每日论文 | 谷歌新模型BERT刷新多项NLP任务成绩;三大概率模型详解;另辟蹊径解决多任务学习
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
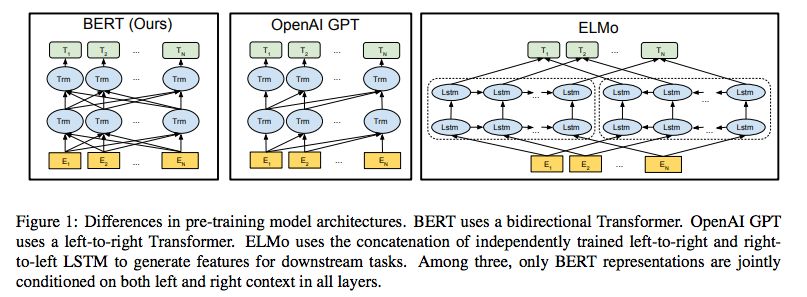
昨日,谷歌发表论文称,他们提出了一种新的语言表示模型BERT(Bidirectional Encoder Representations from Transformers)。和最近的语言表示模型不同,BERT通过考虑所有层的左右两部分语境,对深度双向表示进行预训练。BERT的结构非常简单,但实用性很强,它在11种NLP任务中都获得了最优成绩,比如在GLUE上的得分达到80.4%(提高了7.6%),在MultiNLI上的精确度达到了86.7%(提高了5.6%),在SQuAD v1.1问答测试F1中达到了93.2分,比人类最高水平还高2.0%。
地址:https://arxiv.org/abs/1810.04805
A Tale of Three Probabilistic Families: Discriminative, Descriptive and Generative Models
格雷南德的模式理论(patter theory)是一个数学框架,其模式由代数结构随机变量的概率模型表示。在本文中,我们回顾了概率模型的“三大家族”,即判别模型、描述模型和生成模型。我们将在通用框架内浏览这些模型,并探索它们之间的联系。
地址:https://arxiv.org/abs/1810.04261
Multi-Task Learning as Multi-Objective Optimization
在多任务学习中,各任务通常是联合解决的,它们之间通常有相同的归纳偏差。多任务学习的本质是多目标问题,因为不同的人物之间可能会冲突,所以需要进行权衡。常见的折中方案是优化代理目标,最小化每个人物损失的加权线性组合。但是这种方法只有在简单任务中才能有效。在本文中,我们将多任务学习看作多目标优化,其总体目标就是找到帕累托最优解。最终证明,我们的方法在最近的多任务学习问题上的表现达到了最优。
地址:https://arxiv.org/abs/1810.04650