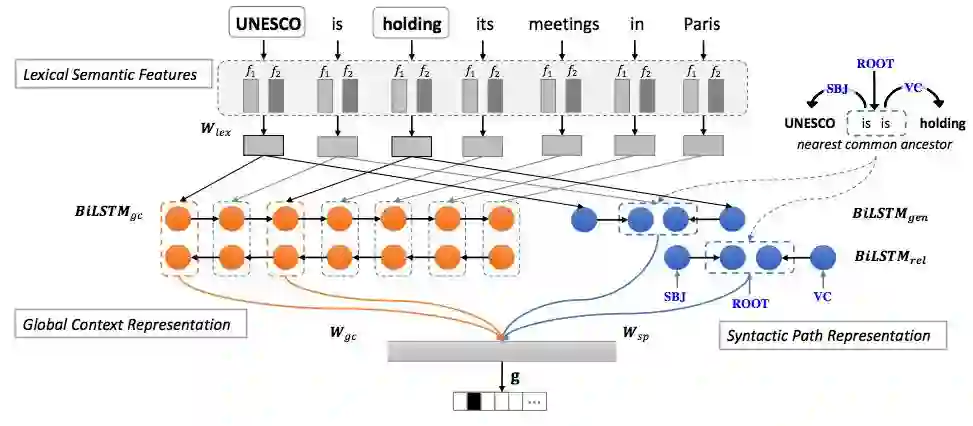
图3 基于Bi-LSTM的语义角色分类器整体架构图[6]
4. 语言技术平台中语义角色标注系统的更新
语言技术平台,简称LTP(Language Technology Platform, LTP),是我实验室历时十余年研发的一整套自然语言处理基础平台。该平台集词法分析(分词、词性标注、命名实体识别)、句法分析(依存句法分析)和语义分析(语义角色标注)等多项自然语言处理子系统于一体,有效解决了自然语言处理技术入行门槛高,准确率、效率偏低,缺少共享数据和程序资源,重复开发现象严重,结果可视化差,错误分析困难,较难真正支持各类应用研究等众多问题。
我们已将最新的基于Bi-LSTM的SRL模块更新到LTP中,发布版本号为3.4.0,见在线演示系统(http://www.ltp-cloud.com/demo/)。下图中展示了我们的在线系统的语义角色标注结果(词性标注结果下方的结果,每一行都是对一个谓词的标注结果,黄色部分所指示的是标注论元的范围,其上的标号表示论元类型)。在本例中,我们挑选并展示了一个存在长距离依赖的标注,第二个谓词是“表示”,词“胡吉亚尼”作为“表示”的A0论元(施事者),被模型准确的标了出来,而这在之前的系统中像这样远距离的谓词-论元是较难召回的。
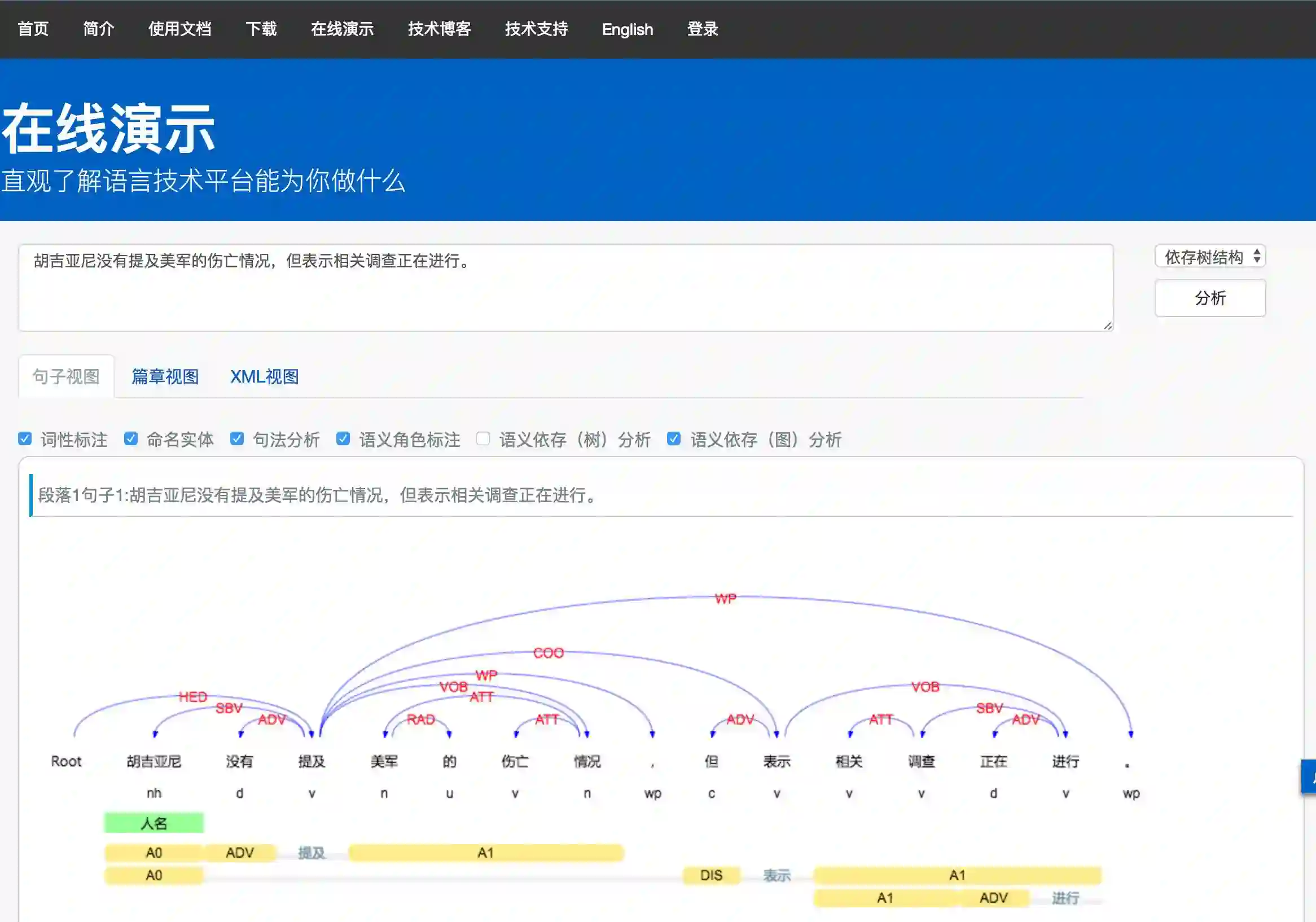
图4 基于Bi-LSTM的语义角色分类器整体架构图
相比于之前基于最大熵(MaxEnt)模型系统,深度学习的Bi-LSTM模型由于召回率的提高,在开发和测试集合的F1值都有所提高。
表1 本文BiLSTM模型和最大熵模型性能对比表
数据集 |
模型 |
MaxEnt |
BiLSTM |
||||
P |
R |
F1 |
P |
R |
F1 |
||
开发集 |
PI |
92.49 |
90.64 |
91.56 |
92.29 |
93.60 |
92.94 |
SRL |
76.68 |
61.75 |
68.41 |
74.65 |
72.33 |
73.47 |
|
pipeline |
72.79 |
59.97 |
65.76 |
71.44 |
67.61 |
69.47 |
|
测试集 |
PI |
90.08 |
88.81 |
89.44 |
88.62 |
91.73 |
90.15 |
SRL |
74.16 |
56.33 |
64.03 |
72.96 |
69.59 |
71.24 |
|
pipeline |
70.18 |
54.76 |
61.52 |
70.82 |
65.56 |
68.08 |
|
同时,在LTP中,我们还更新了如下内容。
1. 修改了之前SRL的接口,解决之前SRL模块内存泄露问题。
2. 将原模型文件SRL文件夹中的模型文件和配置文件完全合并为单文件发布。
3. 增加SRL模块的命令行工具。
4. 更新系统依赖的boost、eigen库。
5. 新增dynet深度学习库。
5. 结语
本文介绍了如何使用深度学习方法进行中文语义角色标注,并与LTP3.3及其更早版本使用的最大熵模型进行了比较。相比于最大熵模型的实现,新的Bi-LSTM模型可以自动提取句子特征,减少了特征工程的工作。对于在语义角色标注任务中的长距离依赖问题,我们重点关注句法路径信息并使用Bi-LSTM对其进行建模,在一定程度上解决了此问题,从而最终提高了系统的性能。我们已将新的基于深度学习的语义角色标注模块更新到语言技术平台(LTP),同时也把该模块代码更新到我们的开源仓库中,欢迎大家使用。
6. 参考文献
[1]. Yih W T, Toutanova K. Automatic semantic role labeling. Human Language Technology Conference of the North American Chapter of the Association of Computational Linguistics, Proceedings, June 4-9, 2006, New York, USA. DBLP. 2006:3-6.
[2]. Màrquez L. Semantic role labeling: past, present and future. Tutorial Abstracts of Acl-Ijcnlp. 2009:3-3.
[3]. Che W. Kernel-Based semantic role labeling. Harbin: Harbin Institute of Technology (in Chinese with English abstract). 2008: 7-9
[4]. Andre F. T. Martins and Mariana S. C. Almeida. Priberam: A turbo semantic parser with second order features. In Proc. of SemEval. 2014:471–476
[5]. Lei T, Zhang Y, Màrquez L, Moschitti A, and Regina Barzilay. High-order low-rank tensors for semantic role labeling. In Proc. of NAACL. 2015:1150–1160
[6]. Guo J,Che W,Wang H,Liu T,Xu J. A Unified Architecture for Semantic Role Labeling and Relation Classification. In Proc. of COLING. 2016:3-6
[7]. Hochreiter S and Schmidhuber J. Long short-term memory. Neural computation. 1997:1735–1780.
[8]. Roth M and Lapata M. Neural semantic role labeling with dependency path embeddings. arXiv preprint arXiv:1605.07515. 2016:3-5
本期责任编辑: 赵森栋
本期编辑: 赵得志
“哈工大SCIR”公众号
主编:车万翔
副主编: 张伟男,丁效
责任编辑: 张伟男,丁效,郭江,赵森栋
编辑: 李家琦,施晓明,张文博,赵得志
长按下图并点击 “识别图中二维码”,即可关注哈尔滨工业大学社会计算与信息检索研究中心微信公共号:”哈工大SCIR” 。





