ICLR 2020,你的论文提供代码了吗?这届评审不好惹
【导读】ICLR 2020上个月刚刚截止submission,共收到近 2600 篇投稿,竞争尤其激烈。现在进入open review阶段,每年的ICLR公开评审都是大家集体看戏的阶段,各方学者纷纷赶来或围观或质疑或膜拜,今年也不例外,并且这届online的reviewer不好惹,都很刚!专知小编也不例外,当起了吃瓜群众,在此给大家截取一段争论比较激烈的评论。
一篇关于GNN方向的提交论文DropEdge: Towards Deep Graph Convolutional Networks on Node Classification,其方法由于结果表现太好被广大网友质疑。一名叫 Alex Williams 的小哥 “放出狠话”,公开叫板,直怼作者团队。认为作者的方法带来的基本上都是伪提升,是改变了数据训练比例的“作弊”手段,对其他科研工作者不公平。作者团队也正面刚回去,并提供了源代码, Alex Williams 小哥继续说他要复现作者论文的结果,看看到底是否有问题。

关于顶会论文是否需要提供代码?论文结果是否能够复现?这些问题,已经被讨论了多次,对于这次的ICLR open review,小编又想重提这些问题。前一段时间,专知也报道过推荐系统顶会 RecSys2019 最佳论文奖出炉!可复现性成为焦点—18篇顶级会议只有7篇可以合理复现。
由于目前的好多的研究结果都缺乏可复现性,很多优秀研究都没有提供对应的代码,这对进一步地开展工作是有损失的,对读者而言,附加代码(和数据)明显增加了一篇论文的深度价值,但是由于不同研究主题和领域对代码的需求不同,代码提交是可以鼓励的,并不应该是强制性的。
专知小编带大家来回顾一下这篇ICLR上的在审论文和故事线。
题目:DropEdge: Towards Deep Graph Convolutional Networks on Node Classification
作者:暂时不知

【摘要】过拟合(over-fitting)和过度平滑(over-smoothing)是用于节点分类的深度图卷积网络(GCN)的两个主要障碍。特别是,过拟合会削弱小数据集的泛化能力,而过度平滑会随着网络深度的增加而将输出的表示从输入特征中分离出来,从而阻碍模型的训练。本文提出了一种新颖灵活的技术DropEdge来缓解这两个问题。其核心在于,DropEdge在每个训练epoch随机地从输入图中删除一定数量的边,充当数据扩充器和消息传递减速器。此外,我们还从理论上证明了DropEdge会延迟过度平滑的收敛速度或减轻其造成的信息丢失。更重要的是,我们的DropEdge是一项通用技能,可以配备许多其他主干模型(例如GCN,ResGCN,GraphSAGE和JKNet)以增强性能。在多个基准测试中进行的大量实验证明,DropEdge可以持续改善各种浅层和深层GCN的性能。通过实验验证了DropEdge在防止过平滑方面的效果。代码将在发表时公开。

参考链接:
https://openreview.net/forum?id=Hkx1qkrKPr
代码链接:
https://github.com/DropEdge/DropEdge
小哥Alex Williams首先刚起来:
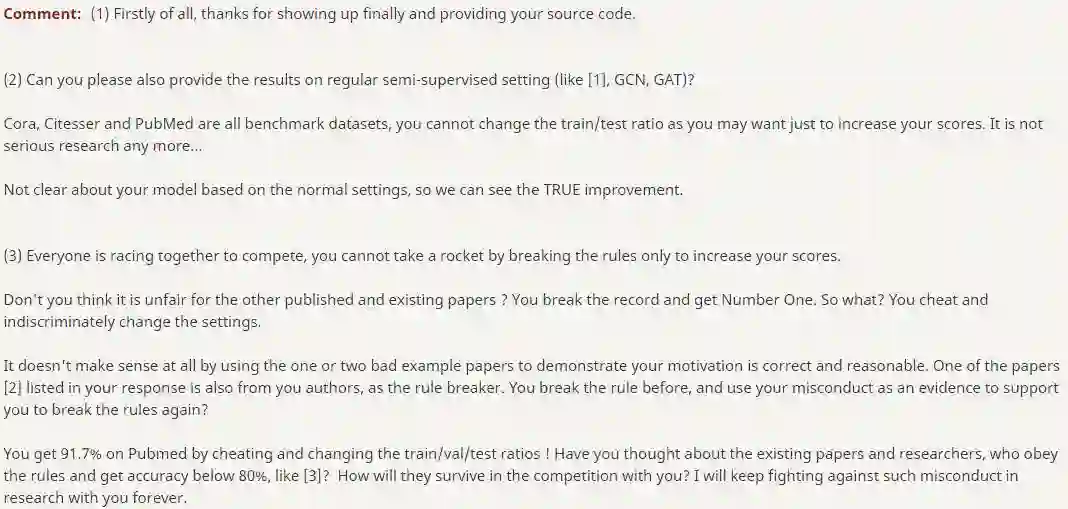
It's unfair. Everyone is racing to compete, you cannot take a rocket to increase your scores via changing the train/val/test ratios by yourself... I will keep fighting against your misconduct in research forever!
大意如下:
这不公平。每个人都努力在竞争,你们不可能通过改变train/val/test的比例, 像坐火箭般提高score…我将永远与你们的科研不端行为作斗争!
Alex Williams
Comment:
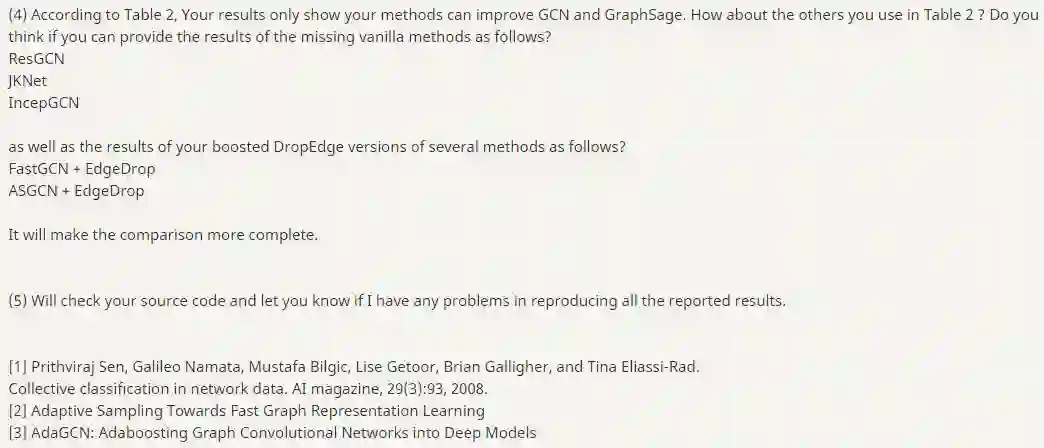
(1) 首先,感谢你们最后的露面,并提供了你们的源代码。
(2) 能否提供常规半监督设置(如[1],GCN, GAT)下的结果? Cora, Citesser和PubMed都是基准数据集,你们不能更改训练/测试的比例,因为你们可能只是想提高实验分数。这不再是一项严肃的研究……
基于实验基本的设置,我并不清楚你们的模型究竟是什么样的,是不是真正得到提升的
(3) 每个人都在比赛竞争,你们不能为了提高成绩而打破规则。
你不认为这对其他已经发表和存在的论文是不公平的吗? 你们打破了记录,得了第一名。那又怎样? 你们作弊,并且随意更改设置。
用一两个不好的例子来证明你们的动机是正确和合理的,这根本没有意义。在你们的回复中列出的一篇论文[2]也是来自你们文章的作者,这是破坏规则的人(小哥这是猜到了这篇论文的作者?)。你们以前违反过规则,难道要用你们的不当行为作为证据来支持再次违反规则?
通过作弊和更改train/val/test比率,你们在Pubmed上获得了91.7%的分数! 你们有没有想过现有的论文和研究人员,他们遵守规则,正确率低于80%(就像[3])?,他们将如何在与你们的竞争中生存? 我将永远和他们一起与你们这种研究中的不端行为作斗争。
(4) 根据表2,你们的结果只表明你们的方法可以改善GCN和GraphSage。那么表2中使用的其他方法呢?是否可以提供以下缺少的基本方法的结果?
ResGCN
JKNet
IncepGCN
以及以下几种方法的提升DropEdge版本的结果?
FastGCN + EdgeDrop
ASGCN + EdgeDrop
这将使比较更加完整。
(5) 我将检查你们的源代码,并让你们知道在复现所有reported的结果的过程中出现的任何问题。
[1] Prithviraj Sen, Galileo Namata, MustafaBilgic, Lise Getoor, Brian Galligher, and Tina Eliassi-Rad. Collective classification in network data.AI magazine, 29(3):93, 2008.
[2] Adaptive Sampling Towards Fast GraphRepresentation Learning
[3] AdaGCN: Adaboosting Graph ConvolutionalNetworks into Deep Models
作者给出回复:
We only accept constructive and valuable discussions but not offensive and impolite comments.

大意如下:
我们只接受有建设性和有价值的讨论,不接受冒犯和不礼貌的评论。
ICLR 2020 Conference Paper1862 Authors
Comment:
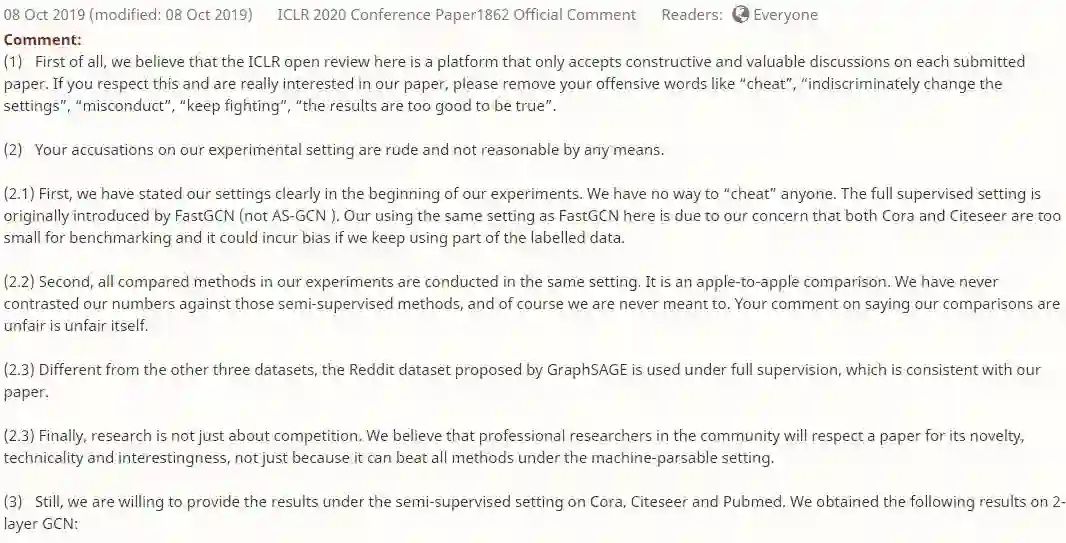
(1) 首先,我们认为ICLR在这里的公开评审是一个平台,只接受对提交的每一篇文章的建设性和有价值的讨论。如果你尊重这一点,并且真的对我们的论文感兴趣,请删除你的攻击性词汇,如“cheat”,“ indiscriminately change thesettings”,“ misconduct”,“ keepfighting”,“ the results are too good to be true”。
(2) 您对我们实验设置的指责是粗鲁的,是不合理的。
(2.1) 首先,我们在实验开始的时候就已经清楚地说明了我们的设置。我们不会“欺骗”任何人。完整的监督设置最初是由FastGCN(不是AS-GCN)引入的。我们在这里使用与FastGCN相同的设置是因为我们担心Cora和Citeseer数据集都太小,无法进行基准测试,如果我们继续使用部分标记数据,可能会产生偏差。
(2.2) 其次,我们实验中所有比较的方法都是在相同的设置下进行的。这是基于一个公平、合理的标准进行比较的,我们从未将我们的结果与那些半监督的方法进行对比,当然我们也从未打算这么做。你说我们的比较是不公平的,这本身就是不公平的。
(2.3) 与其他三个数据集不同的是,GraphSAGE提出的Reddit数据集是在完全监督下使用的,这与我们的论文是一致的。
(2.3) 最后,研究不仅仅只是竞争。我们相信,专业的研究人员会因为一篇论文的新颖性、技术性和趣味性而尊重它,而不仅仅是因为它可以在机器可解析的环境下击败所有方法。
(3) 我们仍然愿意在Cora、Citeseer和Pubmed的半监督设置下提供结果。我们在2层GCN上得到了以下结果:
| orginal| no-dropedge (ours)| dropedge(ours)|
-------------------------------------------------------------------------------
Cora | 81.5 | 81.1 | 82.8 |
Citeseer | 70.3 | 70.8 | 72.3 |
Pubmed | 79.0 | 79.0 | 79.6 |
第一列的结果来自原始的GCN论文,后两列的结果分别对应于GCNs的without和withDropEdge。值得注意的是,没有DropEdge的结果与GCN论文中的结果相当,表明了我们实验的可靠性;添加DropEdge可以持续提高所有三个数据集的性能。如果有必要,我们将在其他主要框架上添加更多的结果。
总的来说,我们真诚地希望您能更多地尊重我们的工作,并继续就我们方法的动机、公式和趣味性进行讨论。如果你继续使用无礼的语气,我们将拒绝回答你的任何问题。
小哥Alex Williams继续:
Give up your dirty trick. Show your respect for other researchers' efforts, then you will receive respect from them as a reward
大意如下:
放弃你们的作弊手段。请尊重其他研究人员的努力成果,这样你们也会得到他们的尊重。
Alex Williams
Comment:
基于你们提供的结果,你们仍然认为你们的方法可以超越现有的方法[1]吗?
再次感谢你们提供的基于常规半监督设置的结果。请不要误解我的话。我不在乎竞争,我只在乎公平。
我也可以写一篇论文,通过改变train/test的比例,把分数提高到99%以上。你们认为这样的论文对你有意义吗? 如果每个人的行为都像你们的团队一样肮脏,这对社区的发展也是不健康的, 是很不利的。
不确定在你们的团队中是谁提出的这样的“肮脏”想法, 但这真的让其他研究人员感到悲伤和沮丧。如果这个坏主意是年轻人提出的,还是建议尊重其他研究人员的努力,因为你还有很长的学术旅程要走。放弃你的“肮脏伎俩”,你也会得到社会的尊重。这是我的建议。
如果你们还坚持认为你们的卑鄙手段是正确的,我将继续与你们抗衡此类不当行为。我不太了解你们的作者和你们的研究所,但是你们的团队给我留下了很坏的印象。
PS. 这是我的最后一个评论。我将就此停止。
[1] https://paperswithcode.com/task/node-classification
Paper1862 Area Chair1 发声:
Please stop

大意如下:
请停止
ICLR 2020 Conference Paper1862 Area Chair1
Comment:
如果你能停止冒犯作者,在接下来的讨论中提出学术问题(包括这次讨论),我将不胜感激。
对相同的数据集使用不同的分割或设置并不是一个“肮脏”的技巧,只要明确指定了分割,特别是考虑到作者遵循了之前使用相同分割的几篇已经发表的论文。