R语言时间序列分析

郑连虎,在数学学院取得理学学位的文科生,中国人民大学硕博连读生在读,山东大学管理学学士、理学学士
个人公众号:阿虎定量笔记
方法简介
时间序列是按时间顺序的一组数字序列。时间序列分析(time series analysis)就是利用这组数列,基于随机过程理论和数理统计学方法加以处理,以预测未来事物的发展。时间序列分析是定量预测方法之一,它的基本原理:一是承认事物发展的延续性。应用过去数据,就能推测事物的发展趋势;二是考虑到事物发展的随机性。任何事物发展都可能受偶然因素影响,为此要利用统计分析中加权平均法对历史数据进行处理。时间序列预测一般反映三种实际变化规律:趋势变化、周期性变化、随机性变化。
时间序列分析一般采用曲线拟合和参数估计(如非线性最小二乘法)来建立数学模型,一个时间序列通常由4种要素组成:趋势、季节变动、循环波动和不规则波动。
- 趋势:是时间序列在长时期内呈现出来的持续向上或持续向下的变动;
- 季节变动:是时间序列在一年内重复出现的周期性波动。它是诸如气候条件、生产条件、节假日或人们的风俗习惯等各种因素影响的结果;
- 循环波动:是时间序列呈现出的非固定长度的周期性变动。循环波动的周期可能会持续一段时间,但与趋势不同,它不是朝着单一方向的持续变动,而是涨落相同的交替波动;
- 不规则波动:是时间序列中除去趋势、季节变动和周期波动之后的随机波动。不规则波动通常总是夹杂在时间序列中,致使时间序列产生一种波浪形或震荡式的变动。只含有随机波动的序列也称为平稳序列;
建模步骤
- 用观测、调查、统计、抽样等方法取得被观测系统时间序列动态数据;
- 根据动态数据作相关图,进行相关分析,求自相关函数。相关图能显示出变化的趋势和周期,并能发现跳点和拐点。跳点是指与其他数据不一致的观测值。如果跳点是正确的观测值,在建模时应考虑进去,如果是反常现象,则应把跳点调整到期望值。拐点则是指时间序列从上升趋势突然变为下降趋势的点。如果存在拐点,则在建模时必须用不同的模型去分段拟合该时间序列,例如采用门限回归模型;
- 辨识合适的随机模型,进行曲线拟合,即用通用随机模型去拟合时间序列的观测数据。对于短的或简单的时间序列,可用趋势模型和季节模型加上误差来进行拟合。对于平稳时间序列,可用通用ARIMA模型(自回归移动平均模型)及其特殊情况的自回归模型、移动平均模型或组合ARMA模型等来进行拟合。当观测值多于50个时一般都采用ARMA模型。对于非平稳时间序列则要先将观测到的时间序列进行差分运算,化为平稳时间序列,再用适当模型去拟合这个差分序列;
预测算法
给定一个时间序列,如何预测下一个值?统计学上有以下几种思路:
- mean(平均值):未来值是历史值的平均;
- exponential smoothing(指数衰减):当去平均值得时候,每个历史点的权值可以不一样;最自然的就是越近的点赋予越大的权重;
- snaive:假设已知数据的周期,那么就用前一个周期对应的时刻作为下一个周期对应时刻的预测值;
- drift(飘移):用最后一个点的值加上数据的平均趋势;
- Holt-Winters(三阶指数平滑):把数据分解成三个成分:平均水平(level),趋势(trend)和周期性(seasonality);
- ARIMA(自回归移动平均模型):模型的形式为 ARIMA(p,d,q),其中p为自回归项,q为移动平均项数,d为时间序列成平稳所做的差分次数;
数据来源
小编最近发现一个很好用的数据库:Data Market;这个数据库包含许多类型的数据,其中就包括时间序列数据库(The Time Series DataLibrary, TSDL);该数据库由澳大利亚Monash University的Rob Hyndman教授创建,网址为
https://datamarket.com/data/list/?q=provider:tsdl
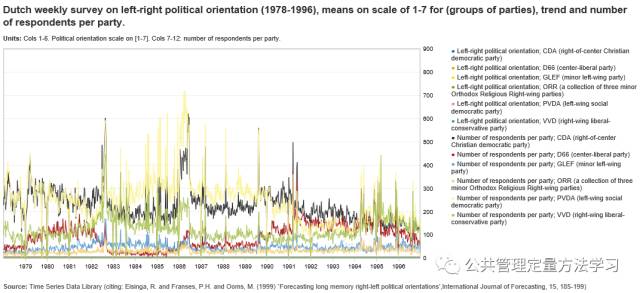
该数据库提供5种格式的数据下载:Excel (.xls)/(.xlsx)、CSV (,)/(;)以及TSV (\t);小编选用TSDL中的“Dutchweekly survey on left-right political orientation (1978-1996)(左右政治倾向的每周调查)”数据来演示时间序列分析的R语言实现过程;该数据的受访者针对荷兰6个主要政治团体:CDA(中央基督教民主党派)、D66(中央自由党)、GLEF(小左派)、ORR(三个小正统宗教右翼派对的集合)、PVDA(左翼社会民主党派)、VVD(右翼自由保守党),以1-7分计分的形式,表达自己的“左-右”政治倾向;为方便演示,本期仅使用CDA部分的数据。
R语言实现
时间序列分析的R语言过程,可以分为两个主要部分:数据预处理(定义日期、平稳性判断、季节分解)和趋势预测(模型选择);
- 读入数据
我这里的数据存在D盘,请注意文件读取路径:
orientation = read.csv('D:/weekly_survey.csv',header=F,sep='')
o <-unlist(orientation)- 定义日期并绘制时间序列图
我这里数据是每周调查的数据,一年有53个星期,故frequency=53;如果是月度数据,则frequency=12;如果是季度数据,则frequency=4:
ots<-ts(o,frequency=53,start=1978)
plot.ts(ots)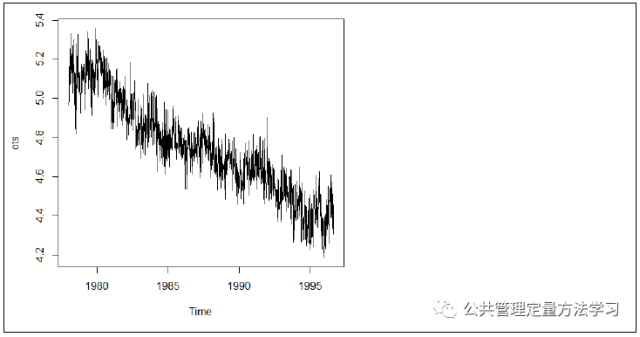
- 季节分解
时间序列数据分为非季节性数据和季节性数据:一个非季节性时间序列包含一个趋势部分和一个不规则部分,分解时间序列就是估计趋势的和不规则的这两个部分;一个季节性时间序列包含一个趋势部分、一个季节性部分和一个不规则部分,分解时间序列就意味着要把时间序列分解为这三个部分。下图自上而下展现了原始的时间序列图、估计出的趋势部分、估计出的季节性部分、估计得不规则部分。季节性变动指由于季节因素导致的时间序列有规则变动;无季节变动的数据不需要这一步处理:
ots_components <- decompose(ots)
plot(ots_components)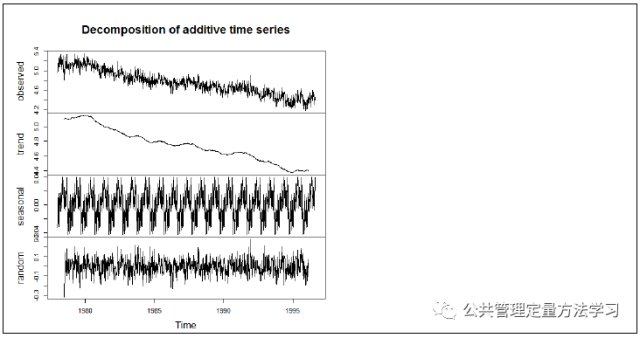
- 平稳性判断
平稳性判断主要用到两个工具:自相关函数(auto correlation function, ACF)和偏自相关函数(patialauto correlation function, PACF);对于non-stationary的数据,ACF图不会趋向于0,或者趋向0的速度很慢;对于含有趋势的非平稳时间序列,通常可以通过引入ARIMA模型对其变换:ARIMA模型对于非平稳时间序列采用的方法是,运用差分运算提取趋势信息,最终把序列变为平稳序列。下面的四张图从左到右、自上而下分别对应原始数据的自相关函数、原始数据的偏自相关函数、原始数据一阶差分后的自相关函数、原始数据去除周期性后一阶差分的自相关函数:
acf(ots)
pacf(ots)
acf(diff(ots,lag=1))
acf(diff(diff(ots,lag=7)))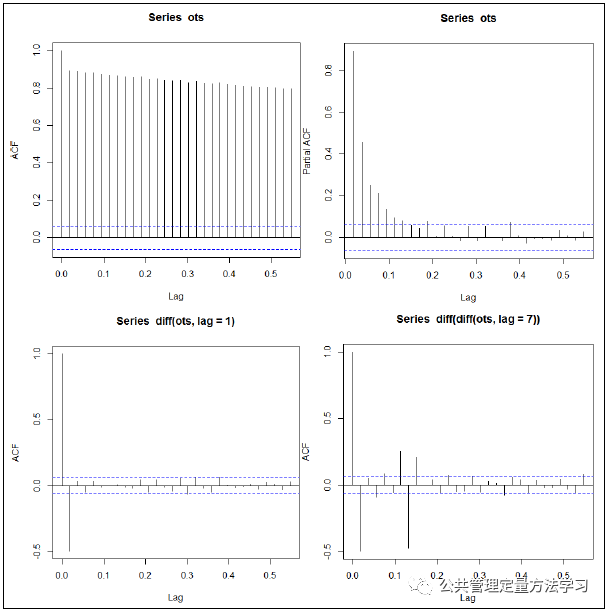
- 安装并调用forecast包
install.packages("forecast")
library(forecast) - 趋势预测
auto.arima函数会自动挑选一个最恰当的算法去分析数据;下图中蓝线是受访者政治倾向的预测,深灰色阴影区域为80%的预测区间,浅灰色阴影区域为95%的预测区间;电脑运行这段代码时速度可能会慢,请耐心等待:
ots_forecast<- auto.arima(ots)
ots_arima <- forecast(ots_forecast,h=30)
plot (ots_arima)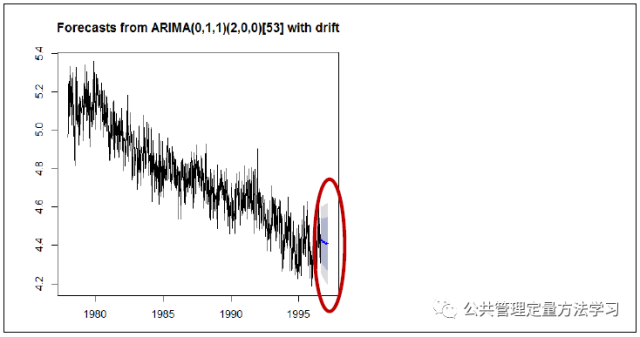
本期参考文献
[1] 王振龙,胡永宏. 应用时间序列分析. 科学出版社, 2012,p1-27;
[2] Eisinga, R. and Franses, P.H. and Ooms, M. Forecasting longmemory right-left political orientations’. International Journal of Forecasting.1999, p185-199;

公众号后台回复关键字即可学习
回复 爬虫 爬虫三大案例实战
回复 Python 1小时破冰入门回复 数据挖掘 R语言入门及数据挖掘
回复 人工智能 三个月入门人工智能
回复 数据分析师 数据分析师成长之路
回复 机器学习 机器学习的商业应用
回复 数据科学 数据科学实战
回复 常用算法 常用数据挖掘算法