

今天给大家分享的内容来自我们模式识别中心在EMNLP2018发表的一篇论文《NEXUS Network: Connecting the Preceding and the Following inDialogue Generation》。
EMNLP2018 | 一个承上启下的回答才是好的回答
#名字真的不是在故意碰瓷G家的手机 #
言归正传,下面介绍一下我们做这篇工作的一些心路历程。目前基于生成模型的闲聊对话已经成为学术圈和工业界的主流,但是效果却不尽如人意。一个常见的现象是模型会生成类似“哦”、“好的”这样长度短且无意义的回答,容易让进行中的对话戛然而止。(假如我的朋友总是回我一个哦,我真想立马关了他的聊天框)。那么我们不禁思考,到底什么的回答才容易让对话顺利继续下去呢?
不妨一起来看看真实语料里的一组对话:

我们看到,B说的话可以分为两个部分,首先回答了是否知道《星球大战》这部电影(承接上文),其次告诉A可以给自己多介绍一下电影(引出下文)。这不失为一个好的回答。
从这个角度出发,我们在对话模型中引入互信息(MMI)显式建模这种承上启下的关系。在概率论和信息论中,互信息可以衡量两个变量相互依赖的程度。一个合理的假设是:如果我们可以同时增大回答(B1)和上文(A1)以及回答(B1)和下文(A2)的互信息,这个回答就能兼顾到上文和下文。这里和Google最新的BERT模型有异曲同工之处,利用左边和右边的context一起建模当前的representation。
令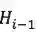
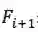
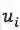
有了目标函数,但是想要训练却存在两个难点:1)通常的思路是需要先sample出回答再去最大化互信息,然后通过反向传播提高下一次sample出回答的质量,但是文本离散的特点严重阻碍了梯度的传导。2)在训练阶段是可以利用下文的信息,但是测试阶段是没有的,也就是说模型的训练和测试不一致会让测试无法进行。
为了解决这两个难点,我们引入额外的连续code space 来代替原本需要被sample出来的(离散的)回答。在训练的过程中,我们最大化这个code和上文以及下文的互信息,让梯度顺利传导,同时引入一个可学习的先验(prior distribution)在测试阶段sample回答。
整个模型的结构如下图:
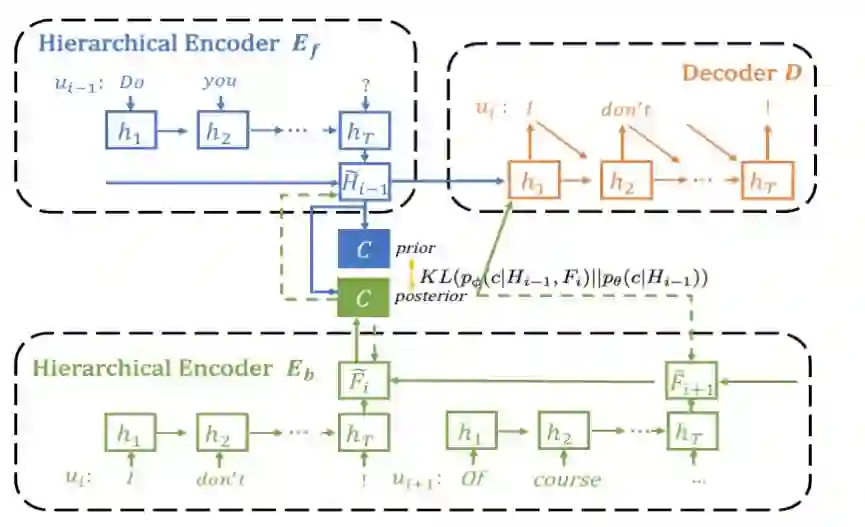
为了让引入code c后仍然保持目标函数等价,我们从最大化两个互信息变成最大化三个互信息,换句话说如果c和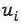
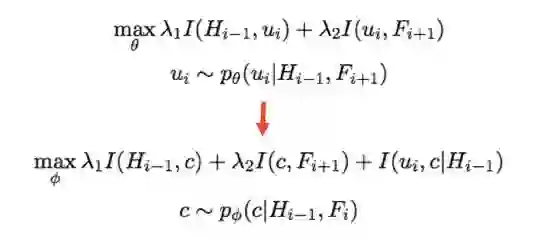
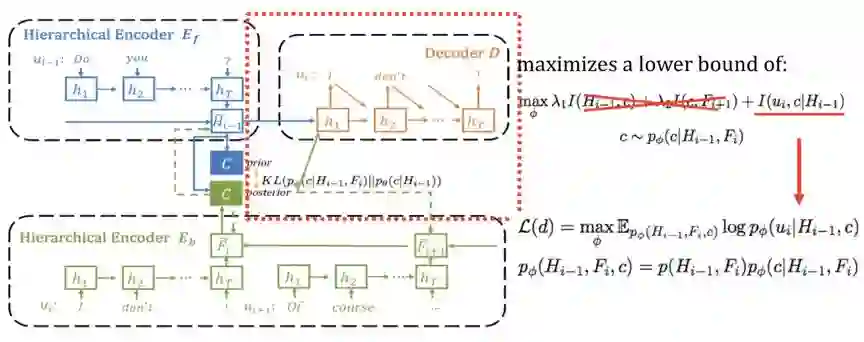
我们首先关注损失函数的前两项,对应图中的红框部分,让 code c和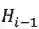
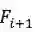
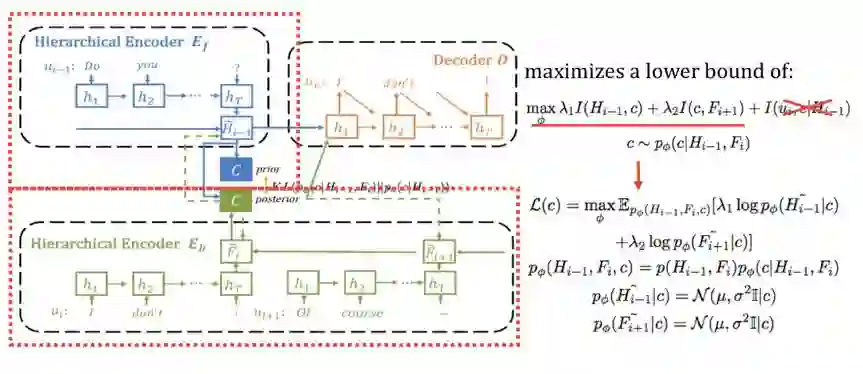
接着是最大化code c 和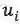
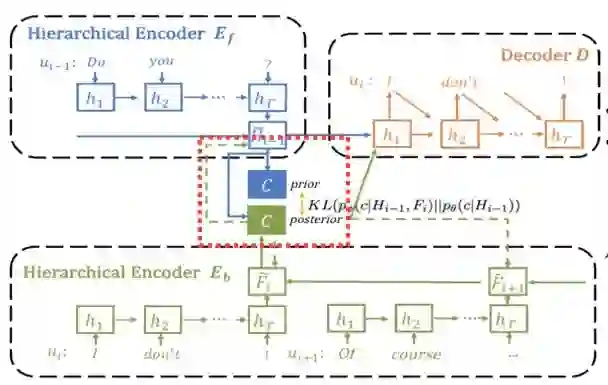
最后,我们需要一个可学习的先验,且先验在学习时只依赖上文,这样当在测试阶段我们无法使用下文时,依然只使用上文即可。这一步通过在训练时最小化先验和后验的KL距离来实现。
到这里模型的部分就结束了。对于生成的结果,我们首先采用基于BLEU和embedding等传统的指标来评测,发现结果均比之前的模型有较大提高。除此之外,我们也利用判别器的思想训练了新的模型AdverSuc来衡量回答的coherence 程度(反应是否承接上文),并进一步测试基于当前的回复得到最大的对话轮数(反应是否易于回答启发下文)。在这两个指标上也领先不少。
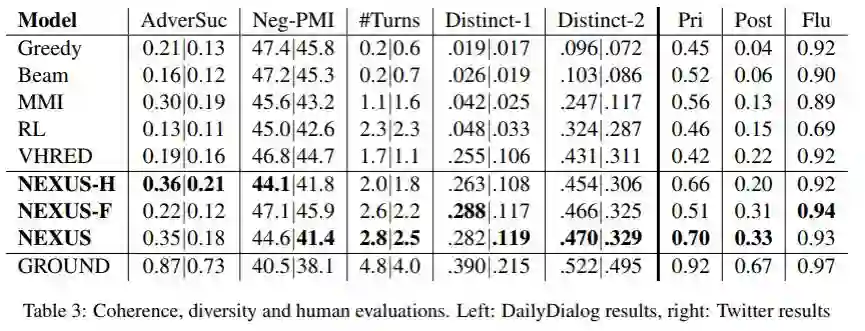
我们进一步分析了NEXUS模型和CVAE、RL等模型在dialog应用上的联系和区别。从生成的回答里也发现了模型的一些缺点,回答经常是陈述句接上疑问句的模式。我们分析是因为模型也发现了疑问句更容易让对话进行下去的规律,但会有点“矫枉过正”,也就是说会容易坍塌到陷入喜欢使用疑问句的情况,后面的工作会进一步分析。
我们已经先把论文放到了arxiv,https://arxiv.org/pdf/1810.00671.pdf,代码也正在整理中,欢迎多多交流~

 微信ID:WeChatAI
微信ID:WeChatAI
 长按左侧二维码关注
长按左侧二维码关注
登录查看更多
相关内容

Arxiv
3+阅读 · 2018年3月26日





相关VIP内容
相关资讯
相关论文
Arxiv
3+阅读 · 2018年3月26日