【DeepMind 公开课-深度强化学习教程笔记04】不基于模型的预测
点击上方“专知”关注获取更多AI知识!
【导读】Google DeepMind在Nature上发表最新论文,介绍了迄今最强最新的版本AlphaGo Zero,不使用人类先验知识,使用纯强化学习,将价值网络和策略网络整合为一个架构,3天训练后就以100比0击败了上一版本的AlphaGo。Alpha Zero的背后核心技术是深度强化学习,为此,专知有幸邀请到叶强博士根据DeepMind AlphaGo的研究人员David Silver《深度强化学习》视频公开课进行创作的中文学习笔记,在专知发布推荐给大家!(关注专知公众号,获取强化学习pdf资料,详情文章末尾查看!)
叶博士创作的David Silver的《强化学习》学习笔记包括以下:
笔记序言:【教程】AlphaGo Zero 核心技术 - David Silver深度强化学习课程中文学习笔记
《强化学习》第四讲 不基于模型的预测
《强化学习》第五讲 不基于模型的控制
《强化学习》第六讲 价值函数的近似表示
《强化学习》第七讲 策略梯度
《强化学习》第八讲 整合学习与规划
《强化学习》第九讲 探索与利用
以及包括也叶博士独家创作的强化学习实践系列!
强化学习实践一 迭代法评估4*4方格世界下的随机策略
强化学习实践二 理解gym的建模思想
强化学习实践三 编写通用的格子世界环境类
强化学习实践四 Agent类和SARSA算法实现
强化学习实践五 SARSA(λ)算法实现
强化学习实践六 给Agent添加记忆功能
强化学习实践七 DQN的实现
今天《强化学习》第四讲 不基于模型的预测;
简介 Introduction
通过先前的讲解,我们明白了如何从理论上解决一个已知的MDP:通过动态规划来评估一个给定的策略,并且得到最优价值函数,根据最优价值函数来确定最优策略;也可以直接进行不基于任何策略的状态价值迭代得到最优价值函数和最优策略。
从本讲开始将花连续两讲的时间讨论解决一个可以被认为是MDP、但却不掌握MDP具体细节的问题,也就是讲述如何直接从Agent与环境的交互来得得到一个估计的最优价值函数和最优策略。这部分内容同样分为两部分,第一部分也就是本讲的内容,聚焦于策略评估,也就是预测,直白的说就是在给定的策略同时不清楚MDP细节的情况下,估计Agent会得到怎样的最终奖励。下一讲将利用本讲的主要观念来进行控制进而找出最优策略,最大化Agent的奖励。
本讲内容同样分为三个小部分,分别是蒙特卡洛强化学习、时序差分强化学习和介于两者之间的λ时序差分强化学习。相信读者在阅读本讲内容后会对这三类学习算法有一定的理解。
蒙特卡洛强化学习 Monte-Carlo Reinforcement Learning
蒙特卡洛强化学习指:在不清楚MDP状态转移及即时奖励的情况下,直接从经历完整的Episode来学习状态价值,通常情况下某状态的价值等于在多个Episode中以该状态算得到的所有收获的平均。
注:收获不是针对Episode的,它存在于Episode内,针对于Episode中某一个状态。从这个状态开始经历完Episode时得到的有衰减的即时奖励的总和。从一个Episode中,我们可以得到该Episode内所有状态的收获。当一个状态在Episode内出现多次,该状态的收获有不同的计算方法,下文会讲到。
注:与Episode比较贴近的中文是“经历片段”,有被翻译成“回合”,这其实并不准确反映其意思,由于一直没找到比较准确的中文词汇和Episode对应,因此一直在使用英文。同时也尽可能的添加一些说明来描述Episode到底是什么。
完整的Episode 指必须从某一个状态开始,Agent与Environment交互直到终止状态,环境给出终止状态的即时收获为止。
完整的Episode不要求起始状态一定是某一个特定的状态,但是要求个体最终进入环境认可的某一个终止状态。
蒙特卡洛强化学习有如下特点:不基于模型本身,直接从经历过的Episode中学习,必须是完整的Episode,使用的思想就是用平均收获值代替价值。理论上Episode越多,结果越准确。
蒙特卡洛策略评估 Monte-Carlo Policy Evaluation
目标:在给定策略下,从一系列的完整Episode经历中学习得到该策略下的状态价值函数。
在解决问题过程中主要使用的信息是一系列完整Episode。其包含的信息有:状态的转移、使用的行为序列、中间状态获得的即时奖励以及到达终止状态时获得的即时奖励。其特点是使用有限的、完整Episode产生的这些经验性信息经验性地推导出每个状态的平均收获,以此来替代收获的期望,而后者就是状态价值。通常需要掌握完整的MDP信息才能准确计算得到。
数学描述如下:
基于特定策略 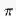
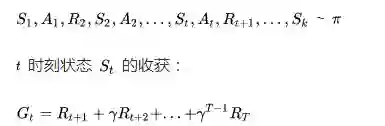
其中 T为终止时刻。
该策略下某一状态 s的价值:
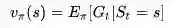
注:
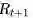
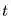
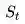
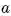
很多时候,即时奖励只出现在Episode结束状态时,但不能否认在中间状态也可能有即时奖励。公式里的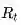
在状态转移过程中,可能发生一个状态经过一定的转移后又一次或多次返回该状态,此时在一个Episode里如何计算这个状态发生的次数和计算该Episode的收获呢?可以有如下两种方法:
首次访问蒙特卡洛策略评估
在给定一个策略,使用一系列完整Episode评估某一个状态s时,对于每一个Episode,仅当该状态第一次出现时列入计算:
状态出现的次数加1:
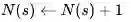
总的收获值更新:
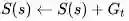
状态s的价值:
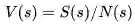
当
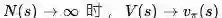
每次访问蒙特卡洛策略评估
在给定一个策略,使用一系列完整Episode评估某一个状态s时,对于每一个Episode,状态s每次出现在状态转移链时,计算的具体公式与上面的一样,但具体意义不一样。
状态出现的次数加1:
总的收获值更新:
状态s的价值:
当
示例:二十一点游戏 Blackjack Example
该示例解释了Model-Free下的策略评估问题和结果,没有说具体的学习过程。
状态空间:(多达200种,根据对状态的定义可以有不同的状态空间,这里采用的定义是牌的分数,不包括牌型)
当前牌的分数(12 - 21),低于12时,你可以安全的再叫牌,所以没意义。
庄家出示的牌(A - 10),庄家会显示一张牌面给玩家
我有“useable” ace吗?(是或否)A既可以当1点也可以当11点。
行为空间:
停止要牌 stick
继续要牌 twist
奖励(停止要牌):
+1:如果你的牌分数大于庄家分数
0: 如果两者分数相同
-1:如果你的牌分数小于庄家分数
奖励(继续要牌):
-1:如果牌的分数>21,并且进入终止状态
0:其它情况
状态转换(Transitions):如果牌分小于12时,自动要牌
当前策略:牌分只要小于20就继续要牌。
求解问题:评估该策略的好坏。
求解过程:使用庄家显示的牌面值、玩家当前牌面总分值来确定一个二维状态空间,区分手中有无A分别处理。统计每一牌局下决定状态的庄家和玩家牌面的状态数据,同时计算其最终收获。通过模拟多次牌局,计算每一个状态下的平均值,得到如下图示。
最终结果:无论玩家手中是否有A牌,该策略在绝大多数情况下各状态价值都较低,只有在玩家拿到21分时状态价值有一个明显的提升。
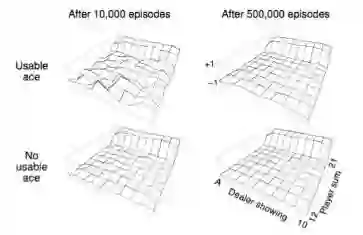
这个例子只是使读者对蒙特卡洛策略评估方法有一个直观的认识。
为了尽可能使读者对MC方法有一个直接的认识,我们尝试模拟多个二十一点游戏牌局信息,假设我们仅研究初始状态下庄家一张明牌为4,玩家手中前两张牌和为15的情形,不考虑A牌。在给定策略下,玩家势必继续要牌,则可能会出现如下多种情形:
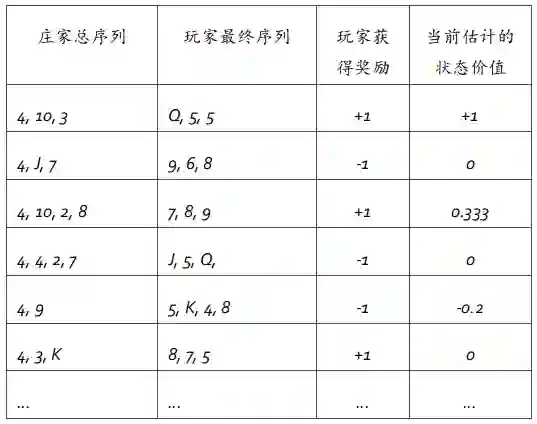
注意:庄家不需遵循个体的当前策略。
可以看到,使用只有当牌不小于20的时候才停止叫牌这个策略,前6次平均价值为0,如果玩的牌局足够多,按照这样的方法可以针对每一个状态(庄家第一张明牌,玩家手中前两张牌分值合计)都可以制作这样一张表,进而计算玩家奖励的平均值。通过结果,可以发现这个策略并不能带来很高的玩家奖励。
这里给出表中第一个对局对应的信息序列(Episode):

可以看出,这个完整的Episode中包含两个状态,其中第一个状态的即时奖励为0,后一个状态是终止状态,根据规则,玩家赢得对局,获得终止状态的即时奖励+1。读者可以加深对即时奖励、完整Episode的理解。
在使用蒙特卡洛方法求解平均收获时,需要计算平均值。通常计算平均值要预先存储所有的数据,最后使用总和除以此次数。这里介绍了一种更简单实用的方法:
累进更新平均值 Incremental Mean
这里提到了在实际操作时常用的一个实时更新均值的办法,使得在计算平均收获时不需要存储所有既往收获,而是每得到一次收获,就计算其平均收获。
理论公式如下:

这个公式比较简单。把这个方法应用于蒙特卡洛策略评估,就得到下面的蒙特卡洛累进更新。
蒙特卡洛累进更新
对于一系列Episodes中的每一个:
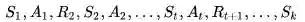
对于Episode里的每一个状态 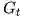
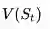
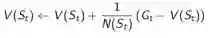
其中:
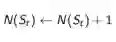
在处理非静态问题时,使用这个方法跟踪一个实时更新的平均值是非常有用的,可以扔掉那些已经计算过的Episode信息。此时可以引入参数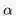
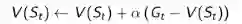
以上就是蒙特卡洛学习方法的主要思想和描述,由于蒙特卡洛学习方法有许多缺点(后文会细说),因此实际应用并不多。接下来介绍实际常用的TD学习方法。
时序差分学习 Temporal-Difference Learning
时序差分学习简称TD学习,它的特点如下:和蒙特卡洛学习一样,它也从Episode学习,不需要了解模型本身;但是它可以学习不完整的Episode,通过自身的引导(bootstrapping),猜测Episode的结果,同时持续更新这个猜测。
我们已经学过,在Monte-Carlo学习中,使用实际的收获(return)
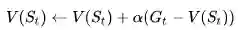
在TD学习中,算法在估计某一个状态的价值时,用的是离开该状态的即刻奖励
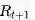
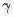
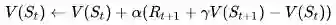
式中:
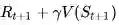
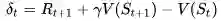
BootStrapping 指的就是TD目标值 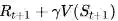
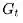
下面用一个例子直观解释蒙特卡洛策略评估和TD策略评估的差别。
示例——驾车返家
想象一下你下班后开车回家,需要预估整个行程花费的时间。假如一个人在驾车回家的路上突然碰到险情:对面迎来一辆车感觉要和你相撞,严重的话他可能面临死亡威胁,但是最后双方都采取了措施没有实际发生碰撞。如果使用蒙特卡洛学习,路上发生的这一险情可能引发的负向奖励不会被考虑进去,不会影响总的预测耗时;但是在TD学习时,碰到这样的险情,这个人会立即更新这个状态的价值,随后会发现这比之前的状态要糟糕,会立即考虑决策降低速度赢得时间,也就是说你不必像蒙特卡洛学习那样直到他死亡后才更新状态价值,那种情况下也无法更新状态价值。
TD算法相当于在整个返家的过程中(一个Episode),根据已经消耗的时间和预期还需要的时间来不断更新最终回家需要消耗的时间。
基于上表所示的数据,下图展示了蒙特卡洛学习和TD学习两种不同的学习策略来更新价值函数(各个状态的价值)。这里使用的是从某个状态预估的到家还需耗时来间接反映某状态的价值:某位置预估的到家时间越长,该位置价值越低,在优化决策时需要避免进入该状态。对于蒙特卡洛学习过程,驾驶员在路面上碰到各种情况时,他不会更新对于回家的预估时间,等他回到家得到了真实回家耗时后,他会重新估计在返家的路上着每一个主要节点状态到家的时间,在下一次返家的时候用新估计的时间来帮助决策;而对于TD学习,在一开始离开办公室的时候你可能会预估总耗时30分钟,但是当你取到车发现下雨的时候,你会立刻想到原来的预计过于乐观,因为既往的经验告诉你下雨会延长你的返家总时间,此时你会更新目前的状态价值估计,从原来的30分钟提高到40分钟。同样当你驾车离开高速公路时,会一路根据当前的状态(位置、路况等)对应的预估返家剩余时间,直到返回家门得到实际的返家总耗时。这一过程中,你会根据状态的变化实时更新该状态的价值。

通过这个例子,我们可以直观的了解到:
MC对比 TD之一
TD 在知道结果之前可以学习,MC必须等到最后结果才能学习;
TD 可以在没有结果时学习,可以在持续进行的环境里学习。
MC对比 TD之二
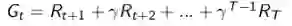
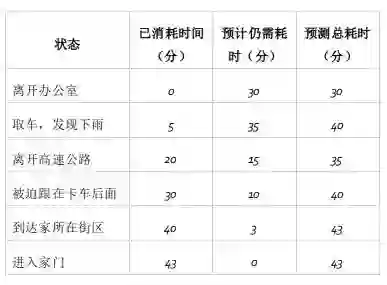
TD target:TD目标值,是基于下一状态预估价值计算的当前预估收获,是当前状态实际价值的有偏估计
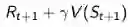
True TD target: 真实TD目标值,是基于下一状态的实际价值对当前状态实际价值的无偏估计
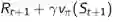
MC 没有偏倚(bias),但有着较高的变异性(Variance),且对初始值不敏感;
TD 低变异性variance, 但有一定程度的bias,对初始值较敏感,通常比 MC 更高效;
这里的偏倚指的是距离期望的距离,预估的平均值与实际平均值的偏离程度;变异性指的是方差,评估单次采样结果相对于与平均值变动的范围大小。基本就是统计学上均值与方差的概念。
对于MC和TD的区别,还可以用下面的例子来加深理解:
示例——随机行走
状态空间:如下图:A、B、C、D、E为中间状态,C同时作为起始状态。灰色方格表示终止状态;

行为空间:除终止状态外,任一状态可以选择向左、向右两个行为之一;
即时奖励:右侧的终止状态得到即时奖励为1,左侧终止状态得到的即时奖励为0,在其他状态间转化得到的即时奖励是0;
状态转移:100%按行为进行状态转移,进入终止状态即终止;
衰减系数:1;
给定的策略:随机选择向左、向右两个行为。
问题:对这个MDP问题进行预测,也就是评估随机行走这个策略的价值,也就是计算该策略下每个状态的价值,也就是确定该MDP问题的状态价值函数。
求解:下图是使用TD算法得到的结果。横坐标显示的是状态,纵坐标是各状态的价值估计,一共5条折线,数字表明的是实际经历的Episode数量,true value所指的那根折线反映的是各状态的实际价值。第0次时,各状态的价值被初始化为0.5,经过1次、10次、100次后得到的价值函数越来越接近实际状态价值函数。
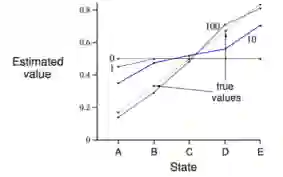
下图比较了MC和TD算法的效率。横坐标是经历的Episode数量,纵坐标是计算得到的状态函数和实际状态函数下各状态价值的均方差。黑色是MC算法在不同step-size下的学习曲线,灰色的曲线使用TD算法。可以看出TD较MC更高效。此图还可以看出当step-size不是非常小的情况下,TD有可能得不到最终的实际价值,将会在某一区间震荡。
示例——AB
已知:现有两个状态(A和B),MDP未知,衰减系数为1,有如下表所示8个完整Episode的经验及对应的即时奖励,其中除了第1个Episode有状态转移外,其余7个均只有一个状态。
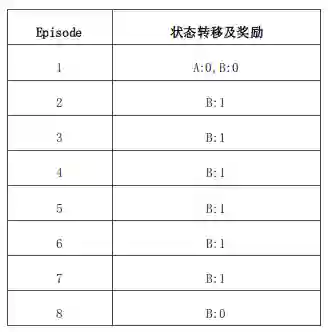
问题:依据仅有的Episode,计算状态A,B的价值分别是多少,即V(A)=?, V(B)=?
答案:V(B) = 6/8,V(A)根据不同算法结果不同,用MC算法结果为0,TD则得出6/8。
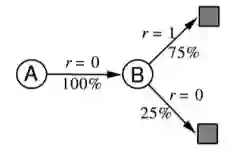
解释:应用MC算法,由于需要完整的Episode,因此仅Episode1可以用来计算A的状态价值,很明显是0;同时B的价值是6/8。应用TD算法时,TD算法试图利用现有的Episode经验构建一个MDP(如下图),由于存在一个Episode使得状态A有后继状态B,因此状态A的价值是通过状态B的价值来计算的,同时经验表明A到B的转移概率是100%,且A状态的即时奖励是0,并且没有衰减,因此A的状态价值等于B的状态价值。
MC算法试图收敛至一个能够最小化状态价值与实际收获的均方差的解决方案,这一均方差用公式表示为:

式中,k表示的是Episode序号, K为总的Episode数量,t为一个Episode内状态序号(第1,2,3...个状态等),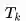
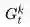
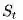
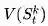
TD算法则收敛至一个根据已有经验构建的最大可能的马儿可夫模型的状态价值,也就是说TD算法将首先根据已有经验估计状态间的转移概率:
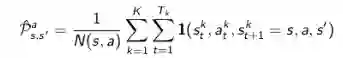
同时估计某一个状态的即时奖励:
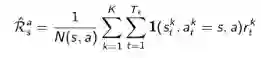
最后计算该MDP的状态函数。
MC对比 TD之三
通过比较可以看出,TD算法使用了MDP问题的马儿可夫属性,在Markov 环境下更有效;但是MC算法并不利用马儿可夫属性,通常在非Markov环境下更有效。
小结——三种强化学习算法
Monte-Carlo, Temporal-Difference 和 Dynamic Programming 都是计算状态价值的一种方法,区别在于,前两种是在不知道Model的情况下的常用方法,这其中又以MC方法需要一个完整的Episode来更新状态价值,TD则不需要完整的Episode;DP方法则是基于Model(知道模型的运作方式)的计算状态价值的方法,它通过计算一个状态S所有可能的转移状态S’及其转移概率以及对应的即时奖励来计算这个状态S的价值。
关于是否Bootstrap:MC 没有引导数据,只使用实际收获;DP和TD都有引导数据。
关于是否用样本来计算: MC和TD都是应用样本来估计实际的价值函数;而DP则是利用模型直接计算得到实际价值函数,没有样本或采样之说。
下面的几张图直观地体现了三种算法的区别:
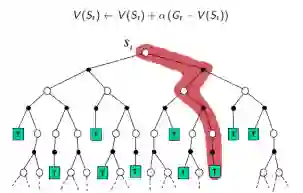
MC: 采样,一次完整经历,用实际收获更新状态预估价值
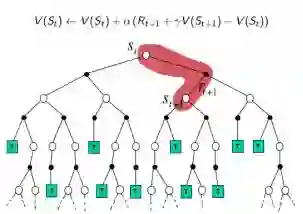
TD:采样,经历可不完整,用喜爱状态的预估状态价值预估收获再更新预估价值
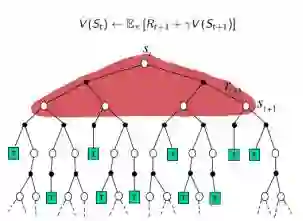
DP:没有采样,根据完整模型,依靠预估数据更新状态价值
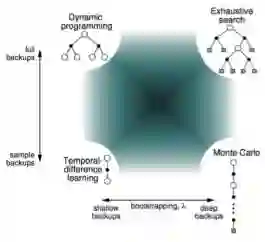
上图从两个维度解释了四种算法的差别,多了一个穷举法。这两个维度分别是:采样深度和广度。当使用单个采样,同时不走完整个Episode就是TD;当使用单个采样但走完整个Episode就是MC;当考虑全部样本可能性,但对每一个样本并不走完整个Episode时,就是DP;当既考虑所有Episode又把Episode从开始到终止遍历完,就变成了穷举法。
需要提及的是:DP利用的是整个MDP问题的模型,也就是状态转移概率,虽然它并不实际利用样本,但是它利用了整个模型的规律,因此认为是Full Width的。
TD(λ)
先前所介绍的TD算法实际上都是TD(0)算法,括号内的数字0表示的是在当前状态下往前多看1步,要是往前多看2步更新状态价值会怎样?这就引入了n-step的概念。
n-步预测 n-Step Prediction
在当前状态往前行动n步,计算n步的return,同样TD target 也由2部分组成,已走的步数使用确定的即时reward,剩下的使用估计的状态价值替代。
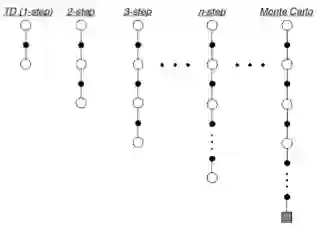
注:图中空心大圆圈表示状态,实心小圆圈表示行为
n-步收获
TD或TD(0)是基于1-步预测的,MC则是基于∞-步预测的:

注意:n=2时不写成TD(2)。
定义n-步收获:

那么,n步TD学习状态价值函数的更新公式为:
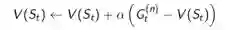
既然存在n-步预测,那么n=?时效果最好呢,下面的例子试图回答这个问题:
示例——大规模随机行走
这个示例研究了使用多个不同步数预测联合不同步长(step-size,公式里的系数α)时,分别在在线和离线状态时状态函数均方差的差别。所有研究使用了10个Episode。离线与在线的区别在于,离线是在经历所有10个Episode后进行状态价值更新;而在线则至多经历一个Episode就更新依次状态价值。
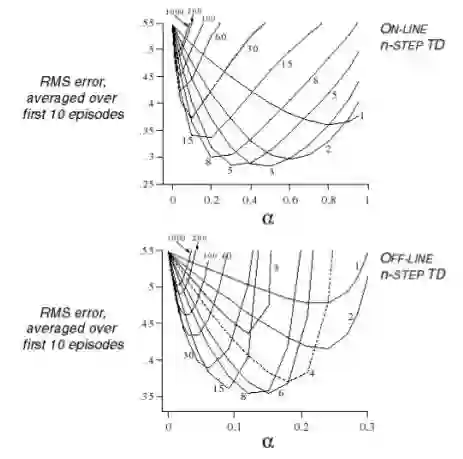
结果如图表明,离线和在线之间曲线的形态差别不明显;从步数上来看,步数越长,越接近MC算法,均方差越大。对于这个大规模随机行走示例,在线计算比较好的步数是3-5步,离线计算比较好的是6-8步。但是不同的问题其对应的比较高效的步数不是一成不变的。因此选择多少步数作为一个较优的计算参数也是一个问题。
这里我们引入了一个新的参数:λ。通过引入这个新的参数,可以做到在不增加计算复杂度的情况下综合考虑所有步数的预测。这就是λ预测和λ收获。
λ-收获
λ-收获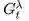
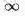
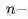
步收获施加一定的权重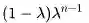
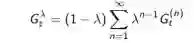
对应的λ-预测写成TD(λ):
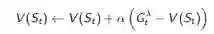
下图是各步收获的权重分配图,图中最后一列λ的指数是T - t - 1。T 为终止状态的时刻步数, t为当前状态的时刻步数,所有的权重加起来为1。
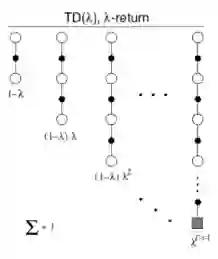
TD(λ)对于权重分配的图解
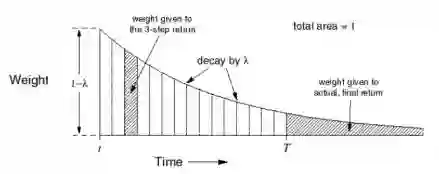
这张图还是比较好理解,例如对于n=3的3-步收获,赋予其在 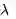
TD((λ)的设计使得Episode中,后一个状态的状态价值与之前所有状态的状态价值有关,同时也可以说成是一个状态价值参与决定了后续所有状态的状态价值。但是每个状态的价值对于后续状态价值的影响权重是不同的。我们可以从两个方向来理解TD(λ):
前向认识TD(λ)
引入了λ之后,会发现要更新一个状态的状态价值,必须要走完整个Episode获得每一个状态的即时奖励以及最终状态获得的即时奖励。这和MC算法的要求一样,因此TD(λ)算法有着和MC方法一样的劣势。λ取值区间为[0,1],当λ=1时对应的就是MC算法。这个实际计算带来了不便。
反向认识TD(λ)
TD(λ)从另一方面提供了一个单步更新的机制,通过下面的示例来说明。
示例——被电击的原因
这是之前见过的一个例子,老鼠在连续接受了3次响铃和1次亮灯信号后遭到了电击,那么在分析遭电击的原因时,到底是响铃的因素较重要还是亮灯的因素更重要呢?

两个概念:
频率启发 Frequency heuristic:将原因归因于出现频率最高的状态
就近启发 Recency heuristic:将原因归因于较近的几次状态
给每一个状态引入一个数值:效用追踪(Eligibility Traces, ES,也有翻译成“资质追踪”,这是同一个概念从两个不同的角度理解得到的不同翻译),可以结合上述两个启发。定义:
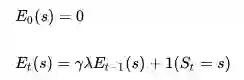
其中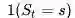
下图给出了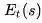

该图横坐标是时间,横坐标下有竖线的位置代表当前进入了状态 s,纵坐标是效用追踪值E 。可以看出当某一状态连续出现,E值会在一定衰减的基础上有一个单位数值的提高,此时将增加该状态对于最终收获贡献的比重,因而在更新该状态价值的时候可以较多地考虑最终收获的影响。同时如果该状态距离最终状态较远,则其对最终收获的贡献越小,在更新该状态时也不需要太多的考虑最终收获。
特别的,E值并不需要等到完整的Episode结束才能计算出来,它可以每经过一个时刻就得到更新。E值存在饱和现象,有一个瞬时最高上限:
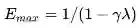
把刚才的描述体现在公式里更新状态价值,是这样的:
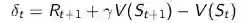
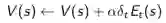
注:每一个状态都有一个E值, E值随时间而变化。
当λ=0时,只有当前状态得到更新,等同于TD(0)算法;
当λ=1时,TD(1)粗略看与每次访问的MC算法等同;在线更新时,状态价值差每一步都会有积累;离线更新时,TD(1)等同于MC算法。
注:ET是一个非常符合神经科学相关理论的、非常精巧的设计。把它看成是神经元的一个参数,它反映了神经元对某一刺激的敏感性和适应性。神经元在接受刺激时会有反馈,在持续刺激时反馈一般也比较强,当间歇一段时间不刺激时,神经元又逐渐趋于静息状态;同时不论如何增加刺激的频率,神经元有一个最大饱和反馈。
小结
下表给出了λ取各种值时,不同算法在不同情况下的关系。

相较于MC算法,TD算法应用更广,是一个非常有用的强化学习方法,在下一讲讲解控制相关的算法时会详细介绍TD算法的实现。
敬请关注专知公众号(扫一扫最下方二维码或者最上方专知蓝字关注),以及专知网站www.zhuanzhi.ai, 第一时间得到的《强化学习》第五讲 不基于模型的控制!
作者简介:
叶强,眼科专家,上海交通大学医学博士, 工学学士,现从事医学+AI相关的研究工作。
特注:
请登录www.zhuanzhi.ai或者点击阅读原文,
顶端搜索“强化学习” 主题,直接获取查看获得全网收录资源进行查看, 涵盖论文等资源下载链接,并获取更多与强化学习的知识资料!如下图所示。
此外,请关注专知公众号(扫一扫最下面专知二维码,或者点击上方蓝色专知),后台回复“强化学习” 就可以获取深度强化学习知识资料全集(论文/代码/教程/视频/文章等)的pdf文档!
欢迎转发到你的微信群和朋友圈,分享专业AI知识!
请感兴趣的同学,扫一扫下面群二维码,加入到专知-深度强化学习交流群!

请扫描小助手,加入专知人工智能群,交流分享~

获取更多关于机器学习以及人工智能知识资料,请访问www.zhuanzhi.ai, 或者点击阅读原文,即可得到!
-END-
欢迎使用专知
专知,一个新的认知方式!目前聚焦在人工智能领域为AI从业者提供专业可信的知识分发服务, 包括主题定制、主题链路、搜索发现等服务,帮你又好又快找到所需知识。
使用方法>>访问www.zhuanzhi.ai, 或点击文章下方“阅读原文”即可访问专知
中国科学院自动化研究所专知团队
@2017 专知
专 · 知
关注我们的公众号,获取最新关于专知以及人工智能的资讯、技术、算法、深度干货等内容。扫一扫下方关注我们的微信公众号。


点击“阅读原文”,使用专知!


