【重温序列模型】再回首DeepLearning遇见了Transformer

前言
今天分享的论文是2017年谷歌团队发表的一篇论文,这是一篇非常经典的自然语言处理领域的文章,基于这篇文章,才有了最近非常火的bert, Albert等模型,有以下亮点:
-
提出了一种Transformer的结构,这种结构呢,是完全依赖注意力机制来刻画输入和输出之间的全局依赖关系,而不使用递归运算的RNN网络了。这样的好处就是第一可以有效的防止RNN存在的梯度消失的问题,第二是允许所有的字全部同时训练(RNN的训练是迭代的,一个接一个的来,当前这个字过完,才可以进下一个字),即训练并行,大大加快了计算效率。 -
Transformer使用了位置嵌入来理解语言的顺序,使用了多头注意力机制和全连接层等进行计算,还有跳远机制,LayerNorm机制,Encoder-Decoder架构等。这里面比较重要且难以理解的就是Multi-Head Attention机制了,后面也会详细的介绍这个机制。
论文下载:https://arxiv.org/abs/1706.03762

分享大纲如下:
-
PART ONE : Abstract -
PART TWO: Introduction -
PART THREE: Model Architecture(详细剖析) -
PART FROE: Training -
PART FIVE: Conclusion
1. Abstract
摘要部分说了一下目前用于序列转换的模型依然是Encoder-Decoder结构的RNN或者CNN。效果比较好的是Encoder-Attention-Decoder这样的结构。所以在这里作者基于Encoder-Decoder提出了一种完全依赖Attention机制的Transformer模型,并且可以并行化而减少训练时间,实验表明,效果很好。 之前的结构类似这样:
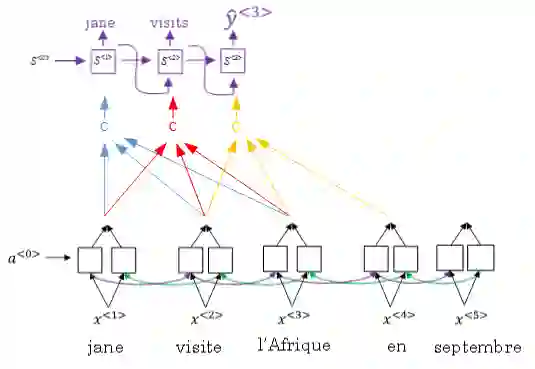
2. Introduction
说了一下上面的这种结构的弊端:就是需要递归迭代运行,没法并行化,这样对于很长的句子来说,很可能出现梯度消失的情况,并且计算量也很大,速度比较慢。所以需要改进。
Attention是利用局部聚焦的思想去建立注意力模型,但目前这样的机制都是和RNN连接。(self-attention, 有时也称为内注意,是一种将单个序列的不同位置联系起来以计算序列表示的注意机制。)
所以提出了一种Transformer模型,这种模型不用RNN或者说CNN这种递归机制,而是完全依赖于Attention。
3. Model Architecture(主角登场)
这是本篇文章的主角,也是我想重点说的地方。下面这个就是Transformer,先看总体结构:
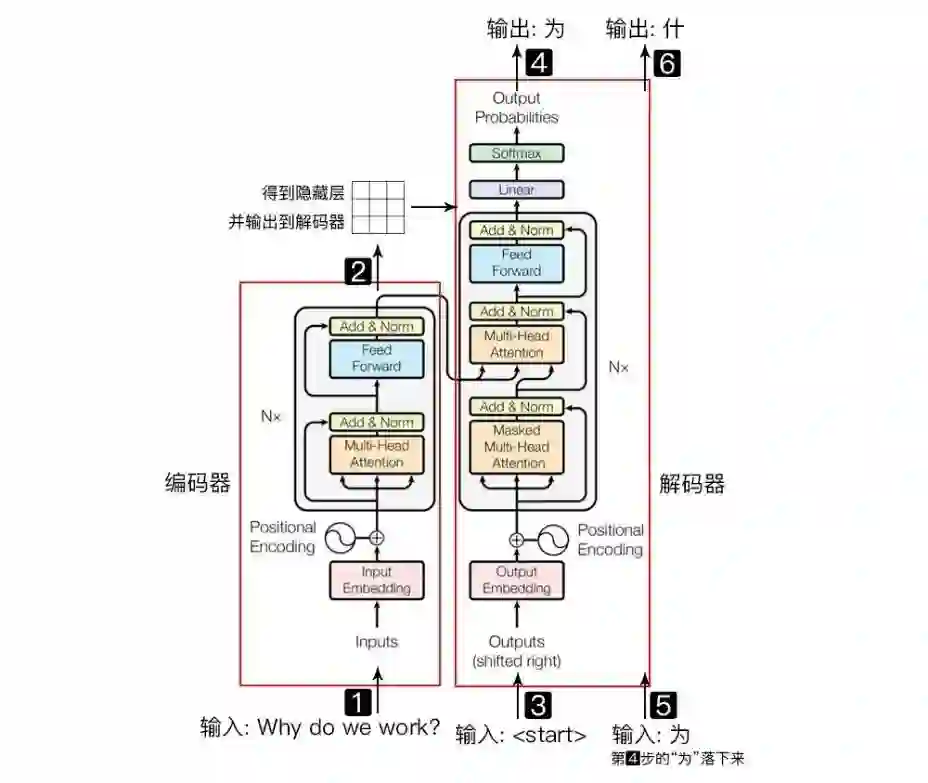
从这个结构的宏观角度上,我们可以看到Transformer模型也是用了Encoder-Decoder结构,编码器部分负责把自然语言序列映射成为隐藏层(就上面那个九宫格),含有自然语言序列的数学表达,然后解码器把隐藏层再映射为自然语言序列,从而使我们可以解决各种问题,比如情感分类,命名实体识别,语义关系抽取,机器翻译,摘要生成等等。
先简单说一下上面的结构的工作流程:比如我做一个机器翻译(Why do we work?) -> 为什么要工作?
-
输入自然语言序列:Why do we work? -
编码器输出的隐藏层是Why do we work的一种数学表示,类似于提取了每一个词的信息,然后汇总,转换成了这句话的数学向量。然后输入到解码器 -
输入 符号到解码器 -
就会得到第一个字“为” -
将得到的第一个字“为”落下来再输入到编码器 -
得到第二个字“什” -
将得到的第二个字落下来输入,得到“么”,重复,直到解码器输出 。翻译完成
下面重点讲讲细节部分了。看看究竟是怎么得到数学向量的,以及怎么通过数学向量得出最终答案的?
3.1 编码器部分的工作细节
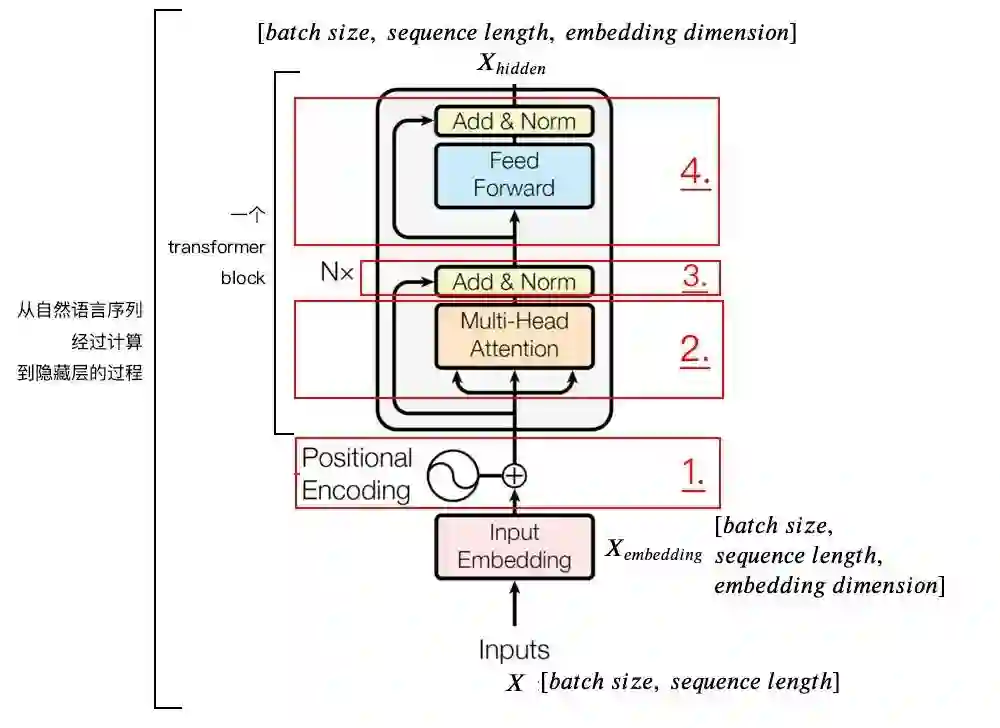
我们输入句子:Why do we work? 的时候,它的编码流程进一步细化:
-
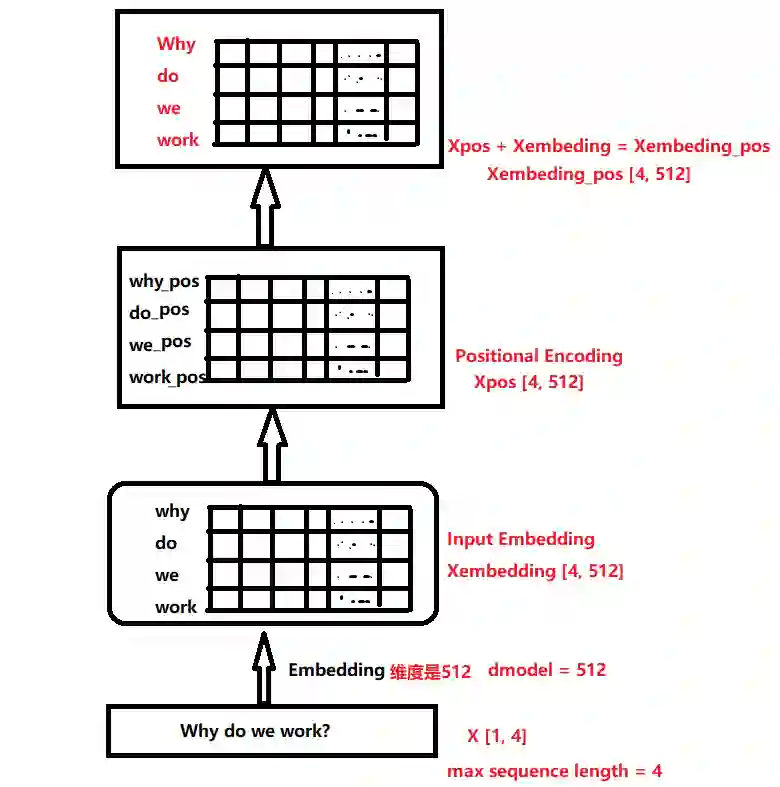
首先输入进来之后,经过Input Embedding层每个字进行embedding编码(这个后面会说),然后再编入位置信息(position Encoding),形成带有位置信息的embedding编码。 -
然后进入多头注意力部分,这部分是多角度的self-attention部分,在里面每个字的信息会依据权重进行交换融合,这样每一个字会带上其他字的信息(信息多少依据权重决定),然后进入feed-forward部分进行进一步的计算,最后就会得到输入句子的数学表示了。
下面再详细说一下每一部分的细节:
-
位置嵌入由于transformer模型没有循环神经网络的迭代操作, 所以我们必须提供每个字的位置信息给transformer, 才能识别出语言中的顺序关系。
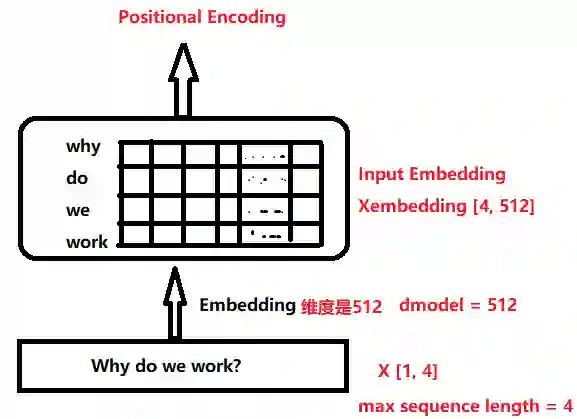
现在定义一个位置嵌入的概念,也就是现在定义一个位置嵌入的概念, 也就是𝑝𝑜𝑠𝑖𝑡𝑖𝑜𝑛𝑎𝑙 𝑒𝑛𝑐𝑜𝑑𝑖𝑛𝑔, 位置嵌入的维度为[𝑚𝑎𝑥 𝑠𝑒𝑞𝑢𝑒𝑛𝑐𝑒 𝑙𝑒𝑛𝑔𝑡ℎ, 𝑒𝑚𝑏𝑒𝑑𝑑𝑖𝑛𝑔 𝑑𝑖𝑚𝑒𝑛𝑠𝑖𝑜𝑛], 嵌入的维度同词向量的维度, 𝑚𝑎𝑥 𝑠𝑒𝑞𝑢𝑒𝑛𝑐𝑒 𝑙𝑒𝑛𝑔𝑡ℎ属于超参数, 指的是限定的最大单个句长.
注意, 我们一般以字为单位训练transformer模型, 也就是说我们不用分词了, 首先我们要初始化字向量为[𝑣𝑜𝑐𝑎𝑏 𝑠𝑖𝑧𝑒, 𝑒𝑚𝑏𝑒𝑑𝑑𝑖𝑛𝑔 𝑑𝑖𝑚𝑒𝑛𝑠𝑖𝑜𝑛], 𝑣𝑜𝑐𝑎𝑏 𝑠𝑖𝑧𝑒为总共的字库数量, 𝑒𝑚𝑏𝑒𝑑𝑑𝑖𝑛𝑔 𝑑𝑖𝑚𝑒𝑛𝑠𝑖𝑜𝑛为字向量的维度, 也是每个字的数学表达.好吧,如果这里开始不懂了, 我们就拿我们的例子来看一下子:
这里论文里面使用了sine和cosine函数的线性变换来提供给模型的位置信息:
上式中 指的是句中字的位置, 取值范围是, 指的是词向量的维度, 取值范围是, 上面有 和 一组公式, 也就是对应着维度的一组奇数和偶数的序号的维度, 例如 一组, 一组, 分别用上面的 和 函数做处理, 从而产生不同的周期性变化, 而位置嵌入在维度上随着维度序号增大, 周期变化会越来越慢, 而产生一种包含位置信息的纹理, 就像论文原文中第六页讲的
位置嵌入函数的周期从 到 变化, 而每一个位置在维度上都会得到不同周期的 和 函数的取值组合, 从而产生独一的纹理位置信息, 模型从而学到位置之间的依赖关系和自然语言的时序特性.
还是拿例子举例, 我们看看我们的输入Why do we work? 的位置信息怎么编码的?这样第三个,第四个词的编码这样下去。编码实现如下:
 这里论文里面使用了sine和cosine函数的线性变换来提供给模型的位置信息:
这里论文里面使用了sine和cosine函数的线性变换来提供给模型的位置信息: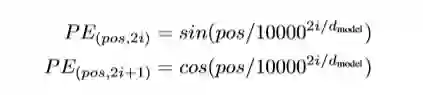 上式中
上式中 位置嵌入函数的周期从
位置嵌入函数的周期从 这样第三个,第四个词的编码这样下去。编码实现如下:
这样第三个,第四个词的编码这样下去。编码实现如下:def get_positional_encoding(max_seq_len, embed_dim):
# 初始化一个positional encoding
# embed_dim: 字嵌入的维度
# max_seq_len: 最大的序列长度
positional_encoding = np.array([
[np.sin(pos / np.power(10000, 2 * i / embed_dim)) if i%2==0 else
np.cos(pos / np.power(10000, 2*i/embed_dim))
for i in range(embed_dim) ]
for pos in range(max_seq_len)])
return positional_encoding
positional_encoding = get_positional_encoding(max_seq_len=100, embed_dim=16)
positional_encoding = get_positional_encoding(max_seq_len=100, embed_dim=16)
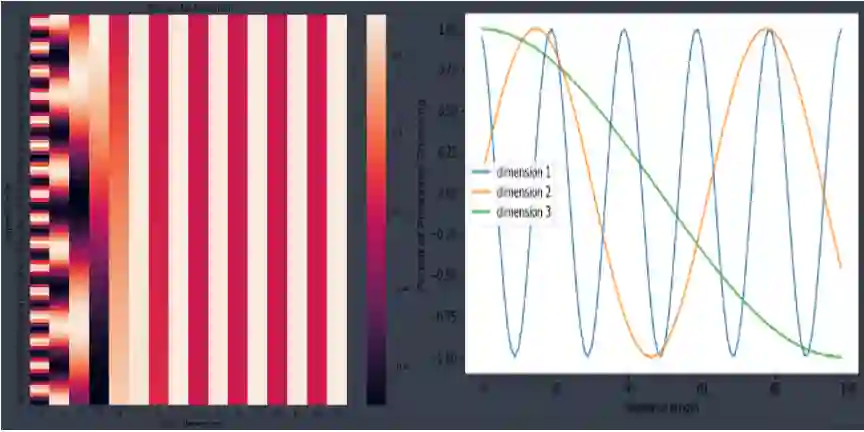
plt.figure(figsize=(10,10))
sns.heatmap(positional_encoding)
plt.title("Sinusoidal Function")
plt.xlabel("hidden dimension")
plt.ylabel("sequence length")
plt.figure(figsize=(8, 5))
plt.plot(positional_encoding[1:, 1], label="dimension 1")
plt.plot(positional_encoding[1:, 2], label="dimension 2")
plt.plot(positional_encoding[1:, 3], label="dimension 3")
plt.legend()
plt.xlabel("Sequence length")
plt.ylabel("Period of Positional Encoding")
可视化一下,最后得到这样的效果:
所以, 会得到Why do we work这四个词的位置信息, 然后Embedding矩阵和位置矩阵的加和作为带有位置信息的新X,Xembedding_pos
-
多头注意力机制这一步为了学到多重语意含义的表达,进行多头注意力机制的运算。不要被这个多头注意力给吓住,其实这里面就是用到了几个矩阵运算,先不用管怎么运算的,我们先宏观看一下这个注意力机制到底在做什么?拿单头注意力机制举例:
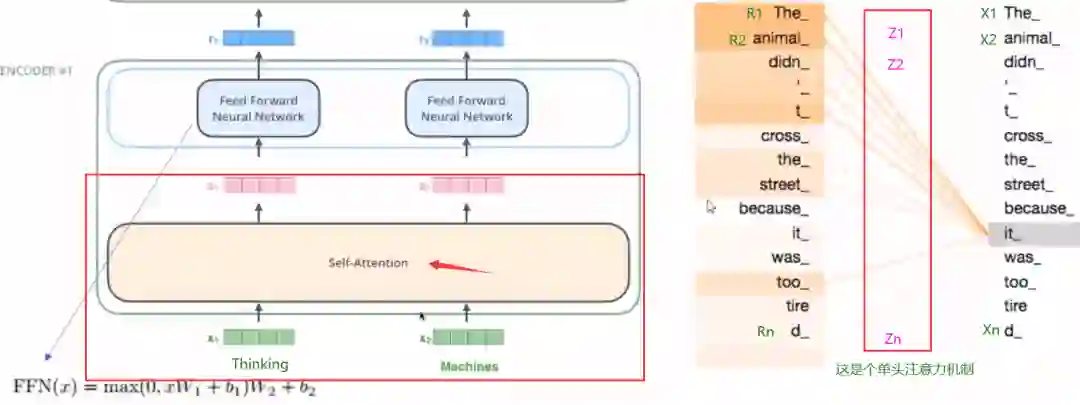
左边的红框就是我们现在讲的部分,右图就是单头注意力机制做的事情,拿句子:The animal didn’t cross the street, because it was too tired. 我们看it这个词最后得到的R矩阵里面,就会表示出这个it到底是指的什么, 可以看到R1和R2和it最相关,就可以认为it表示的是The animal。
也就是说,每一个字经过映射之后都会对应一个R矩阵, 这个R矩阵就是表示这个字与其他字之间某个角度上的关联性信息,这叫做单头注意力机制。(具体怎么做到的,下面会说)
下面看一下多头注意力宏观上到底干了什么事情: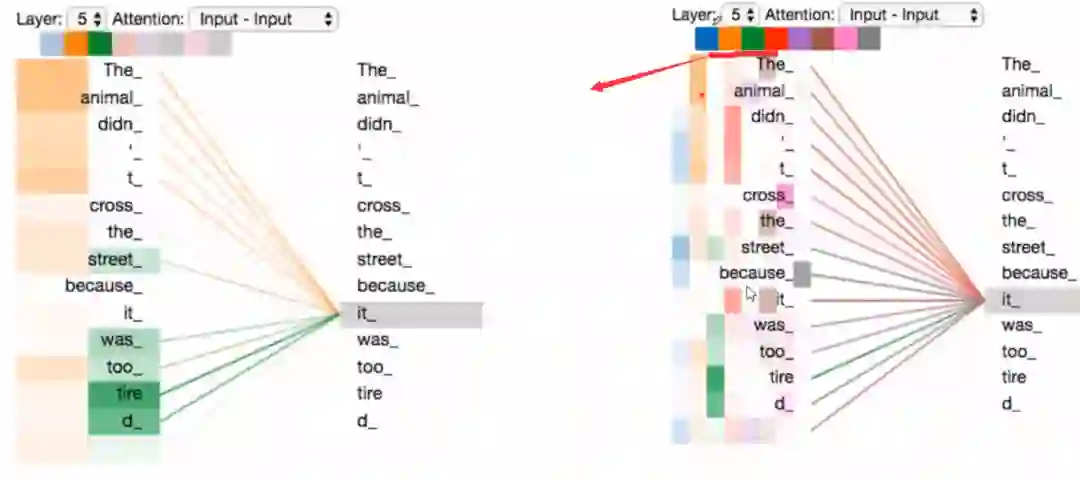
这样是不是就能明白多头注意力的意义了啊,每个字经过多头注意力机制之后会得到一个R矩阵,这个R矩阵表示这个字与其他字在N个角度上(比如指代,状态..)的一个关联信息,这个角度就是用多个头的注意力矩阵体现的。这就是每个字多重语义的含义。
那么究竟是怎么实现的呢? 其实这个过程中就是借助了三个矩阵来完成的。下面具体看一下:
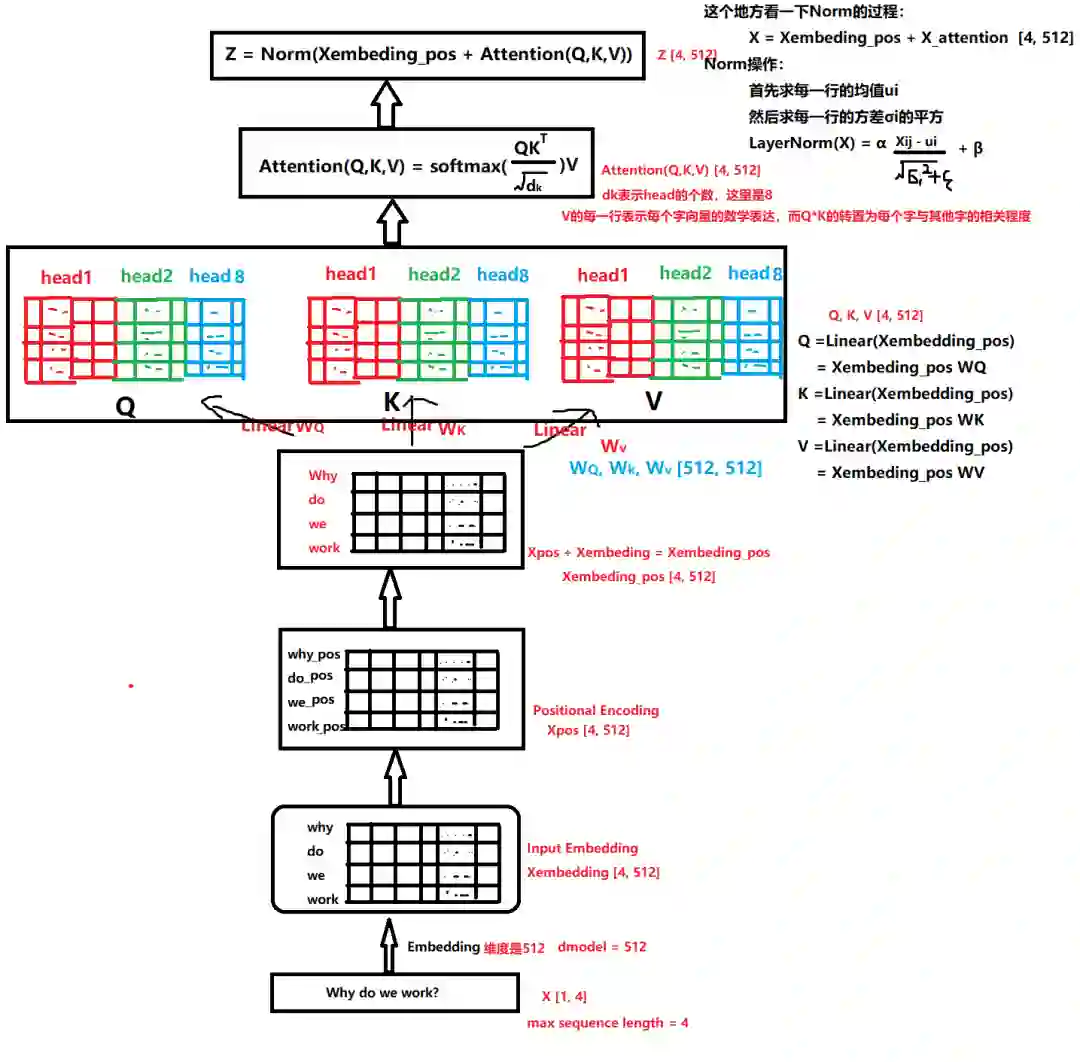
我们的目标是把我们的输入Xembedding_pos通过多头注意力机制(系列线性变换)先得到Z。然后Z通过前馈神经网络得到R。这个R矩阵表示这个字与其他字在N个角度上(比如指代,状态..)的一个关联信息。
先看看怎么得到这个Z: 在Xembedding_pos->Z的过程中到底发生了什么呢?
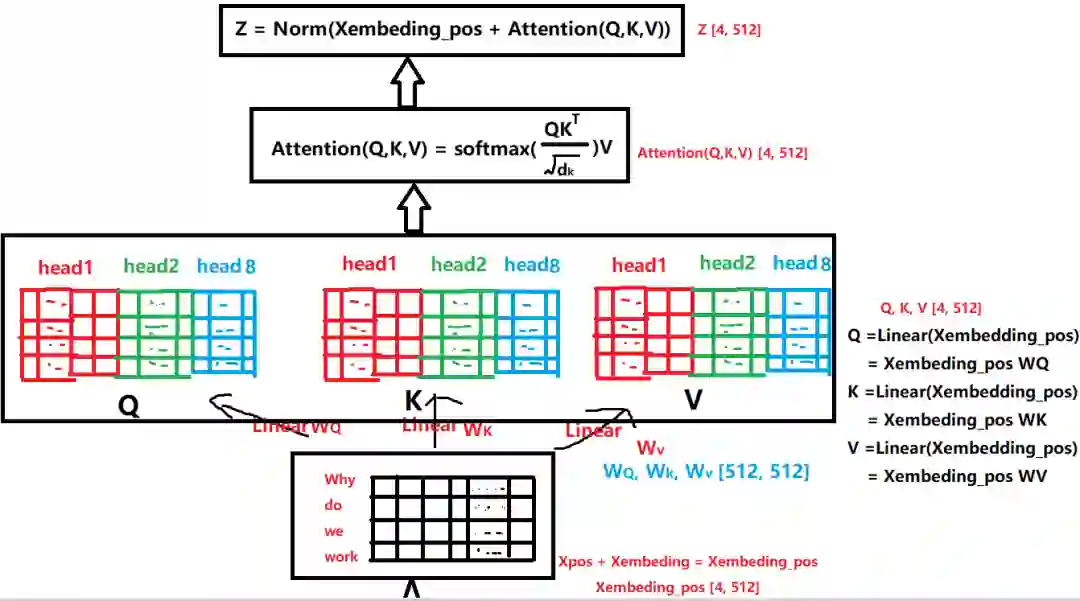
这就是整个过程的变化,首先Xembedding_pos会做三次线性变化得到Q,K,V,三个矩阵,然后里面Attention机制,把Q,K,V三个矩阵进行运算,最后把Attention矩阵和Xembedding_pos加起来就是最后的Z。
可是为什么要这么做呢?Q,K,V又分别表示什么意思呢?
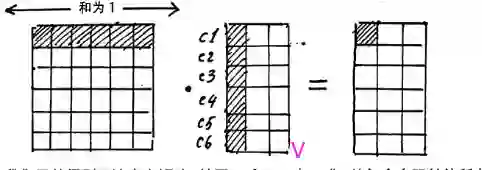
我们先说第二个问题,Q,K,V这三个矩阵分别是什么意思, Q表示Query,K表示Key,V表示Value。之所以引入了这三个矩阵,是借鉴了搜索查询的思想,比如我们有一些信息是键值对(key->value)的形式存到了数据库,(5G->华为,4G->诺基亚), 比如我们输入的Query是5G, 那么去搜索的时候,会对比一下Query和Key, 把与Query最相似的那个Key对应的值返回给我们。 这里是同样的思想,我们最后想要的Attention,就是V的一个线性组合,只不过根据Q和K的相似性加了一个权重并softmax了一下而已。下面具体来看一下:
上面图中有8个head, 我们这里拿一个head来看一下做了什么事情:(请注意这里head的个数一定要能够被embedding dimension整除才可以,上面的embedding dimension是512, head个数是8,那么每一个head的维度是(4, 512/8))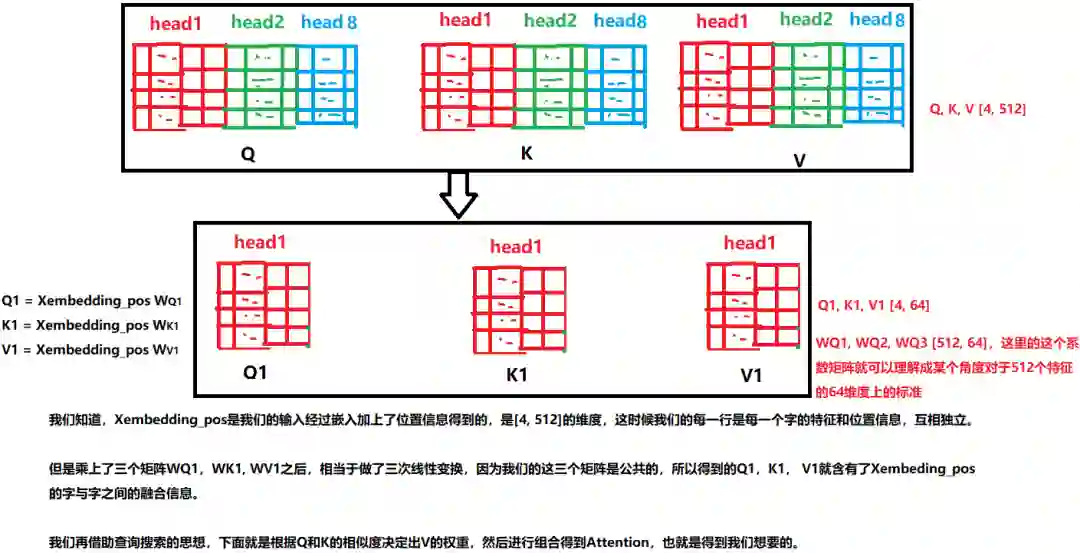
我们看看Q1*K1的转置表达的是个什么意思: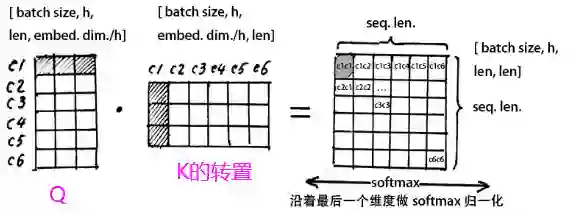
但是我们有8个head头的,我们假设每一个头的Q1,K1服从标准正态的话,那么八个头堆叠的大矩阵Q和K的点积运算之后会服从均值为1, 方差为64的正态(相当于A服从N(0,1)的标准正态, 8A就服从N(0, 64)),这时候为了方向传播的时候能够获取平衡的梯度,我们有一个QK的转置然后除以根号64的操作,这时候把矩阵变成了标准正态。
用这个加上之前的Xembedding_pos得到残差连接,训练的时候可以使得梯度直接走捷径反传到最初层,不易消失。
再经过一个LayerNormlization操作就可以得到Z。LayerNormlization的作用是把神经网络中隐藏层归一化为标准正态分布,起到加快训练速度,加速收敛的作用。类似于BatchNormlization,但是与BatchNormlization不同的是前者是以行为单位(每一行减去每一行的均值然后除以每一行的标准差),后者是一个Batch为单位(每一个元素减去Batch的均值然后除以Batch的标准差)。
所以多头注意力机制细节总结起来就是下面这个图了:
-
前馈神经网络(FeedForward)这一块就比较简单了,我们上面通过多头注意力机制得到了Z,下面就是把Z再做两层线性变换,然后relu激活就得到最后的R矩阵了。(相当于一个两层的神经网络)
-
Layer Normalization和残差连接
1)残差连接:
我们在上一步得到了经过注意力矩阵加权之后的
, 也就是
, 我们对它进行一下转置, 使其和
的维度一致, 也就是, 然后把他们加起来做残差连接, 直接进行元素相加, 因为他们的维度一致:
在之后的运算里, 每经过一个模块的运算, 都要把运算之前的值和运算之后的值相加, 从而得到残差连接, 训练的时候可以使梯度直接走捷径反传到最初始层:
2) LayerNorm
的作用是把神经网络中隐藏层归一为标准正态分布, 也就是 独立同分布, 以起到加快训练速度, 加速收敛的作用:
上式中以矩阵的行 为单位求均值;
上式中以矩阵的行 为单位求方差;
然后用每一行的每一个元素减去这行的均值, 再除以这行的标准差, 从而得到归一化后的数值,
是为了防止除
;
之后引入两个可训练参数
来弥补归一化的过程中损失掉的信息, 注意
表示元素相乘而不是点积, 我们一般初始化
为全
, 而
为全
.
所以一个Transformer编码块做的事情如下:
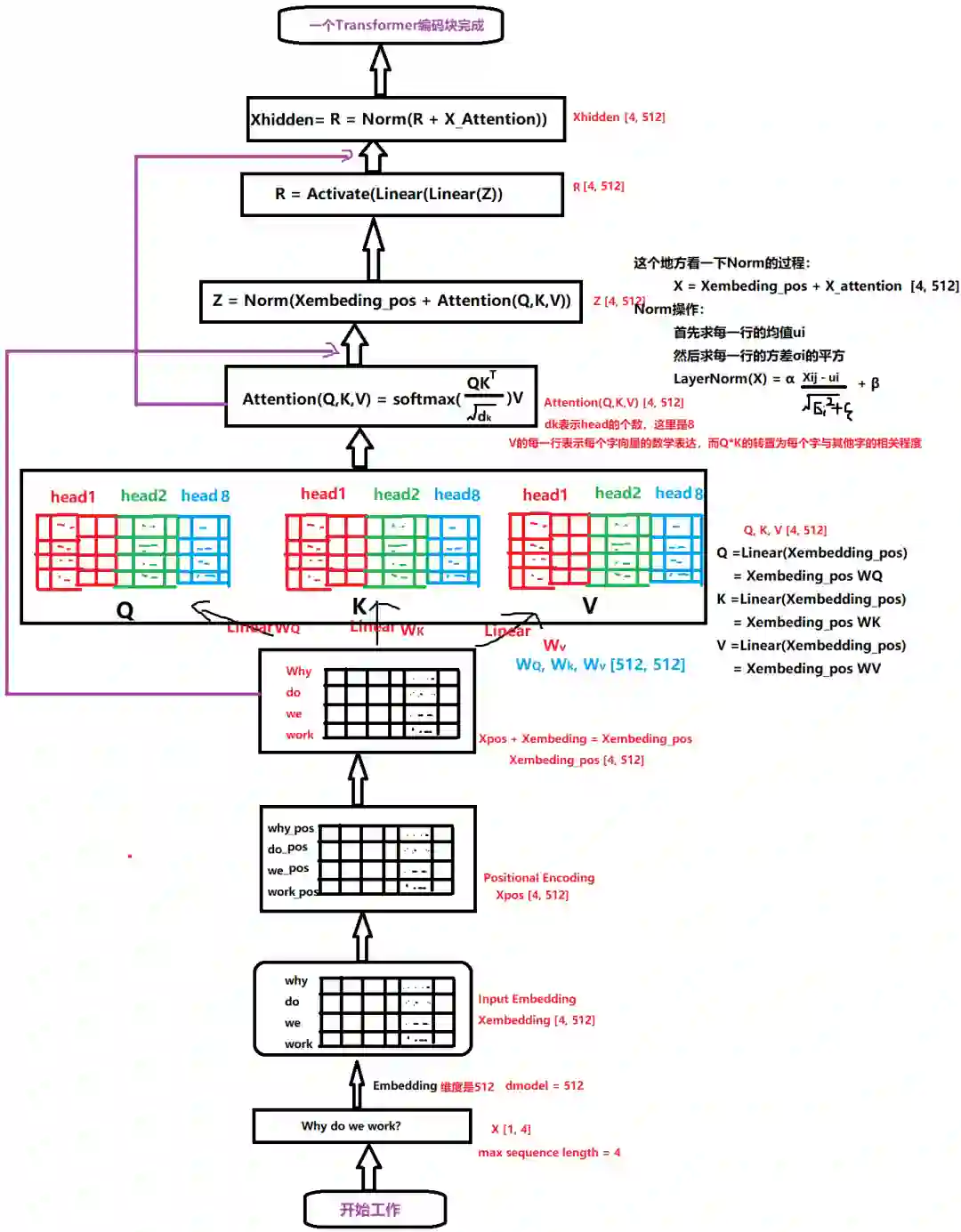
下面再说两个细节就可以把编码器的部分结束了
-
第一个细节就是上面只是展示了一句话经过一个Transformer编码块之后的状态和维度,但我们实际工作中,不会只有一句话和一个Transform编码块,所以对于输入来的维度一般是[batch_size, seq_len, embedding_dim], 而编码块的个数一般也是多个,不过每一个的工作过程和上面一致,无非就是第一块的输出作为第二块的输入,然后再操作。 -
Attention Mask的问题, 因为如果有多句话的时候,句子都不一定一样长,而我们的seqlen肯定是以最长的那个为标准,不够长的句子一般用0来补充到最大长度,这个过程叫做padding。 但这时在进行 的时候就会产生问题, 回顾 函数 , 是1, 是有值的, 这样的话 中被 的部分就参与了运算, 就等于是让无效的部分参与了运算, 会产生很大隐患, 这时就需要做一个 让这些无效区域不参与运算, 我们一般给无效区域加一个很大的负数的偏置, 也就是:
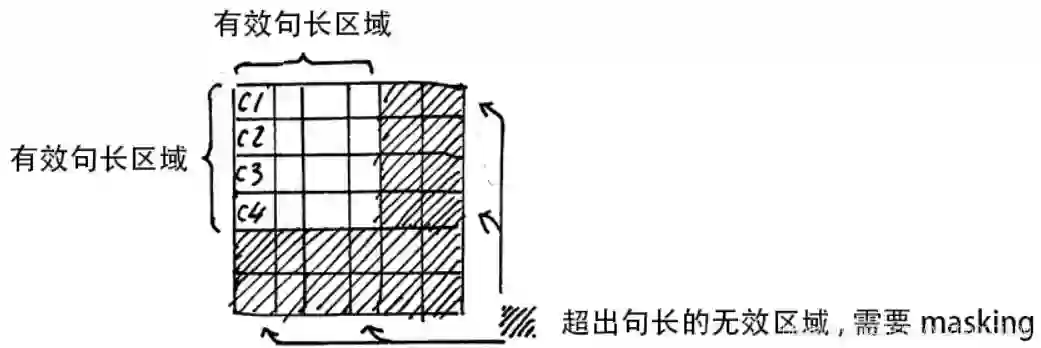 但这时在进行
但这时在进行
经过上式的 我们使无效区域经过 计算之后还几乎为 , 这样就避免了无效区域参与计算.
最后通过上面的梳理,我们解决了Transformer编码器部分,下面看看Transformer Encoder的整体的计算过程:
-
字向量与位置编码:
-
自注意力机制:
-
残差连接与
-
, 其实就是两层线性映射并用激活函数激活, 比如说 :
-
重复3.:
-
这样一个Transformer编码块就执行完了, 得到了X_hidden之后,就可以作为下一个Transformer编码块的输入,然后重复2-5执行,直到Nx个编码块。
好了,编码器部分结束,下面进入解码器部分:
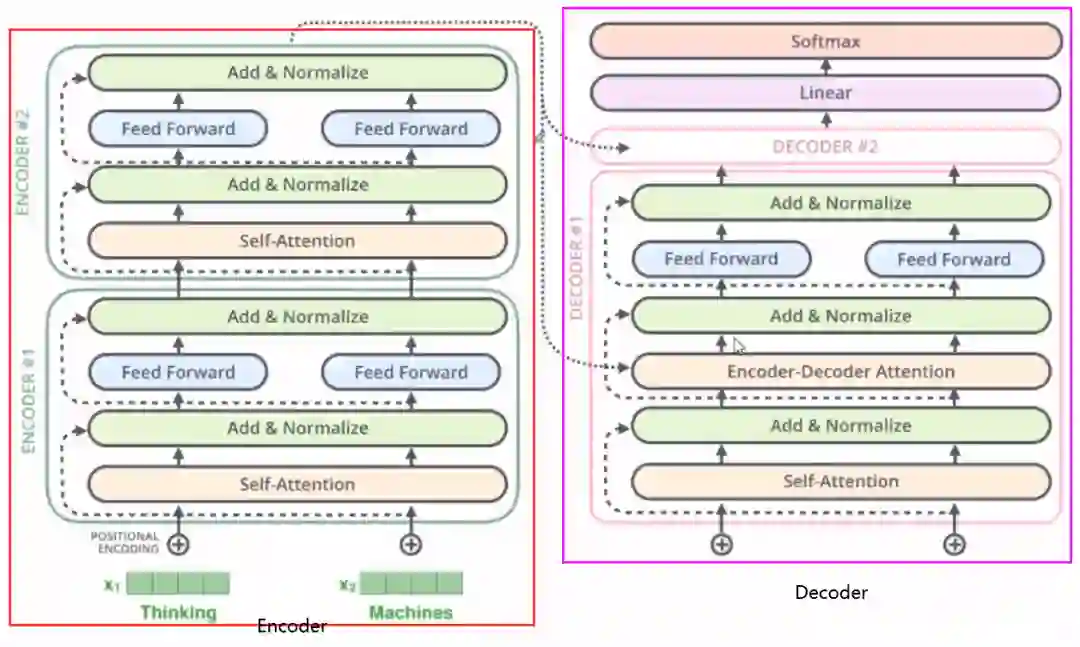
3.2 解码器部分的工作细节
上面我们说完了编码器,看上面这张图,我们发现编码器和解码器其实差不多,只不过解码器部分多了一个Encoder-Decoder Attention, 知道编码器是怎么工作的,也基本会解码器了,但是还是来看几个细节。
编码器通过处理输入序列开启工作。顶端编码器的输出之后会变转化为一个包含向量K(键向量)和V(值向量)的注意力向量集(也就是编码器最终输出的那个从多角度集自身与其他各个字关系的矩阵,比如记为M)。这些向量将被每个解码器用于自身的“编码-解码注意力层”,而这些层可以帮助解码器关注输入序列哪些位置合适。
在完成编码阶段后,则开始解码阶段。解码阶段的每个步骤都会输出一个输出序列(在这个例子里,是英语翻译的句子)的元素(先输出为,为落下去,输出什, 什落下去输出么)
接下来的步骤重复了这个过程,直到到达一个特殊的终止符号,它表示transformer的解码器已经完成了它的输出。每个步骤的输出在下一个时间步被提供给底端解码器,并且就像编码器之前做的那样,这些解码器会输出它们的解码结果 。另外,就像我们对编码器的输入所做的那样,我们会嵌入并添加位置编码给那些解码器,来表示每个单词的位置。
而那些解码器中的自注意力层表现的模式与编码器不同:在解码器中,自注意力层只被允许处理输出序列中更靠前的那些位置。在softmax步骤前,它会把后面的位置给隐去(把它们设为-inf)。
这个“编码-解码注意力层”工作方式基本就像多头自注意力层一样,只不过它是通过在它下面的层来创造查询矩阵,并且从编码器的输出中取得键/值矩阵。这个地方简单说一下细节
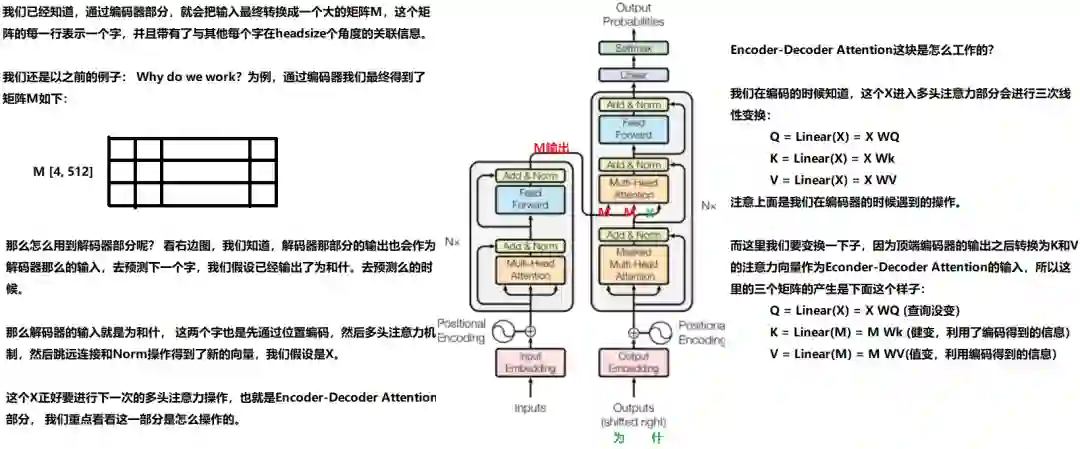
3.3 最终的线性变换和softmax层
解码组件最后会输出一个实数向量。我们如何把浮点数变成一个单词?这便是线性变换层要做的工作,它之后就是Softmax层。
线性变换层是一个简单的全连接神经网络,它可以把解码组件产生的向量投射到一个比它大得多的、被称作对数几率(logits)的向量里。
不妨假设我们的模型从训练集中学习一万个不同的英语单词(我们模型的“输出词表”)。因此对数几率向量为一万个单元格长度的向量——每个单元格对应某一个单词的分数。
接下来的Softmax 层便会把那些分数变成概率(都为正数、上限1.0)。概率最高的单元格被选中,并且它对应的单词被作为这个时间步的输出。
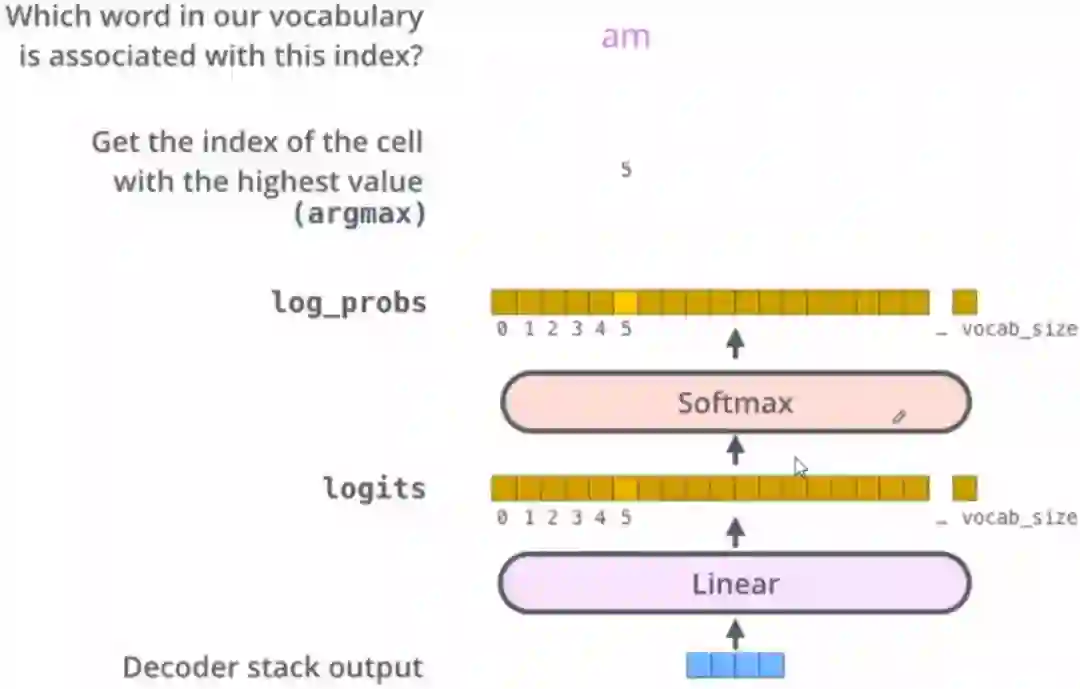
这张图片从底部以解码器组件产生的输出向量开始。之后它会转化出一个输出单词。
4. Training
我们已经过了一遍完整的transformer的前向传播过程,那我们就可以直观感受一下它的训练过程。
在训练过程中,一个未经训练的模型会通过一个完全一样的前向传播。但因为我们用有标记的训练集来训练它,所以我们可以用它的输出去与真实的输出做比较。
为了把这个流程可视化,不妨假设我们的输出词汇仅仅包含六个单词:“a”, “am”, “i”, “thanks”, “student”以及 “”(end of sentence的缩写形式)。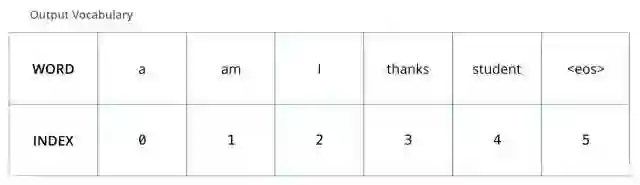
一旦我们定义了我们的输出词表,我们可以使用一个相同宽度的向量来表示我们词汇表中的每一个单词。这也被认为是一个one-hot 编码。所以,我们可以用下面这个向量来表示单词“am”:
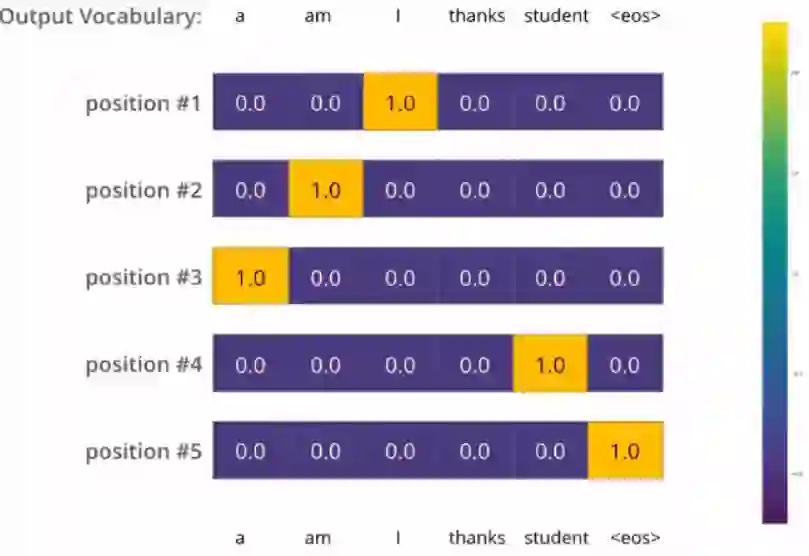
4.1 损失函数
那么我们的损失函数是什么呢?这里我们使用的是交叉熵损失函数因为模型的参数(权重)都被随机的生成,(未经训练的)模型产生的概率分布在每个单元格/单词里都赋予了随机的数值。我们可以用真实的输出来比较它,然后用反向传播算法来略微调整所有模型的权重,生成更接近结果的输出。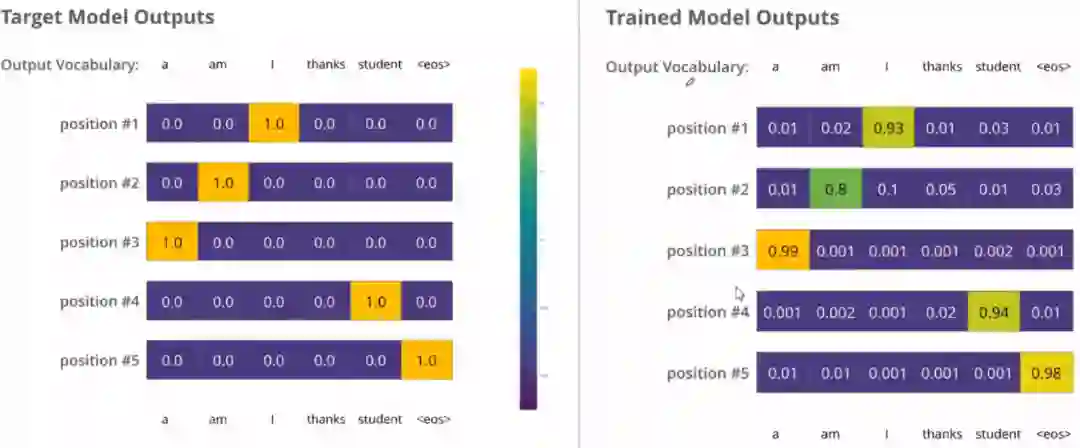
4.2 训练小技巧
-
这个是什么意思呢? 就是我们准备我们的真实标签的时候,最好也不要完全标成非0即1的这种情况,而是用一种概率的方式标记我们的答案。这是一种规范化的方式。
比如上面我们的答案我们最好不要标成这种形式,而是比如position #1这个,我们虽然想让机器输出I 我们可以I对应的位置是0.9, 剩下的0.1其他五个地方平分,也就是 position #1 0.02 0.02 0.9 0.02 0.02 0.02
-
Noam Learning Rate Schedule这是一种非常重要的方式,如果不用这种学习率的话,可能训练不出一个好的Transformer。
简单的说,就是先让学习率线性增长到某个最大的值,然后再按指数的方式衰减。
 这个是什么意思呢? 就是我们准备我们的真实标签的时候,最好也不要完全标成非0即1的这种情况,而是用一种概率的方式标记我们的答案。这是一种规范化的方式。
这个是什么意思呢? 就是我们准备我们的真实标签的时候,最好也不要完全标成非0即1的这种情况,而是用一种概率的方式标记我们的答案。这是一种规范化的方式。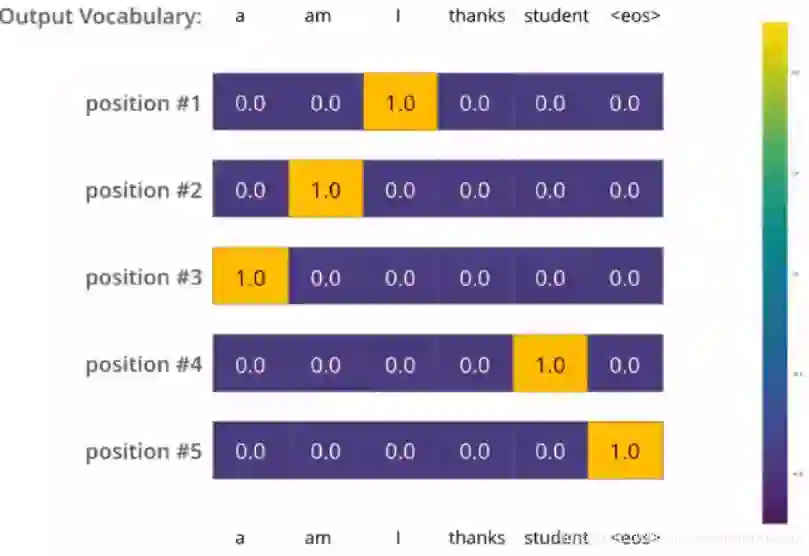 我们最好不要标成这种形式,而是比如position #1这个,我们虽然想让机器输出I 我们可以I对应的位置是0.9, 剩下的0.1其他五个地方平分,也就是 position #1 0.02 0.02 0.9 0.02 0.02 0.02
我们最好不要标成这种形式,而是比如position #1这个,我们虽然想让机器输出I 我们可以I对应的位置是0.9, 剩下的0.1其他五个地方平分,也就是 position #1 0.02 0.02 0.9 0.02 0.02 0.02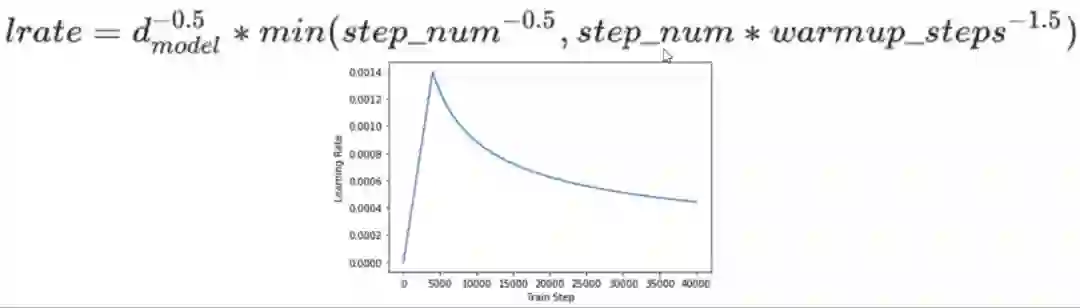 简单的说,就是先让学习率线性增长到某个最大的值,然后再按指数的方式衰减。
简单的说,就是先让学习率线性增长到某个最大的值,然后再按指数的方式衰减。5. Conclusion
这篇文章最经典的核心就是transformer结构,这种结构完全依赖于注意力机制,取代了基于Encoder-Decoder的循环层,并且引入了位置嵌入,Multi-Head Attention机制。
下面分析一下Transformer的特性:
-
优点:(1) 每一层的计算复杂度比较低
(2) 比较利于并行计算
(3) 模型可解释性比较高(不同单词之间的相关性有多大) -
缺点:(1) 有些RNN轻易可以解决的问题Transformer没做到,比如复制string,或者推理碰到的sequence长度比训练时更长(因为碰到了没见到过的position embedding) (2) RNN图灵完备,Transformer不是。图灵完备的系统理论是可以近似任意Turing计算机可以解决的算法。
代码实现:
-
https://nlp.seas.harvard.edu/2018/04/03/attention.html -
https://www.tensorflow.org/tutorials/text/transformer
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方"AINLP",进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心

推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏



