何恺明等研究者:真的需要减少ImageNet预训练吗?
选自arXiv
作者:Kaiming He、Ross Girshick、Piotr Dollar
机器之心编辑部
我们真的需要减少使用 ImageNet 预训练模型了吗?在检测和分割任务上,何恺明等研究者最近「Rethink」了一下 ImageNet 预训练模型。如果你的数据和计算力足够多,那么 ImageNet 预训练只能加快收敛而不提升准确率;如果数据太少,那么还是老老实实使用预训练模型吧。
ImageNet 图像预训练在各种视觉任务中一直都极为常见,我们会假定预训练模型的前面层级能抽取到足够的一般图像信息。因此保留预训练模型前面层级的权重就相当于迁移了一般的图像知识,并可以用于各种下游任务。但是在 ImageNet 上的预训练模型通过千类图像识别任务也只能学习到近似的一般图像知识。所以离千类图像识别任务越近,下游任务迁移的知识就越多。如果离千类图像识别任务非常远,说不定预训练也就起个初始化的作用。
不过近来很多视觉任务都会使用 ImageNet 预训练模型,因为这种方法简单方便啊。我们可以从各种模型库中下载各式各样的预训练卷积网络及权重,把它们作为整体模型的某个组件后就可以重训练部分权重了,这样至少比随机初始化好吧。在何恺明等研究者的这篇「Rethink」论文中,他主要关注预训练模型在目标检测与图像分割等应用下的性能,这种位置敏感型的任务和千类图像识别任务还是有一些差别的。
为此,何恺明等研究者表示这种利用预训练模型抽取「通用」特征,并借此解决大多数视觉任务的方法是值得质疑的。因为即使在比 ImageNet 还大 3000 倍的数据集上进行预训练,它们对目标检测任务的性能提升仍然不是很大。
这篇论文通过探索随机初始化进一步质疑了预训练的范式,他们表示当随机初始化的模型在 COCO 数据集上进行训练,它不需要任何预训练也能在目标检测和实例分割上获得最好的性能。更令人惊奇的是,在从头训练的条件下,他们可以使用基线系统和专门为预训练模型优化过的超参数实现相近的性能。
这篇论文主要表示 COCO 数据集(目标检测与实例分割)上的随机初始化模型最后可以获得很好的性能,且能与基于 ImageNet 预训练的模型相媲美。此外,研究者发现即使在训练数据只有 COCO 的 10%,预训练获得的准确率都与从头训练差距不大。最后研究者主要得出以下发现:
ImageNet 预训练可以加速收敛,特别是在训练前期。但如果加上事先预训练和微调的时间,两者差不多。
ImageNet 预训练并不会自动给出更好的正则化,在小数据集上还是需要微调超参数。
当下游任务是空间位置敏感的定位预测,ImageNet 预训练并不会获得显著的优势。因此,基于分类任务的 ImageNet-like 预训练方式,与位置敏感型目标任务之间的存在显著差异,这可能会限制预训练模型的优势。
当然,已经有很多研究者在关注检测与分割任务不能利用 ImageNet 预训练的优势,例如缓解图像分类与目标检测任务之间差距的 DetNet。我们在使用 ImageNet 预训练模型之前应该先要考虑下游任务与分类之间的差异,也许「Rethink」的意义在于不要盲从任何范式,说不定以后会出现更接近于目标检测或实例分割下游任务的预训练方法。
这篇论文在知乎也有非常广泛的讨论,感兴趣的读者可以查看不同开发者的观点:
知乎问答地址:https://www.zhihu.com/question/303234604
论文:Rethinking ImageNet Pre-training

论文地址:https://arxiv.org/pdf/1811.08883.pdf
摘要:我们使用从随机初始化开始训练的标准模型在 COCO 数据集上取得了目标检测和实例分割的有力结果。这些结果可以媲美那些在 ImageNet 上进行预训练的模型的结果,即使使用为微调预训练模型而优化的基线系统(Mask R-CNN)的超参数也是如此,唯一的例外是增加训练迭代次数,以便随机初始化的模型可以收敛。从随机初始化开始训练的模型的鲁棒性出人意料;我们的结果在以下情况下得以保持:(i)仅用 10% 的训练数据;(2)针对较深、较广泛的模型;(3)用于多个任务及矩阵。实验表明,ImageNet 预训练可以在训练早期加速收敛,但未必会提供正则化或提高最终目标任务的准确率。为挑战极限,我们在 COCO 目标检测数据集上在不使用任何外部数据的前提下得到了 50.9 AP,该结果可以媲美 COCO 2017 挑战赛冠军使用 ImageNet 预训练得到的结果。这些观察挑战了独立任务中关于 ImageNet 预训练的常识,我们希望这些发现可以激励大家重新思考计算机视觉中预训练和微调的当下实际范式。
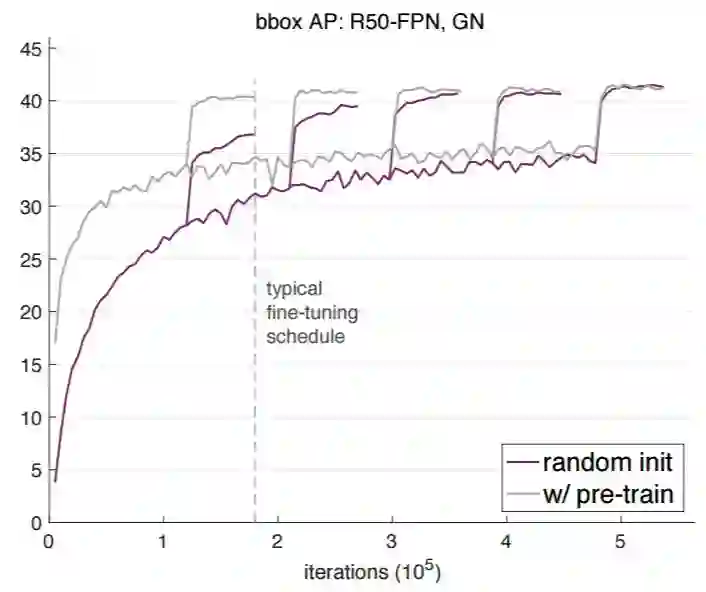
图 1:我们在 COCO train2017 设定中利用 ResNet-50 FPN [26]+GN [48] 骨干网络训练 Mask R-CNN [13],在 val2017 设定中评估边界框 AP(bbox AP),通过随机权重或 ImageNet 预训练来初始化模型。我们通过改变迭代次数来探索不同的训练计划,临近迭代次数上的学习率会降低(准确率跃升)。从随机初始化开始训练的模型需要更多的迭代才能收敛,但会收敛到不亚于微调方案的性能。表 1 显示了具体的 AP 值。
方法
归一化
为了更好地理解 ImageNet 预训练会产生什么影响,我们希望能够在架构修改最少的情况下从头开始训练典型架构。我们描述了仅有的两个认为必要的修改,与模型归一化和训练长度有关,将在下一步讨论。
批量归一化(BN)[20] 是用来训练现代网络的常用归一化方法,但它也是让从零开始训练检测器变得困难的部分原因。与图像分类器不同,目标检测器通常用高分辨率输入来训练。这样做减少了受内存限制的批大小,而小批量严重降低了 BN[19, 34, 48] 的准确率。如果使用预训练,这个问题可以避免,因为微调可以采用预训练批量统计作为固定参数 [17];但是,在从头开始训练时固定 BN 是无效的。
我们探索了最近的研究提出的两种归一化策略,其有利于解决小批量问题:
群组归一化(GN)[48]:GN 是最近提出的 BN 的一种替代,执行独立于批维度的计算,其准确率对批大小不敏感 [48]。
同步批归一化(SyncBN)[34, 27]:BN 的一种实现 [20],批量统计在多个设备(GPU)上进行计算。使用多个 GPU 时,这样可以提高用于 BN 的有效批大小,从而避免小批量。
我们的实验表明,GN 和 SyncBN 都允许检测模型从头开始训练。
收敛
典型的 ImageNet 预训练涉及超过一百万张图像并迭代上百个 epoch。除了从这个大规模数据集中学习到的语义信息以外,预训练模型还学习到了在微调过程中不需要再学习的低级特征(例如,边缘、纹理等)。另一方面,从零开始训练模型时需要同时学习低级和高级特征,因此需要更多的迭代次数才能收敛。
基于此,我们认为从零开始训练模型必然比典型的微调方案需要更长的训练时间。这可以从模型在训练过程中见过的样本数量进行公平比较,如图 2 所示。
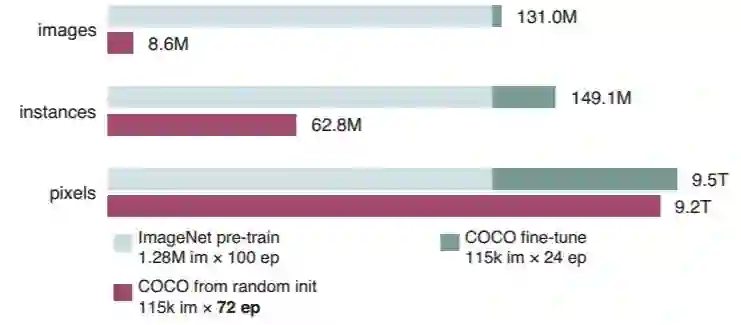
图 2:在所有训练迭代中模型所见到的图像、实例和像素数量,预训练(灰色)+微调(绿色)vs 随机初始化(紫色)。其中,紫色条带普遍比绿色条带更长,意味着需要更大的迭代次数才能收敛。
结果与分析
我们第一个惊奇的发现是,当仅使用 COCO 数据集时,从零开始训练的模型可以达到和微调模型相当的准确率。
图 1 和图 3 展示了当在 ResNet-50 (R50) 和 ResNet-101 (R101) 网络骨干上使用 GN 时的验证 bbox AP 曲线(目标检测平均精度),图 4 展示了在 R50 上使用 SyncBN 时的验证 bbox AP 曲线。其中灰色曲线为 ImageNet 预训练+微调的结果,紫色曲线为随机初始化训练的结果。
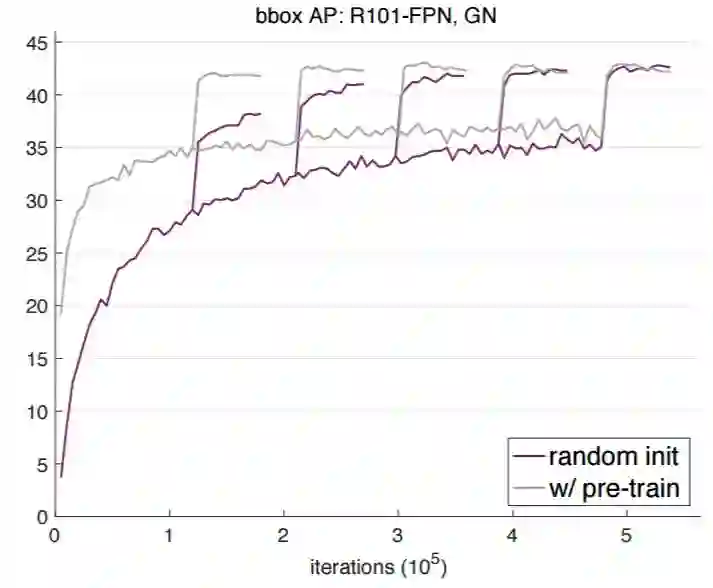
图 3:使用 Mask R-CNN 和 R101-FPN 以及 GN 在 COCO val2017 数据集上得到的 bbox AP 学习曲线。
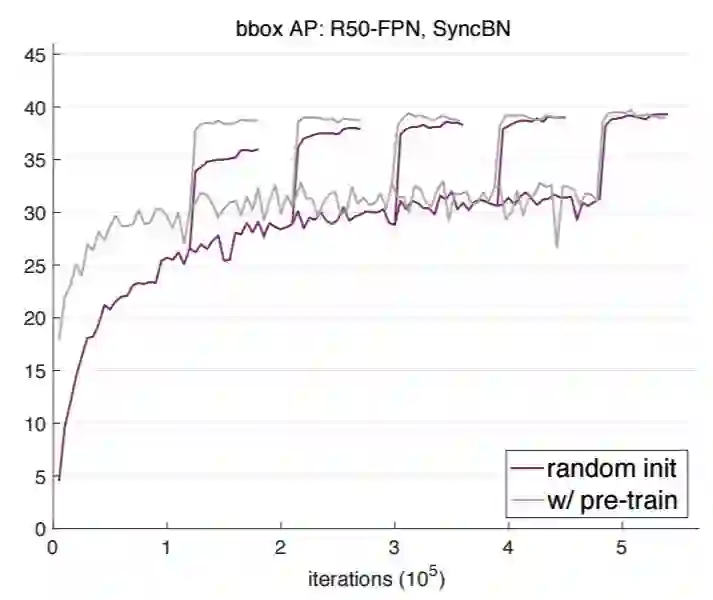
图 4:使用 Mask R-CNN 和 R50-FPN 以及 SyncBN(在 GPU 上同步批量统计)在 COCO val2017 数据集上得到的 bbox AP 学习曲线。
以下总结了图 1、3、4 的相似现象:
典型的微调方案(2x)结合预训练模型可以很好地收敛到近最优结果(参见表 1,「w/ pre-train」)。但是这样的迭代次数对于从零开始训练的模型并不足够。
从零开始训练的模型在足够多的迭代次数(5× 或 6×)下可以达到和微调变体相当的性能。
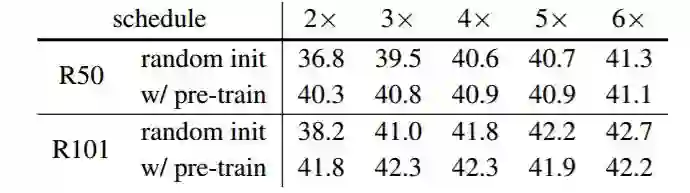
表 1:在 COCO val2017 数据集上的目标检测性能对比。其中 2x 表示 180k 迭代数,6x 表示 540k 迭代数。
实际上,在很多种训练条件设置下,对于目标检测和实例分割任务,随机初始化方案都能和预训练+微调方案达到相似的性能,如图 5 所示。
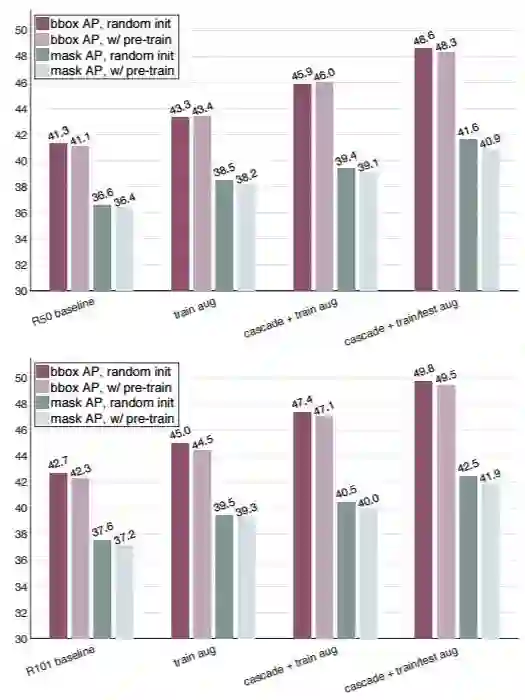
图 5:随机初始化 vs 预训练+微调的性能对比,包括(1)使用 FPN 和 GN 的基线模型;(2)训练时间多尺度增强的基线模型;(3)使用 Cascade R-CNN 和训练时间增强的基线模型;(4)使用 Cascade R-CNN、训练时间增强以及测试时间多尺度增强的基线模型。顶部:R50,底部:R101。
用更少数据从零开始训练
我们第二个发现更令人惊讶,是当使用显著更少的数据训练时(例如,1/10 个 COCO),从零开始训练的模型并不比预训练+微调的模型更差。图 7 展示了两种方法用 35k 样本数和 10k 样本数的 COCO 数据集训练的结果对比。
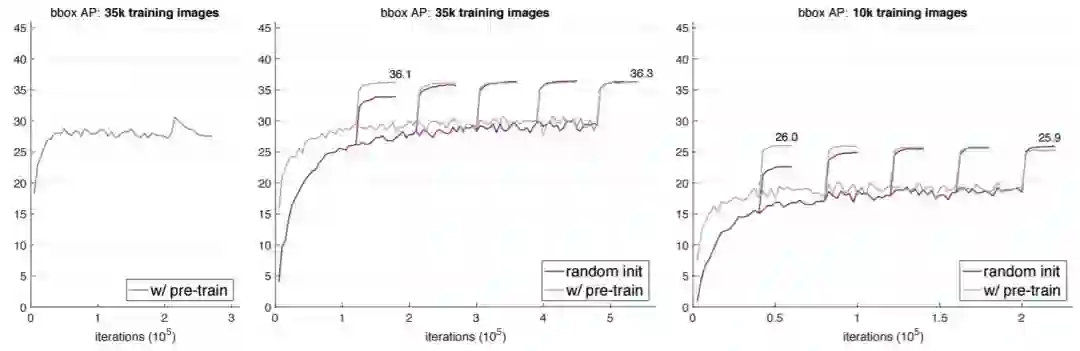
图 7:使用更少的 COCO 数据集图像(左/中:35k;右:10k)进行训练。模型为带有 R50-FPN 和 GN 的 Mask R-CNN,在 val2017 上评估 bbox AP。左:使用 35k COCO 图像进行训练,用了为 118k train2017 选取的默认超参数。在学习率改变之前及之后表现出了过拟合。中:使用 35k COCO 图像进行训练,用了针对『w/ pre-train』进行优化的超参数(相同的超参数接下来会应用到从随机初始化开始训练的模型中)。右:用 10k COCO 图像进行训练,用了针对『w/ pre-training』进行优化的超参数。
但是样本数再少也有个极限,如图 8 所示,用 1k 样本数训练时,随机初始化模型会强烈地过拟合。
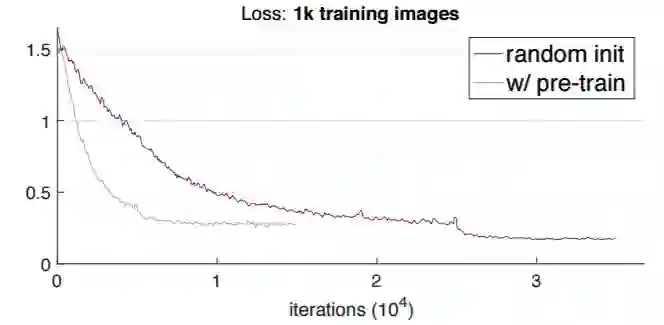
图 8:用 1k COCO 图像进行训练。模型是带有 R50-FPN 和 GN 的 Mask R-CNN。和之前一样,我们使用为预训练模型优化过的超参数,并把同样的超参数应用于随机初始化的模型。随机初始化的模型可以弥补训练损失,但验证准确率(3.4 AP)低于预训练模型(9.9 AP)。这是一个强烈过拟合的迹象,是由严重缺乏数据造成的。
我们还发现了另一个从零开始训练不如预训练+微调的案例:PASCAL VOC 数据集。我们在 trainval2007+train2012 数据集上进行训练,并在 val2012 上进行评估。利用 ImageNet 预训练,我们的 Faster R-CNN 基线(使用了 R101-FPN 和 GN,仅训练时间增加)在 18k 次迭代中达到了 82.7 mAP。相对的,在 VOC 上从头开始的训练在 144k 次迭代中达到了 77.6 mAP,并且继续增加训练时间也无法超越前者。
讨论
我们对实验中获得的主要观察结果进行了总结,如下所示:
无需更改架构,就可以在目标任务上从头开始训练并取得不错的结果。
从头开始训练需要更多的迭代才能充分收敛。
在很多情况下,从头开始训练不会比 ImageNet 预训练差多少,且训练样本数最少可达 10k COCO 图像。
ImageNet 预训练加快了目标任务的收敛速度。
ImageNet 预训练不一定有助于减少过拟合,除非我们访问的是非常小的数据范围。
如果目标任务对定位比分类更敏感,ImageNet 预训练的作用会减小。
ImageNet 预训练是必要的吗?——如果我们有足够的目标数据和计算资源,就不必要。
ImageNet 有用吗?是的,ImageNet 预训练对计算机视觉社区的发展来说是一项重要的辅助任务。
我们需要大数据吗?是的,但如果考虑收集和清理数据所需的额外努力,一个通用的大规模、分类级别的预训练集并不划算。
我们应该追求通用表征吗?是的。我们认为学习通用表征是一个不错的目标。我们的结果并没有偏离这个目标。

今天有哪些论文值得一读?扫码开启订阅,每天15:00及时速递。





