揭开知识库问答KB-QA的面纱1·简介篇
作者丨刘大一恒
学校丨四川大学博士生
1. 什么是知识库?
“奥巴马出生在火奴鲁鲁。”
“姚明是中国人。”
“谢霆锋的爸爸是谢贤。”
这些就是一条条知识,而把大量的知识汇聚起来就成为了知识库。我们可以在 wiki 百科,百度百科等百科全书查阅到大量的知识。然而,这些百科全书的知识组建形式是非结构化的自然语言,这样的组织方式很适合人们阅读但并不适合计算机去处理。为了方便计算机的处理和理解,我们需要更加形式化、简洁化的方式去表示知识,那就是三元组(triple)。
“奥巴马出生在火奴鲁鲁。” 可以用三元组表示为(BarackObama, PlaceOfBirth, Honolulu)。
这里我们可以简单的把三元组理解为(实体 entity,实体关系 relation,实体entity),进一步的,如果我们把实体看作是结点,把实体关系(包括属性,类别等等)看作是一条边,那么包含了大量三元组的知识库就成为了一个庞大的知识图。
知识库可以分为两种类型,一种是以 Freebase,Yago2 为代表的 Curated KBs,它们从维基百科和 WordNet 等知识库中抽取大量的实体及实体关系,可以把它们理解为是一种结构化的维基百科,被 Google 收购的 Freebase 中包含了上千万个实体,共计 19 亿条 triple。
值得一提的是,有时候会把一些实体称为 topic,如 Justin Bieber。实体关系也可分为两种,一种是属性 property,一种是关系 relation。如下图所示,属性和关系的最大区别在于,属性所在的三元组对应的两个实体,常常是一个 topic 和一个字符串,如属性 Type/Gender,对应的三元组(Justin Bieber, Type, Person),而关系所在的三元组所对应的两个实体,常常是两个 topic。如关系 Place_of_Brith,对应的三元组(Justin Bieber, Place_of_brith, London)。
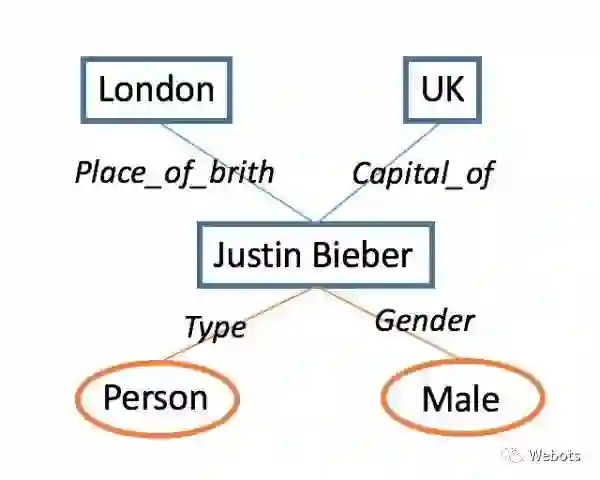
图中蓝色方块表示 topic,橙色椭圆包括属性值,它们都属于知识库的实体,蓝色直线表示关系,橙色直线表示属性,它们都统称为知识库的实体关系,都可以用三元组刻画实体关系和实体。
但是,像维基百科这样的知识库,与整个互联网相比,仍只能算沧海一粟。知识库的另外一种类型,则是以 Open Information Extraction (Open IE), Never-Ending Language Learning (NELL) 为代表的 Extracted KBs,它们直接从上亿个网页中抽取实体关系三元组。与 Freebase 相比,这样得到的知识更加具有多样性,而它们的实体关系和实体更多的则是自然语言的形式,如“奥巴马出生在火奴鲁鲁。” 可以被表示为(“Obama”, “was also born in”, “ Honolulu”),当然,直接从网页中抽取出来的知识,也会存在一定的 noisy,其精确度要低于 Curated KBs。
Extracted KBs 知识库涉及到的两大关键技术是:
实体链指(Entity linking)
即将文档中的实体名字链接到知识库中特定的实体上。它主要涉及自然语言处理领域的两个经典问题实体识(Entity Recognition)与实体消歧(Entity Disambiguation),简单地来说,就是要从文档中识别出人名、地名、机构名、电影等命名实体。并且,在不同环境下同一实体名称可能存在歧义,如苹果,我们需要根据上下文环境进行消歧。
关系抽取 (Relation extraction)
即将文档中的实体关系抽取出来,主要涉及到的技术有词性标注(Part-of-Speech tagging, POS),语法分析,依存关系树(dependency tree)以及构建 SVM、最大熵模型等分类器进行关系分类等。
2. 什么是知识库问答
知识库问答(knowledge base question answering, KB-QA)即给定自然语言问题,通过对问题进行语义理解和解析,进而利用知识库进行查询、推理得出答案。如下图所示:
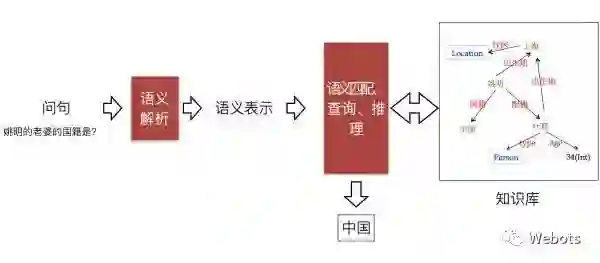
注:该图片来自中科院刘康老师在知识图谱与问答系统前沿技术研讨会中的报告
与对话系统、对话机器人的交互式对话不同,KB-QA 具有以下特点:
1. 答案:回答的答案是知识库中的实体或实体关系,或者 no-answer(即该问题在 KB 中找不到答案),当然这里答案不一定唯一,比如中国的城市有哪些 。而对话系统则回复的是自然语言句子,有时甚至需要考虑上下文语境。
2. 评价标准:回召率(Recall),精确率(Precision)),F1-Score。而对话系统的评价标准以人工评价为主,以及 BLEU 和 Perplexity。
当我们在百度询问 2016 年奥斯卡最佳男主角时,百度会根据知识库进行查询和推理,返回答案,这其实就是 KB-QA 的一个应用。
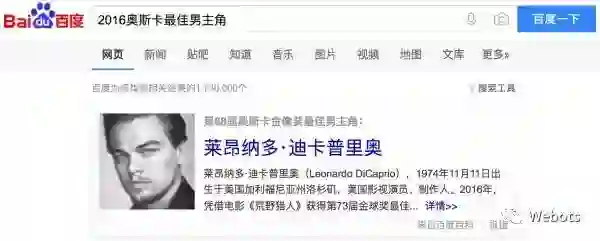
注:该图片来自百度搜索
3. 知识库问答的主流方法
关于 KB-QA 的方法,个人认为,传统的主流方法可以分为三类:
语义解析(Semantic Parsing):该方法是一种偏linguistic的方法,主体思想是将自然语言转化为一系列形式化的逻辑形式(logic form),通过对逻辑形式进行自底向上的解析,得到一种可以表达整个问题语义的逻辑形式,通过相应的查询语句(类似 lambda-Caculus)在知识库中进行查询,从而得出答案。下图红色部分即逻辑形式,绿色部分 where was Obama born 为自然语言问题,蓝色部分为语义解析进行的相关操作,而形成的语义解析树的根节点则是最终的语义解析结果,可以通过查询语句直接在知识库中查询最终答案。
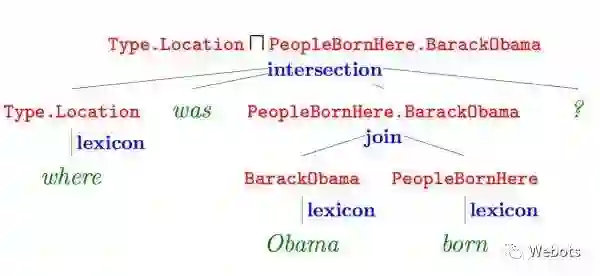
注:该图片来自 Semantic Parsing on Freebase from Question-Answer Pairs
这里给出语义解析方法的一些代表论文:
Berant J, Chou A, Frostig R, et al. Semantic Parsing on Freebase from Question-Answer Pairs[C]//EMNLP. 2013, 2(5): 6.
Cai Q, Yates A. Large-scale Semantic Parsing via Schema Matching and Lexicon Extension[C]//ACL (1). 2013: 423-433.
Kwiatkowski T, Choi E, Artzi Y, et al. Scaling semantic parsers with on-the-fly ontology matching[C]//In Proceedings of EMNLP. Percy. 2013.
Fader A, Zettlemoyer L, Etzioni O. Open question answering over curated and extracted knowledge bases[C]//Proceedings of the 20th ACM SIGKDD international conference on Knowledge discovery and data mining. ACM, 2014: 1156-1165.
信息抽取(Information Extraction):该类方法通过提取问题中的实体,通过在知识库中查询该实体可以得到以该实体节点为中心的知识库子图,子图中的每一个节点或边都可以作为候选答案,通过观察问题依据某些规则或模板进行信息抽取,得到问题特征向量,建立分类器通过输入问题特征向量对候选答案进行筛选,从而得出最终答案。信息抽取的代表论文 Yao X, Van Durme B. Information Extraction over Structured Data: Question Answering with Freebase[C]//ACL (1). 2014: 956-966。
向量建模(Vector Modeling):该方法思想和信息抽取的思想比较接近,根据问题得出候选答案,把问题和候选答案都映射为分布式表达(Distributed Embedding),通过训练数据对该分布式表达进行训练,使得问题和正确答案的向量表达的得分(通常以点乘为形式)尽量高,如下图所示。模型训练完成后则可根据候选答案的向量表达和问题表达的得分进行筛选,得出最终答案。
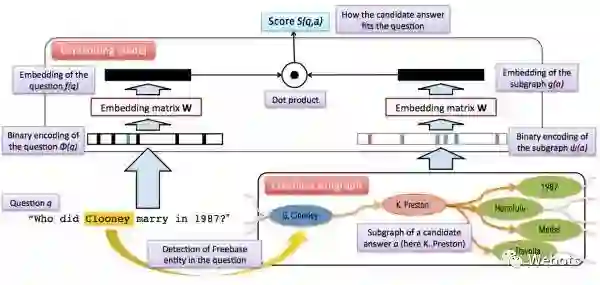
注:该图片来自论文 Question answering with subgraph embeddings
向量建模方法的代表论文:
Bordes A, Chopra S, Weston J. Question answering with subgraph embeddings[J]. arXiv preprint arXiv:1406.3676, 2014.
Yang M C, Duan N, Zhou M, et al. Joint Relational Embeddings for Knowledge-based Question Answering[C]//EMNLP. 2014, 14: 645-650.
Bordes A, Weston J, Usunier N. Open question answering with weakly supervised embedding models[C]//Joint European Conference on Machine Learning and Knowledge Discovery in Databases. Springer Berlin Heidelberg, 2014: 165-180.
细心的朋友已经发现了,以上三种方法的代表论文都集中在13-14年。那么 14 年之后 KB-QA 的主流方法是什么呢?
随着深度学习(Deep Learning)在自然语言处理领域的飞速发展,从 15 年开始,开始涌现出一系列基于深度学习的 KB-QA 文章,通过深度学习对传统的方法进行提升,取得了较好的效果,比如:
使用卷积神经网络对向量建模方法进行提升:
Dong L, Wei F, Zhou M, et al. Question Answering over Freebase with Multi-Column Convolutional Neural Networks[C]//ACL (1). 2015: 260-269.
使用卷积神经网络对语义解析方法进行提升:
Yih S W, Chang M W, He X, et al. Semantic parsing via staged query graph generation: Question answering with knowledge base[J]. 2015.
注:该 paper 来自微软,是 ACL 2015 年的 Outstanding paper,也是目前 KB-QA 效果最好的 paper 之一。
使用长短时记忆网络(Long Short-Term Memory,LSTM),卷积神经网络(Convolutional Neural Networks,CNNs)进行实体关系分类:
Xu Y, Mou L, Li G, et al. Classifying Relations via Long Short Term Memory Networks along Shortest Dependency Paths[C]//EMNLP. 2015: 1785-1794.
Zeng D, Liu K, Lai S, et al. Relation Classification via Convolutional Deep Neural Network[C]//COLING. 2014: 2335-2344.(Best paper)
Zeng D, Liu K, Chen Y, et al. Distant Supervision for Relation Extraction via Piecewise Convolutional Neural Networks[C]//EMNLP. 2015: 1753-1762.
使用记忆网络(Memory Networks),注意力机制(Attention Mechanism)进行 KB-QA:
Bordes A, Usunier N, Chopra S, et al. Large-scale simple question answering with memory networks[J]. arXiv preprint arXiv:1506.02075, 2015.
Zhang Y, Liu K, He S, et al. Question Answering over Knowledge Base with Neural Attention Combining Global Knowledge Information[J]. arXiv preprint arXiv:1606.00979, 2016.
以上论文几乎都使用了 Freebase 作为 knowledge base,并且在 WebQuestion 数据集上进行过测试,这里给出各种方法的效果对比图,给大家一个更加直观的感受。
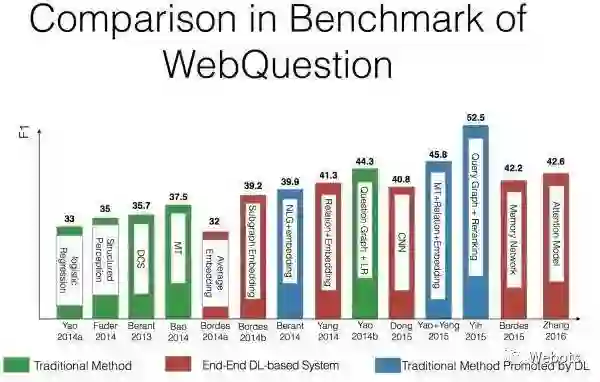
注:该图片来自中科院刘康老师在知识图谱与问答系统前沿技术研讨会中的报告
以上论文几乎都使用了 Freebase 作为 knowledge base,并且在 WebQuestion 数据集上进行过测试,这里给出各种方法的效果对比图,给大家一个更加直观的感受。
4. 知识库问答的数据集
最后,我们再简单地介绍一下 KB-QA 问题的 Benchmark 数据集——WebQuestion。
该数据集由 Berant J, Chou A, Frostig R, et al.在 13 年的论文 Semantic Parsing on Freebase from Question-Answer Pairs 中公开。
作者首先使用 Google Suggest API 获取以 wh-word(what,who,why,where,whose...)为开头且只包含一个实体的问题,以“where was Barack Obama born?”作为问题图谱的起始节点,以 Google Suggest API 给出的建议作为新的问题,通过宽度优先搜索获取问题。具体来讲,对于每一个队列中的问题,通过对它删去实体,删去实体之前的短语,删去实体之后的短语形成 3 个新的 query,将这三个新 query 放到 google suggest 中,每个 query 将生成 5 个候选问题,加入搜索队列,直到 1M 个问题被访问完。如下图所示:
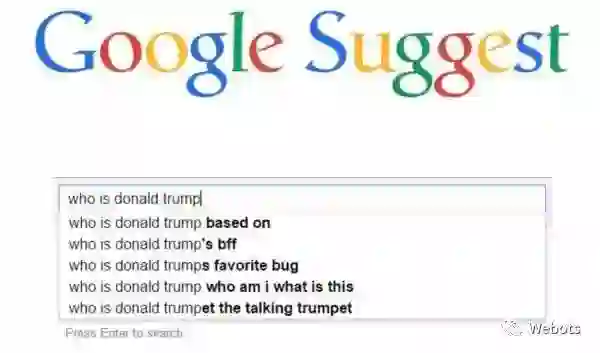
注:该图片来自Google Suggest
获取完问题后,随机选取 100K 个问题交给 Amazon Mechanical Turk (AMT) 的工人,让工人回答答案。注意,这里对答案进行了限制,让 AMT 的工人只能把答案设置为 Freebase 上的实体(entity),实体列表,值(value)或者 no-answer。
最终,得到了 5,810 组问题答案对,其词汇表包含了 4,525 个词。并且,WebQuestion 还提供了每个答案对应知识库的主题节点(topic node)。
可以看出 WebQuestion 的问题与 freebase 是不相关的,更加偏向自然语言,也更多样化。这里给出一些例子:
“What is James Madison most famous for?”
“What movies does Taylor Lautner play in?”
“What music did Beethoven compose?”
“What kind of system of government does the United States have?”
除了该数据集,这里再补充一些其他数据集的信息,如下图所示:
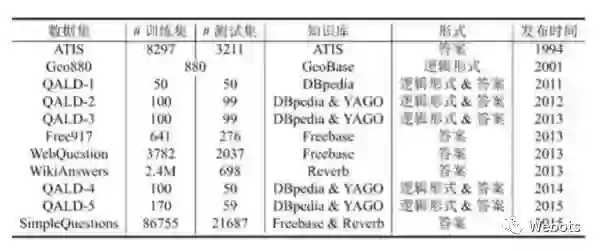
注:该图片来自中科院刘康老师在知识图谱与问答系统前沿技术研讨会中的报告
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。




