机器学习开放课程:九、基于Python分析真实手游时序数据
编者按:Zeptolab数据科学家Dmitriy Sergeev介绍了分析和预测时序数据的主要方法。

大家好!
这次的开放机器学习课程的内容是时序数据。
我们将查看如何使用Python处理时序数据,哪些方法和模型可以用来预测;什么是双指数平滑和三指数平滑;如果平稳(stationarity)不是你的菜,该怎么办;如何创建SARIMA并且活下来;如何使用XGBoost做出预测。所有这些都将应用于(严酷的)真实世界例子。
概览
导言
基本定义
量化指标
平移、平滑、评估
滚动窗口估计
指数平滑,Holt-Winters模型
时序交叉验证,参数选择
计量经济学方法
平稳,单位根
摆脱不平稳性
SARIMA的直觉和建模
时序数据上的线性(以及不那么线性)模型
特征提取
线性模型,特征重要性
正则化,特征选取
XGBoost
相关资源
导言
在我的工作中,我几乎每天都会碰到和时序有关的任务。最频繁的问题是——明天/下一周/下个月/等等,我们的指标将是什么样——有多少玩家会安装应用,他们的在线时长会是多少,他们会进行多少次操作,取决于预测所需的质量,预测周期的长度,以及时刻,我们需要选择特征,调整参数,以取得所需结果。
基本定义
时序的简单定义:
时序——一系列以时间顺序为索引(或列出、绘出)的数据点。
因此,数据以相对确定的时刻组织。所以,和随机样本相比,可能包含我们将尝试提取的额外信息。
让我们导入一些库。首先我们需要statsmodels库,它包含了一大堆统计学建模函数,包括时序。对不得不迁移到Python的R粉来说,绝对会感到statsmodels很熟悉,因为它支持类似Wage ~ Age + Education这样的模型定义。
import numpy as np # 向量和矩阵
import pandas as pd # 表格和数据处理
import matplotlib.pyplot as plt # 绘图
import seaborn as sns # 更多绘图功能
from dateutil.relativedelta import relativedelta # 处理不同格式的时间日期
from scipy.optimize import minimize # 最小化函数
import statsmodels.formula.api as smf # 统计学和计量经济学
import statsmodels.tsa.api as smt
import statsmodels.api as sm
import scipy.stats as scs
from itertools import product # 一些有用的函数
from tqdm import tqdm_notebook
import warnings # 勿扰模式
warnings.filterwarnings('ignore')
%matplotlib inline
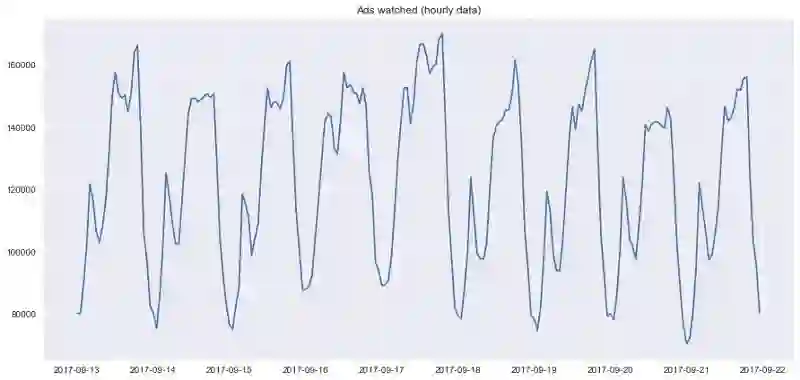
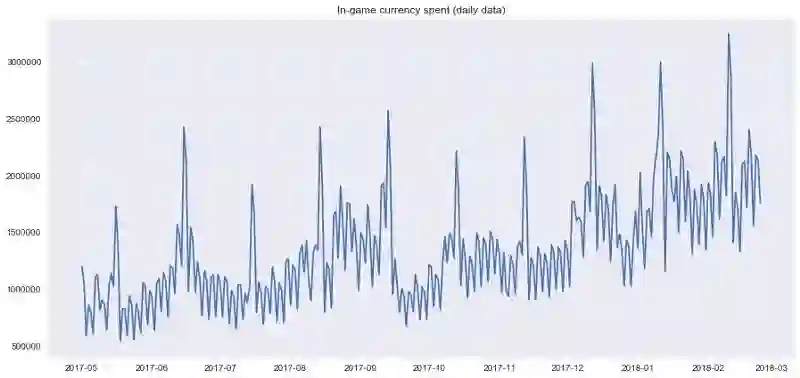
作为例子,让我们使用一些真实的手游数据,玩家每小时观看的广告,以及每天游戏币的花费:
ads = pd.read_csv('../../data/ads.csv', index_col=['Time'], parse_dates=['Time'])
currency = pd.read_csv('../../data/currency.csv', index_col=['Time'], parse_dates=['Time'])
plt.figure(figsize=(15, 7))
plt.plot(ads.Ads)
plt.title('Ads watched (hourly data)')
plt.grid(True)
plt.show()
plt.figure(figsize=(15, 7))
plt.plot(currency.GEMS_GEMS_SPENT)
plt.title('In-game currency spent (daily data)')
plt.grid(True)
plt.show()
预测质量指标
在实际开始预测之前,先让我们理解下如何衡量预测的质量,查看下最常见、使用最广泛的测度:
R2,决定系数(在经济学中,可以理解为模型能够解释的方差比例),(-inf, 1]
sklearn.metrics.r2_score平均绝对误差(Mean Absolute Error),这是一个易于解释的测度,因为它的计量单位和初始序列相同,[0, +inf)
sklearn.metrics.mean_absolute_error中位绝对误差(Median Absolute Error),同样是一个易于解释的测度,对离群值的鲁棒性很好,[0, +inf)
sklearn.metrics.median_absolute_error均方误差(Mean Squared Error),最常用的测度,给较大的错误更高的惩罚,[0, +inf)
sklearn.metrics.mean_squared_error均方对数误差(Mean Squared Logarithmic Error),和MSE差不多,只不过先对序列取对数,因此能够照顾到较小的错误,通常用于具有指数趋势的数据,[0, +inf)
sklearn.metrics.mean_squared_log_error平均绝对百分误差(Mean Absolute Percentage Error),类似MAE不过基于百分比——当你需要向管理层解释模型的质量时很方便——[0, +inf),sklearn中没有实现。
# 引入上面提到的所有测度
from sklearn.metrics import r2_score, median_absolute_error, mean_absolute_error
from sklearn.metrics import median_absolute_error, mean_squared_error, mean_squared_log_error
# 自行实现sklearn没有提供的平均绝对百分误差很容易
def mean_absolute_percentage_error(y_true, y_pred):
return np.mean(np.abs((y_true - y_pred) / y_true)) * 100
棒极了,现在我们知道如何测量预测的质量了,可以使用哪些测度,以及如何向老板翻译结果。剩下的就是创建模型了。
平移、平滑、评估
让我们从一个朴素的假设开始——“明天会和今天一样”,但是我们并不使用类似y^t=y(t-1)这样的模型(这其实是一个适用于任意时序预测问题的很好的基线,有时任何模型都无法战胜这一模型),相反,我们将假定变量未来的值取决于前n个值的平均,所以我们将使用的是移动平均(moving average)。
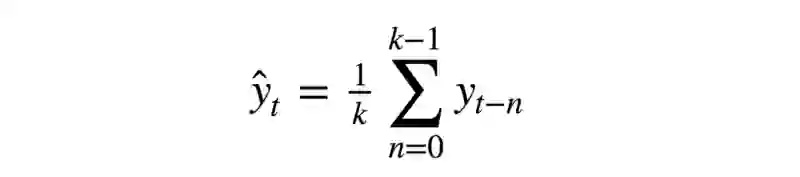
def moving_average(series, n):
"""
计算前n项观测的平均数
"""
return np.average(series[-n:])
# 根据前24小时的数据预测
moving_average(ads, 24)
结果:116805.0
不幸的是这样我们无法做出长期预测——为了预测下一步的数据我们需要实际观测的之前的数据。不过移动平均还有一种用途——平滑原时序以显示趋势。pandas提供了实现DataFrame.rolling(window).mean()。窗口越宽,趋势就越平滑。遇到噪声很大的数据时(财经数据十分常见),这一过程有助于侦测常见模式。
def plotMovingAverage(series, window, plot_intervals=False, scale=1.96, plot_anomalies=False):
"""
series - 时序dateframe
window - 滑窗大小
plot_intervals - 显示置信区间
plot_anomalies - 显示异常值
"""
rolling_mean = series.rolling(window=window).mean()
plt.figure(figsize=(15,5))
plt.title("Moving average\n window size = {}".format(window))
plt.plot(rolling_mean, "g", label="Rolling mean trend")
# 绘制平滑后的数据的置信区间
if plot_intervals:
mae = mean_absolute_error(series[window:], rolling_mean[window:])
deviation = np.std(series[window:] - rolling_mean[window:])
lower_bond = rolling_mean - (mae + scale * deviation)
upper_bond = rolling_mean + (mae + scale * deviation)
plt.plot(upper_bond, "r--", label="Upper Bond / Lower Bond")
plt.plot(lower_bond, "r--")
# 得到区间后,找出异常值
if plot_anomalies:
anomalies = pd.DataFrame(index=series.index, columns=series.columns)
anomalies[series<lower_bond] = series[series<lower_bond]
anomalies[series>upper_bond] = series[series>upper_bond]
plt.plot(anomalies, "ro", markersize=10)
plt.plot(series[window:], label="Actual values")
plt.legend(loc="upper left")
plt.grid(True)
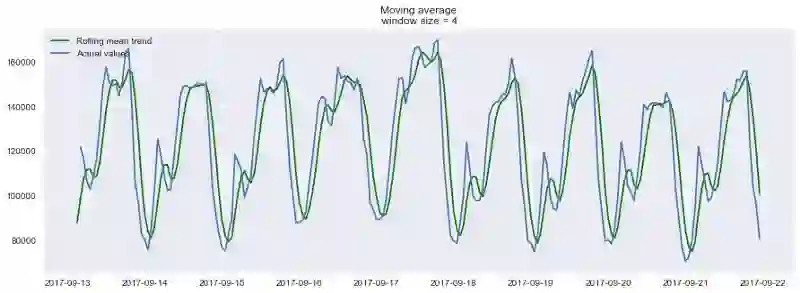
平滑(窗口大小为4小时):
plotMovingAverage(ads, 4)
平滑(窗口大小为12小时):
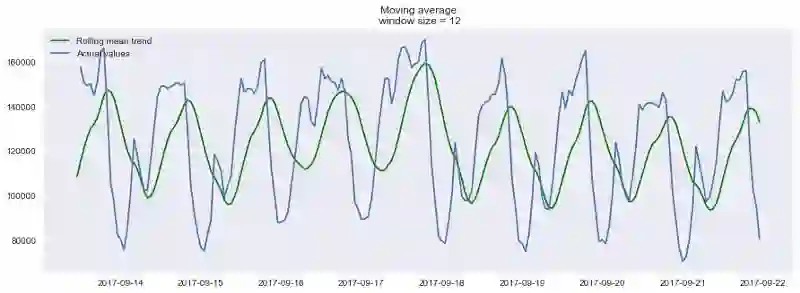
plotMovingAverage(ads, 12)
平滑(窗口大小为24小时):
plotMovingAverage(ads, 24)
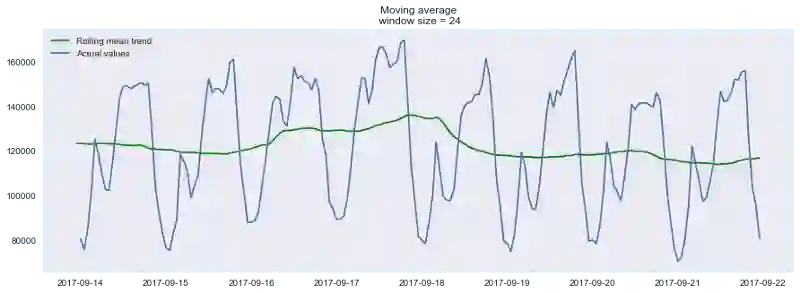
如你所见,在小时数据上按日平滑让我们可以清楚地看到浏览广告的趋势。周末数值较高(周末是娱乐时间),工作日一般数值较低。
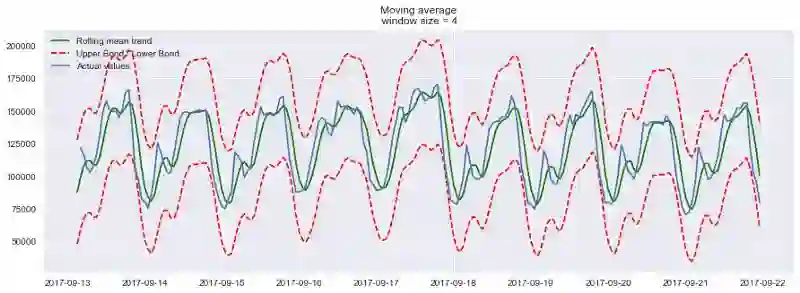
我们可以同时绘制平滑值的置信区间:
plotMovingAverage(ads, 4, plot_intervals=True)
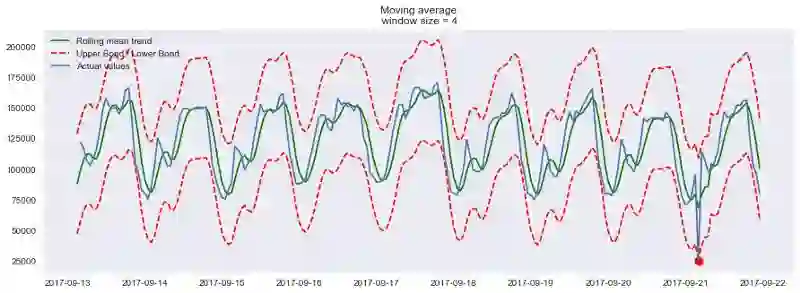
现在让我们在移动平均的帮助下创建一个简单的异常检测系统。不幸的是,在这段时序数据中,一切都比较正常,所以让我们故意弄出点异常来:
ads_anomaly = ads.copy()
# 例如广告浏览量下降了20%
ads_anomaly.iloc[-20] = ads_anomaly.iloc[-20] * 0.2
让我们看看这个简单的方法能不能捕获异常:
plotMovingAverage(ads_anomaly, 4, plot_intervals=True, plot_anomalies=True)
酷!按周平滑呢?
plotMovingAverage(currency, 7, plot_intervals=True, plot_anomalies=True)
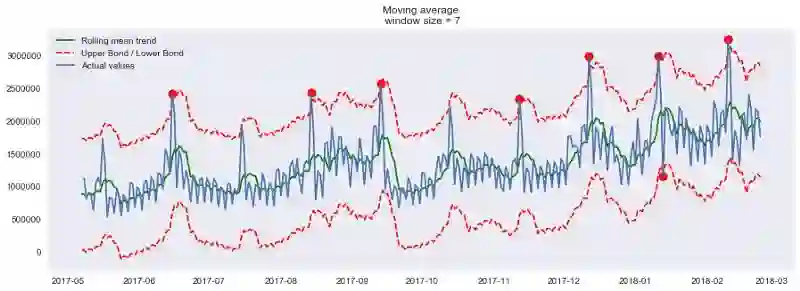
不好!这是简单方法的缺陷——它没能捕捉月度数据的季节性,几乎将所有30天出现一次的峰值当作异常值。如果你不想有这么多虚假警报,最好考虑更复杂的模型。
顺便提下移动平均的一个简单修正——加权平均(weighted average)。其中不同的观测具有不同的权重,所有权重之和为一。通常最近的观测具有较高的权重。
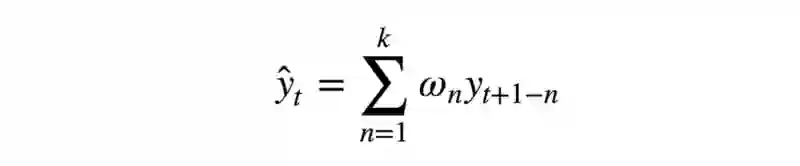
def weighted_average(series, weights):
result = 0.0
weights.reverse()
for n in range(len(weights)):
result += series.iloc[-n-1] * weights[n]
return float(result)
weighted_average(ads, [0.6, 0.3, 0.1])
结果:98423.0
指数平滑
那么,如果我们不只加权最近的几项观测,而是加权全部现有的观测,但对历史数据的权重应用指数下降呢?
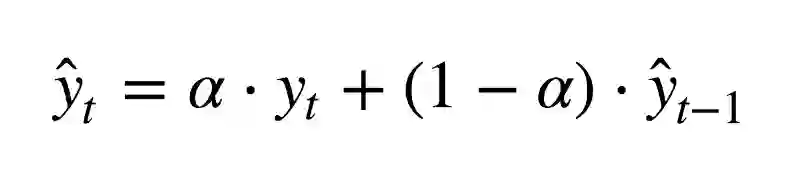
这一模型的值是当前观测和历史观测的加权平均。权重α称为平滑因子,定义多快“遗忘”之前的观测。α越小,之前的值的影响就越大,序列就越平滑。
指数隐藏在函数的递归调用之中,y^t-1本身包含(1-α)y^t-2,以此类推,直到序列的开始。
def exponential_smoothing(series, alpha):
"""
series - 时序数据集
alpha - 浮点数,范围[0.0, 1.0],平滑参数
"""
result = [series[0]] # 第一项和序列第一项相同
for n in range(1, len(series)):
result.append(alpha * series[n] + (1 - alpha) * result[n-1])
return result
def plotExponentialSmoothing(series, alphas):
with plt.style.context('seaborn-white'):
plt.figure(figsize=(15, 7))
for alpha in alphas:
plt.plot(exponential_smoothing(series, alpha), label="Alpha {}".format(alpha))
plt.plot(series.values, "c", label = "Actual")
plt.legend(loc="best")
plt.axis('tight')
plt.title("Exponential Smoothing")
plt.grid(True);
plotExponentialSmoothing(ads.Ads, [0.3, 0.05])
plotExponentialSmoothing(currency.GEMS_GEMS_SPENT, [0.3, 0.05])
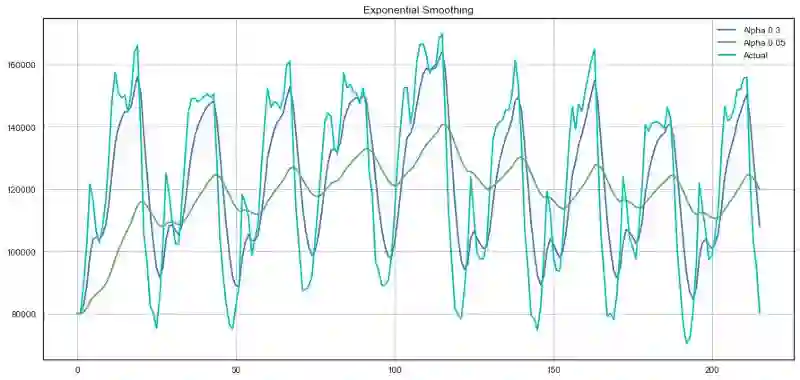
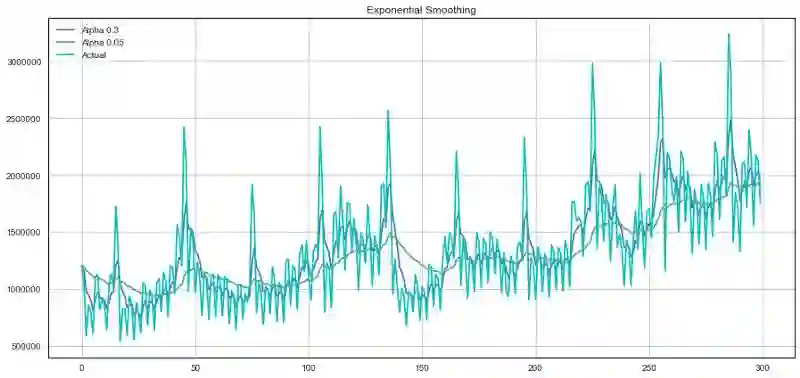
双指数平滑
目前我们的方法能给出的只是单个未来数据点的预测(以及一些良好的平滑),这很酷,但还不够,所以让我们扩展下指数平滑以预测两个未来数据点(当然,同样经过平滑)。
序列分解应该能帮到我们——我们得到两个分量:截距(也叫水平)l和趋势(也叫斜率)b。我们使用之前提到的方法学习预测截距(或期望的序列值),并将同样的指数平滑应用于趋势(假定时序未来改变的方向取决于之前的加权变化)。
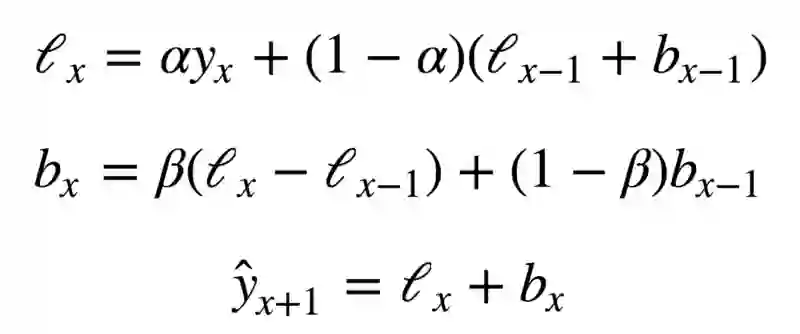
上面的第一个函数描述截距,和之前一样,它取决于序列的当前值,只不过第二项现在分成水平和趋势两个分量。第二个函数描述趋势,它取决于当前一步的水平变动,以及之前的趋势值。这里β系数是指数平滑的权重。最后的预测为模型对截距和趋势的预测之和。
def double_exponential_smoothing(series, alpha, beta):
result = [series[0]]
for n in range(1, len(series)+1):
if n == 1:
level, trend = series[0], series[1] - series[0]
if n >= len(series):
value = result[-1]
else:
value = series[n]
last_level, level = level, alpha*value + (1-alpha)*(level+trend)
trend = beta*(level-last_level) + (1-beta)*trend
result.append(level+trend)
return result
def plotDoubleExponentialSmoothing(series, alphas, betas):
with plt.style.context('seaborn-white'):
plt.figure(figsize=(20, 8))
for alpha in alphas:
for beta in betas:
plt.plot(double_exponential_smoothing(series, alpha, beta), label="Alpha {}, beta {}".format(alpha, beta))
plt.plot(series.values, label = "Actual")
plt.legend(loc="best")
plt.axis('tight')
plt.title("Double Exponential Smoothing")
plt.grid(True)
plotDoubleExponentialSmoothing(ads.Ads, alphas=[0.9, 0.02], betas=[0.9, 0.02])
plotDoubleExponentialSmoothing(currency.GEMS_GEMS_SPENT, alphas=[0.9, 0.02], betas=[0.9, 0.02])
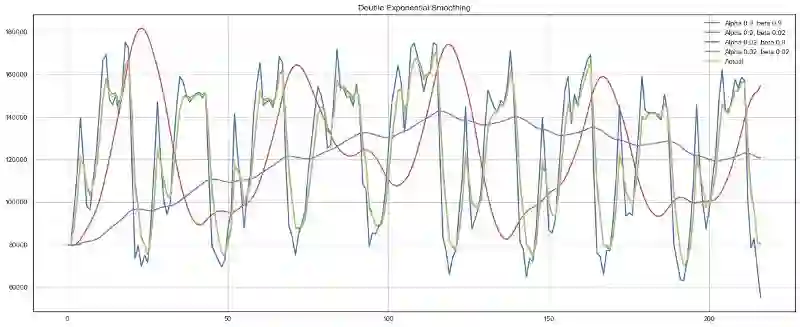
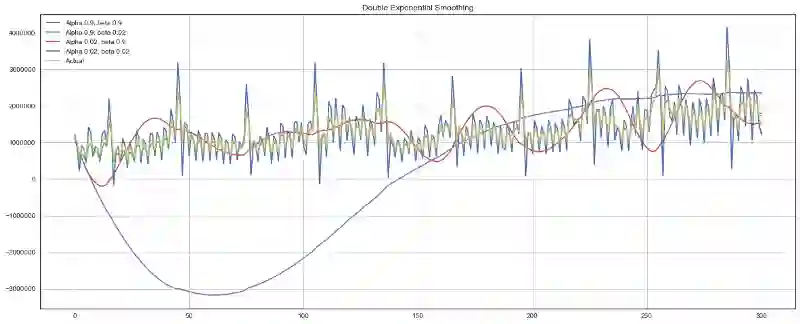
现在我们有两个可供调节的参数——α和β。前者根据趋势平滑序列,后者平滑趋势本身。这两个参数越大,最新的观测的权重就越高,建模的序列就越不平滑。这两个参数的组合可能产生非常怪异的结果,特别是手工设置时。我们很快将查看自动选择参数的方法,在介绍三次指数平滑之后。
Holt-Winters模型
好哇!让我们看下一个指数平滑的变体,这次是三次指数平滑。
这一方法的思路是我们加入第三个分量——季节性。这意味着,如果我们的时序不具有季节性(我们之前的例子就不具季节性),我们就不应该使用这一方法。模型中的季节分量将根据季节长度解释截距和趋势上的重复波动,季节长度也就是波动重复的周期。季节中的每项观测有一个单独的分量,例如,如果季节长度为7(按周计的季节),我们将有7个季节分量,每个季节分量对应一天。
现在我们得到了一个新系统:
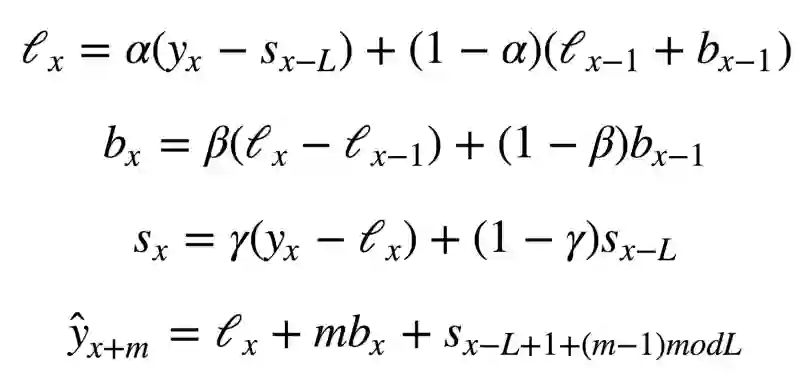
现在,截断取决于时序的当前值减去相应的季节分量,趋势没有变动,季节分量取决于时序的当前值减去截断,以及前一个季节分量的值。注意分量在所有现有的季节上平滑,例如,周一分量会和其他所有周一平均。关于如何计算平均以及趋势分量和季节分量的初始逼近,可以参考工程统计手册6.4.3.5:
https://www.itl.nist.gov/div898/handbook/pmc/section4/pmc435.htm
具备季节分量后,我们可以预测任意m步未来,而不是一步或两步,非常鼓舞人心。
下面是三次指数平滑模型的代码,也称Holt-Winters模型,得名于发明人的姓氏——Charles Holt和他的学生Peter Winters。此外,模型中还引入了Brutlag方法,以创建置信区间:
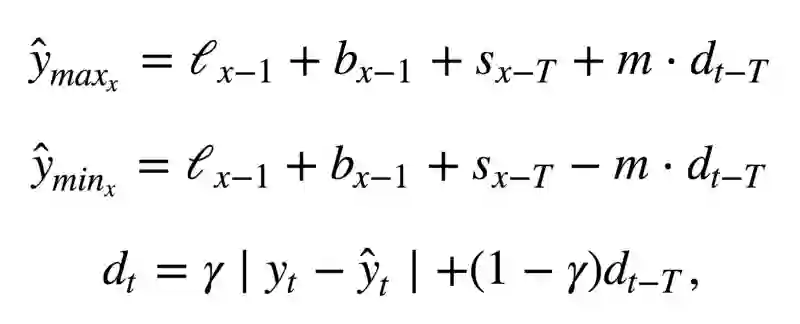
其中T为季节的长度,d为预测偏差。你可以参考以下论文了解这一方法的更多内容,以及它在时序异常检测中的应用:
https://annals-csis.org/proceedings/2012/pliks/118.pdf
class HoltWinters:
"""
Holt-Winters模型,使用Brutlag方法检测异常
# series - 初始时序
# slen - 季节长度
# alpha, beta, gamma - Holt-Winters模型参数
# n_preds - 预测视野
# scaling_factor - 设置Brutlag方法的置信区间(通常位于2到3之间)
"""
def __init__(self, series, slen, alpha, beta, gamma, n_preds, scaling_factor=1.96):
self.series = series
self.slen = slen
self.alpha = alpha
self.beta = beta
self.gamma = gamma
self.n_preds = n_preds
self.scaling_factor = scaling_factor
def initial_trend(self):
sum = 0.0
for i in range(self.slen):
sum += float(self.series[i+self.slen] - self.series[i]) / self.slen
return sum / self.slen
def initial_seasonal_components(self):
seasonals = {}
season_averages = []
n_seasons = int(len(self.series)/self.slen)
# 计算季节平均
for j in range(n_seasons):
season_averages.append(sum(self.series[self.slen*j:self.slen*j+self.slen])/float(self.slen))
# 计算初始值
for i in range(self.slen):
sum_of_vals_over_avg = 0.0
for j in range(n_seasons):
sum_of_vals_over_avg += self.series[self.slen*j+i]-season_averages[j]
seasonals[i] = sum_of_vals_over_avg/n_seasons
return seasonals
def triple_exponential_smoothing(self):
self.result = []
self.Smooth = []
self.Season = []
self.Trend = []
self.PredictedDeviation = []
self.UpperBond = []
self.LowerBond = []
seasonals = self.initial_seasonal_components()
for i in range(len(self.series)+self.n_preds):
if i == 0: # 成分初始化
smooth = self.series[0]
trend = self.initial_trend()
self.result.append(self.series[0])
self.Smooth.append(smooth)
self.Trend.append(trend)
self.Season.append(seasonals[i%self.slen])
self.PredictedDeviation.append(0)
self.UpperBond.append(self.result[0] +
self.scaling_factor *
self.PredictedDeviation[0])
self.LowerBond.append(self.result[0] -
self.scaling_factor *
self.PredictedDeviation[0])
continue
if i >= len(self.series): # 预测
m = i - len(self.series) + 1
self.result.append((smooth + m*trend) + seasonals[i%self.slen])
# 预测时在每一步增加不确定性
self.PredictedDeviation.append(self.PredictedDeviation[-1]*1.01)
else:
val = self.series[i]
last_smooth, smooth = smooth, self.alpha*(val-seasonals[i%self.slen]) + (1-self.alpha)*(smooth+trend)
trend = self.beta * (smooth-last_smooth) + (1-self.beta)*trend
seasonals[i%self.slen] = self.gamma*(val-smooth) + (1-self.gamma)*seasonals[i%self.slen]
self.result.append(smooth+trend+seasonals[i%self.slen])
# 据Brutlag算法计算偏差
self.PredictedDeviation.append(self.gamma * np.abs(self.series[i] - self.result[i])
+ (1-self.gamma)*self.PredictedDeviation[-1])
self.UpperBond.append(self.result[-1] +
self.scaling_factor *
self.PredictedDeviation[-1])
self.LowerBond.append(self.result[-1] -
self.scaling_factor *
self.PredictedDeviation[-1])
self.Smooth.append(smooth)
self.Trend.append(trend)
self.Season.append(seasonals[i%self.slen])
时序交叉验证
现在我们该兑现之前的承诺,讨论下如何自动估计模型参数。
这里没什么不同寻常的,我们需要选择一个适合任务的损失函数,以了解模型逼近数据的程度。接着,我们通过交叉验证为给定的模型参数评估选择的交叉函数,计算梯度,调整模型参数,等等,勇敢地下降到误差的全局最小值。
问题在于如何在时序数据上进行交叉验证,因为,你知道,时序数据确实具有时间结构,不能在一折中随机混合数据(不保留时间结构),否则观测间的所有时间相关性都会丢失。这就是为什么我们将使用技巧性更强的方法来优化模型参数的原因。我不知道这个方法是否有正式的名称,但是在CrossValidated上(在这个网站上你可以找到所有问题的答案,生命、宇宙以及任何事情的终极答案除外),有人提出了“滚动式交叉验证”(cross-validation on a rolling basis)这一名称。
这一想法很简单——我们在时序数据的一小段上训练模型,从时序开始到某一时刻t,预测接下来的t+n步并计算误差。接着扩张训练样本至t+n个值,并预测从t+n到t+2×n的数据。持续扩张直到穷尽所有观测。初始训练样本到最后的观测之间可以容纳多少个n,我们就可以进行多少折交叉验证。
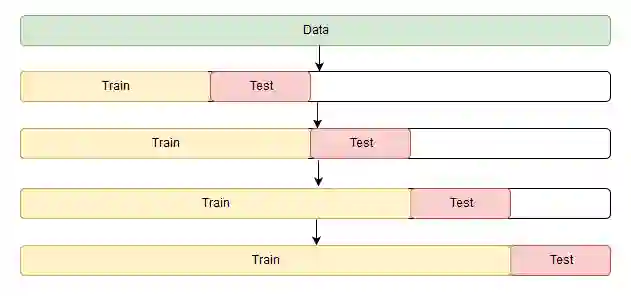
了解了如何设置交叉验证,我们将找出Holt-Winters模型的最优参数,回忆一下,我们的广告数据有按日季节性,所以我们有slen=24。
from sklearn.model_selection import TimeSeriesSplit
def timeseriesCVscore(params, series, loss_function=mean_squared_error, slen=24):
errors = []
values = series.values
alpha, beta, gamma = params
# 设定交叉验证折数
tscv = TimeSeriesSplit(n_splits=3)
for train, test in tscv.split(values):
model = HoltWinters(series=values[train], slen=slen,
alpha=alpha, beta=beta, gamma=gamma, n_preds=len(test))
model.triple_exponential_smoothing()
predictions = model.result[-len(test):]
actual = values[test]
error = loss_function(predictions, actual)
errors.append(error)
return np.mean(np.array(errors))
和其他指数平滑模型一样,Holt-Winters模型中,平滑参数的取值范围在0到1之间,因此我们需要选择一种支持给模型参数添加限制的算法。我们选择了截断牛顿共轭梯度(Truncated Newton conjugate gradient)。
data = ads.Ads[:-20] # 留置一些数据用于测试
# 初始化模型参数alpha、beta、gamma
x = [0, 0, 0]
# 最小化损失函数
opt = minimize(timeseriesCVscore, x0=x,
args=(data, mean_squared_log_error),
method="TNC", bounds = ((0, 1), (0, 1), (0, 1))
)
# 取最优值……
alpha_final, beta_final, gamma_final = opt.x
print(alpha_final, beta_final, gamma_final)
# ……并据此训练模型,预测接下来50个小时的数据
model = HoltWinters(data, slen = 24,
alpha = alpha_final,
beta = beta_final,
gamma = gamma_final,
n_preds = 50, scaling_factor = 3)
model.triple_exponential_smoothing()
最优参数:
0.11652680227350454 0.002677697431105852 0.05820973606789237
绘图部分的代码:
def plotHoltWinters(series, plot_intervals=False, plot_anomalies=False):
"""
series - 时序数据集
plot_intervals - 显示置信区间
plot_anomalies - 显示异常值
"""
plt.figure(figsize=(20, 10))
plt.plot(model.result, label = "Model")
plt.plot(series.values, label = "Actual")
error = mean_absolute_percentage_error(series.values, model.result[:len(series)])
plt.title("Mean Absolute Percentage Error: {0:.2f}%".format(error))
if plot_anomalies:
anomalies = np.array([np.NaN]*len(series))
anomalies[series.values<model.LowerBond[:len(series)]] = \
series.values[series.values<model.LowerBond[:len(series)]]
anomalies[series.values>model.UpperBond[:len(series)]] = \
series.values[series.values>model.UpperBond[:len(series)]]
plt.plot(anomalies, "o", markersize=10, label = "Anomalies")
if plot_intervals:
plt.plot(model.UpperBond, "r--", alpha=0.5, label = "Up/Low confidence")
plt.plot(model.LowerBond, "r--", alpha=0.5)
plt.fill_between(x=range(0,len(model.result)), y1=model.UpperBond,
y2=model.LowerBond, alpha=0.2, color = "grey")
plt.vlines(len(series), ymin=min(model.LowerBond), ymax=max(model.UpperBond), linestyles='dashed')
plt.axvspan(len(series)-20, len(model.result), alpha=0.3, color='lightgrey')
plt.grid(True)
plt.axis('tight')
plt.legend(loc="best", fontsize=13);
plotHoltWinters(ads.Ads)
plotHoltWinters(ads.Ads, plot_intervals=True, plot_anomalies=True)
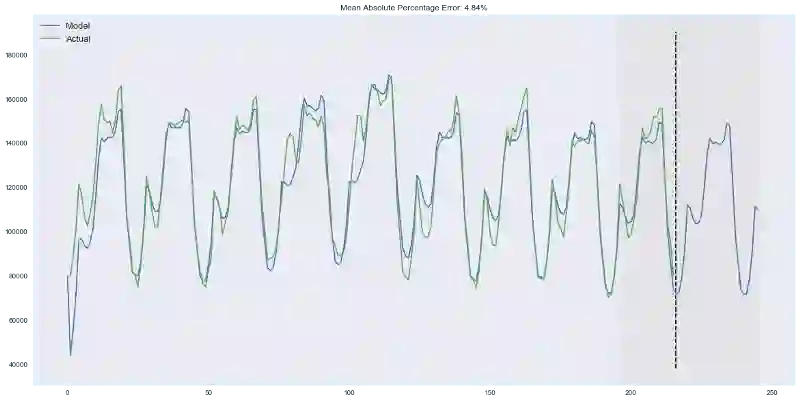
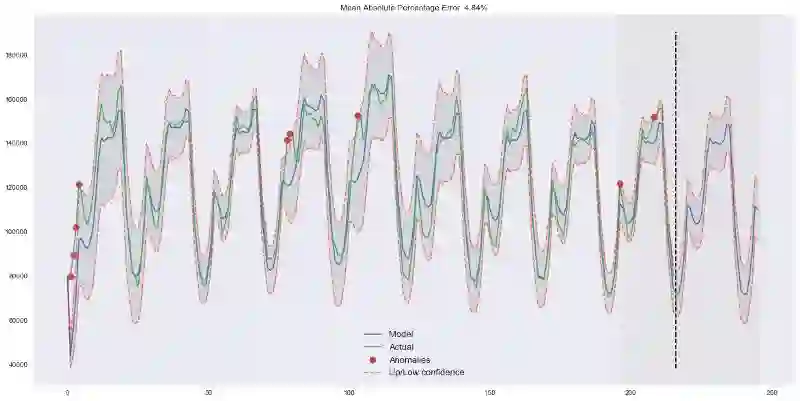
上面的图形表明,我们的模型能够很好地逼近初始时序,捕捉每日季节性,总体的下降趋势,甚至一些异常。如果我们查看下建模偏差(见下图),我们将很明显地看到,模型对序列结构的改变反应相当鲜明,但接着很快偏差就回归正常值,“遗忘”了过去。模型的这一特性让我们甚至可以为相当噪杂的序列快速构建异常检测系统,而无需花费过多时间和金钱准备数据和训练模型。
plt.figure(figsize=(25, 5))
plt.plot(model.PredictedDeviation)
plt.grid(True)
plt.axis('tight')
plt.title("Brutlag's predicted deviation");
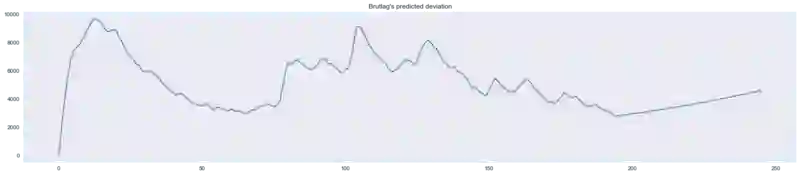
遇到异常时偏差会增加
我们将在第二个序列上应用相同的算法,我们知道,第二个序列具有趋势和每月季节性。
data = currency.GEMS_GEMS_SPENT[:-50]
slen = 30
x = [0, 0, 0]
opt = minimize(timeseriesCVscore, x0=x,
args=(data, mean_absolute_percentage_error, slen),
method="TNC", bounds = ((0, 1), (0, 1), (0, 1))
)
alpha_final, beta_final, gamma_final = opt.x
model = HoltWinters(data, slen = slen,
alpha = alpha_final,
beta = beta_final,
gamma = gamma_final,
n_preds = 100, scaling_factor = 3)
model.triple_exponential_smoothing()

看起来很不错,模型捕捉了向上的趋势和季节性尖峰,总体而言很好地拟合了数据。
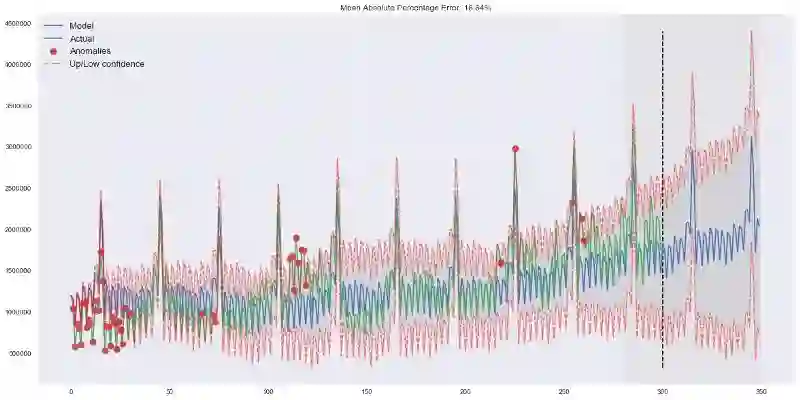
也捕获了一些异常

计量经济学方法
平稳性
在开始建模之前,我们需要提一下时序的一个重要性质:平稳性(stationarity)。
如果过程是平稳的,那么它的统计性质不随时间而变,也就是均值和方差不随时间改变(方差的恒定性也称为同方差性),同时协方差函数也不取决于时间(应该只取决于观测之间的距离)。Sean Abu的博客提供了一些可视化的图片:
右边的红色曲线不平稳,因为均值随着时间增加:
这一次,右边的红色曲线在方差方面的运气不好:
最后,第i项和第(i+m)项的协方差函数不应该是时间的函数。随着时间推移,右边的红色曲线更紧了。因此,协方差不是常量。
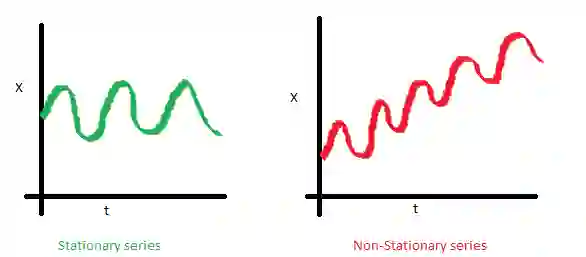
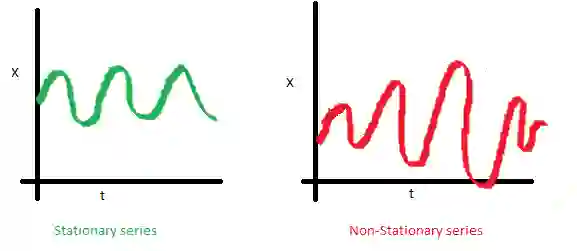
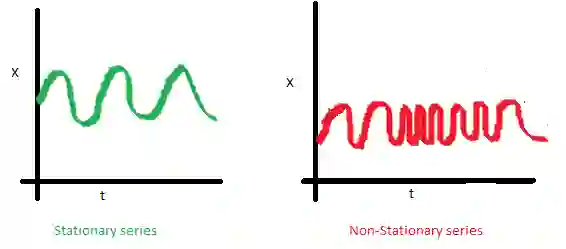
为什么平稳性如此重要?我们假定未来的统计性质不会和现在观测到的不同,在平稳序列上做出预测很容易。大多数时序模型多多少少建模和预测这些性质(例如均值和方差),这就是如果原序列不平稳,预测会出错的原因。不幸的是,我们在教科书以外的地方见到的大多数时序都是不平稳的。不过,我们可以(并且应该)改变这一点。
知己知彼,百战不殆。为了对抗不平稳性,我们首先需要检测它。我们现在将查看下白噪声和随机游走,并且了解下如何免费从白噪声转到随机游走,无需注册和接受验证短信。
白噪声图形:
white_noise = np.random.normal(size=1000)
with plt.style.context('bmh'):
plt.figure(figsize=(15, 5))
plt.plot(white_noise)
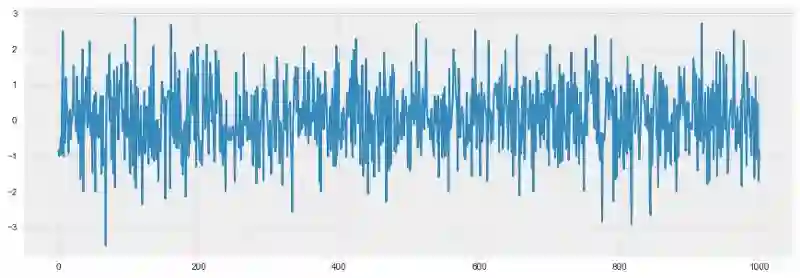
这一通过标准正态分布生成的过程是平稳的,以0为中心振荡,偏差为1. 现在我们将基于这一过程生成一个新过程,其中相邻值之间的关系为:xt = ρxt-1 + et
def plotProcess(n_samples=1000, rho=0):
x = w = np.random.normal(size=n_samples)
for t in range(n_samples):
x[t] = rho * x[t-1] + w[t]
with plt.style.context('bmh'):
plt.figure(figsize=(10, 3))
plt.plot(x)
plt.title("Rho {}\n Dickey-Fuller p-value: {}".format(rho, round(sm.tsa.stattools.adfuller(x)[1], 3)))
for rho in [0, 0.6, 0.9, 1]:
plotProcess(rho=rho)
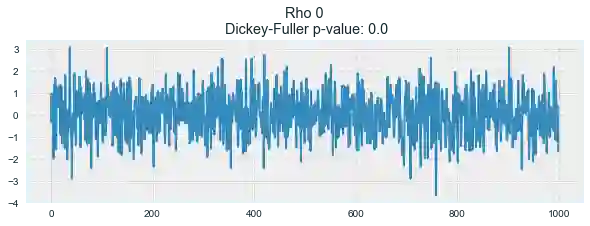
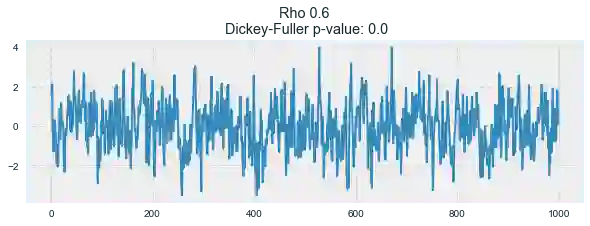
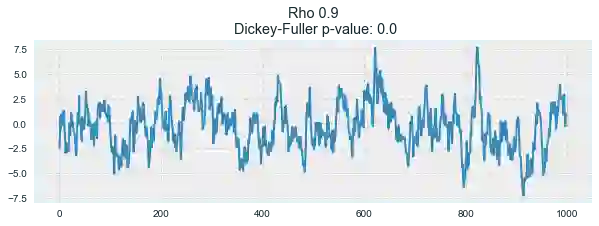
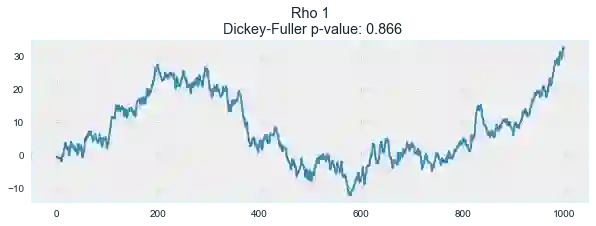
第一张图上你可以看到之前的平稳的白噪声。第二张图的ρ值增加到0.6,导致周期更宽了,但总体上还是平稳的。第三张图更偏离均值0,但仍以其为中心振荡。最后,ρ值为1时我们得到了随机游走过程——不平稳的时序。
这是因为达到阈值后,时序xt = ρxt-1 + et不再回归其均值。如果我们从等式的两边减去xt-1,我们将得到xt - xt-1 = (ρ-1)xt-1 + et,其中等式左边的表达式称为一阶差分(first difference)。如果ρ = 1,那么一阶差分将是平稳的白噪声et。这一事实是时序平稳性的迪基-福勒检验(Dickey-Fuller test)的主要思想(检验是否存在单位根)。如果非平稳序列可以通过一阶差分得到平稳序列,那么这样的序列称为一阶单整(integrated of order 1)序列。需要指出的是,一阶差分并不总是足以得到平稳序列,因为过程可能是d阶单整且d > 1(具有多个单位根),在这样的情形下,需要使用增广迪基-福勒检验(augmented Dickey-Fuller test)。
我们可以使用不同方法对抗不平稳性——多阶差分,移除趋势和季节性,平滑,以及Box-Cox变换或对数变换。
创建SARIMA摆脱不平稳性
现在,让我们历经使序列平稳的多层地狱,创建一个ARIMA模型。
def tsplot(y, lags=None, figsize=(12, 7), style='bmh'):
"""
绘制时序及其ACF(自相关性函数)、PACF(偏自相关性函数),计算迪基-福勒检验
y - 时序
lags - ACF、PACF计算所用的时差
"""
if not isinstance(y, pd.Series):
y = pd.Series(y)
with plt.style.context(style):
fig = plt.figure(figsize=figsize)
layout = (2, 2)
ts_ax = plt.subplot2grid(layout, (0, 0), colspan=2)
acf_ax = plt.subplot2grid(layout, (1, 0))
pacf_ax = plt.subplot2grid(layout, (1, 1))
y.plot(ax=ts_ax)
p_value = sm.tsa.stattools.adfuller(y)[1]
ts_ax.set_title('Time Series Analysis Plots\n Dickey-Fuller: p={0:.5f}'.format(p_value))
smt.graphics.plot_acf(y, lags=lags, ax=acf_ax)
smt.graphics.plot_pacf(y, lags=lags, ax=pacf_ax)
plt.tight_layout()
tsplot(ads.Ads, lags=60)
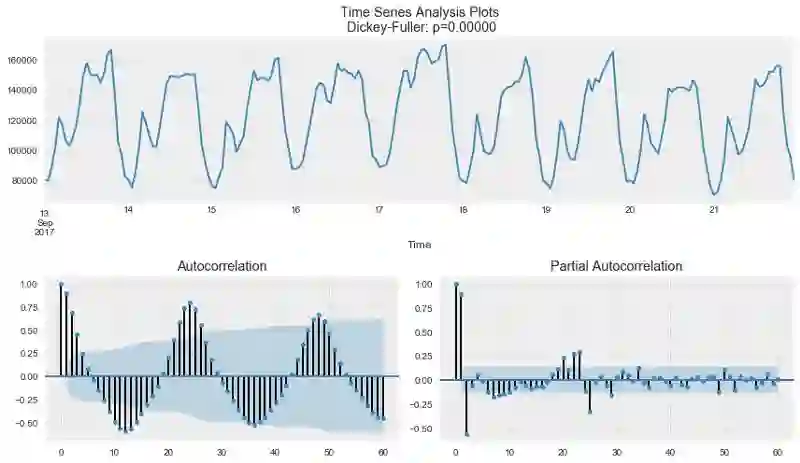
出乎意料,初始序列是平稳的,迪基-福勒检验拒绝了单位根存在的零假设。实际上,从上面的图形本身就可以看出这一点——没有可见的趋势,所以均值是恒定的,整个序列的方差也相对比较稳定。在建模之前我们只需处理季节性。为此让我们采用“季节差分”,也就是对序列进行简单的减法操作,时差等于季节周期。
ads_diff = ads.Ads - ads.Ads.shift(24)
tsplot(ads_diff[24:], lags=60)
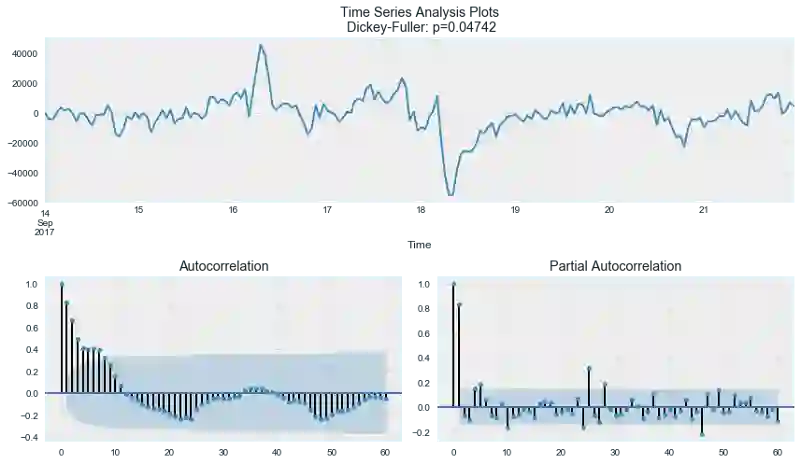
好多了,可见的季节性消失了,然而自相关函数仍然有过多显著的时差。为了移除它们,我们将取一阶差分:从序列中减去自身(时差为1)
ads_diff = ads_diff - ads_diff.shift(1)
tsplot(ads_diff[24+1:], lags=60)
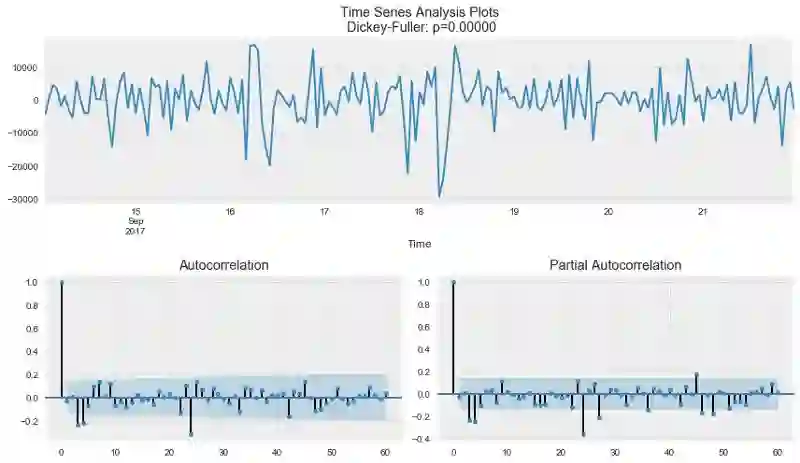
完美!我们的序列看上去是难以用笔墨形容的完美!在零周围振荡,迪基-福勒检验表明它是平稳的,ACF中显著的尖峰不见了。我们终于可以开始建模了!
ARIMA系速成教程
我们将逐字母讲解SARIMA(p,d,q)(P,D,Q,s),季节自回归移动平均模型(Seasonal Autoregression Moving Average model):
AR(p) —— 自回归模型,也就是在时序自身之上回归。基本假设是当前序列值取决于某个(或若干个)时差前的值。模型中的最大时差记为p。通过PACF图决定初始p值——找到最大的显著时差,之后大多数其他时差变得不显著。
MA(q) —— 移动平均模型。这里不讨论它的细节,总之它基于以下假设建模时序的误差,当前误差取决于某个时差前的值(记为q)。基于和自回归模型类似的逻辑,可以通过ACF图找出初始值。
让我们把这4个字母组合起来:
AR(p) + MA(q) = ARMA(p,q)
这里我们得到了自回归移动平均模型!如果序列是平稳的,我们可以通过这4个字母逼近这一序列。
I(d) —— d阶单整。它不过是使序列平稳所需的非季节性差分数。在我们的例子中,它等于1,因为我们使用一阶差分。
加上这一字母后我们得到了ARIMA模型,可以通过非季节性差分处理非平稳数据。
S(s) —— 这个字母代表季节性,s为序列的季节周期长度。
加上最后一个字母S后,我们发现这最后一个字母除了s之外,还附带了三个额外参数——(P,D,Q)。
P —— 模型的季节分量的自回归阶数,同样可以从PACF得到,但是这次需要查看季节周期长度的倍数的显著时差的数量。例如,如果周期长度等于24,查看PACF发现第24个时差和第48个时差显著,那么初始P值应当是2.
Q —— 移动平均模型的季节分量的阶数,初始值的确定和P同理,只不过使用ACF图形。
D —— 季节性单整阶数。等于1或0,分别表示是否应用季节差分。
了解了如何设置初始参数后,让我们回过头去重新看下最终的图形:
p最有可能是4,因为这是PACF上最后一个显著的时差,之后大多数时差变得不显著。
d等于1,因为我们采用的是一阶差分。
q大概也等于4,这可以从ACF上看出来。
P可能等于2,因为PACF上第24个时差和第48个时差某种程度上比较显著。
D等于1,我们应用了季节差分。
Q大概是1,ACF上第24个时差是显著的,而第48个时差不显著。
现在我们打算测试不同的参数组合,看看哪个是最好的:
# 设定初始值和初始范围
ps = range(2, 5)
d=1
qs = range(2, 5)
Ps = range(0, 3)
D=1
Qs = range(0, 2)
s = 24
# 创建参数所有可能组合的列表
parameters = product(ps, qs, Ps, Qs)
parameters_list = list(parameters)
len(parameters_list)的结果是54,也就是说,共有54种组合。
def optimizeSARIMA(parameters_list, d, D, s):
"""
返回参数和相应的AIC的dataframe
parameters_list - (p, q, P, Q)元组列表
d - ARIMA模型的单整阶
D - 季节性单整阶
s - 季节长度
"""
results = []
best_aic = float("inf")
for param in tqdm_notebook(parameters_list):
# 由于有些组合不能收敛,所以需要使用try-except
try:
model=sm.tsa.statespace.SARIMAX(ads.Ads, order=(param[0], d, param[1]),
seasonal_order=(param[3], D, param[3], s)).fit(disp=-1)
except:
continue
aic = model.aic
# 保存最佳模型、AIC、参数
if aic < best_aic:
best_model = model
best_aic = aic
best_param = param
results.append([param, model.aic])
result_table = pd.DataFrame(results)
result_table.columns = ['parameters', 'aic']
# 递增排序,AIC越低越好
result_table = result_table.sort_values(by='aic', ascending=True).reset_index(drop=True)
return result_table
result_table = optimizeSARIMA(parameters_list, d, D, s)
# 设定参数为给出最低AIC的参数组合
p, q, P, Q = result_table.parameters[0]
best_model=sm.tsa.statespace.SARIMAX(ads.Ads, order=(p, d, q),
seasonal_order=(P, D, Q, s)).fit(disp=-1)
print(best_model.summary())
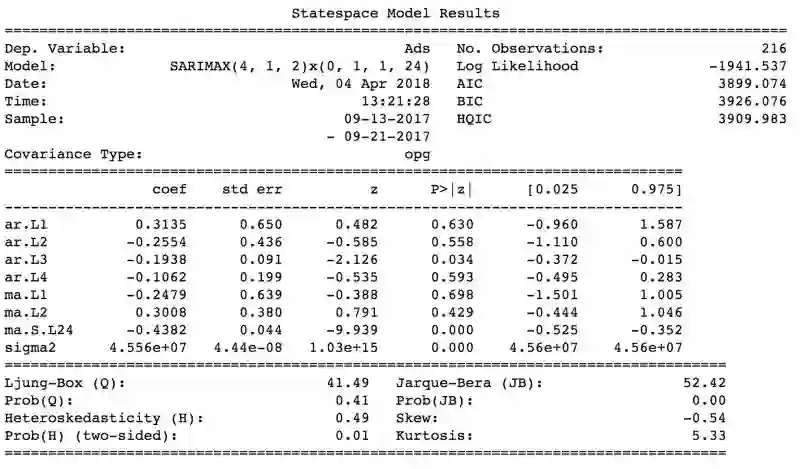
让我们查看下这一模型的残余分量(residual):
tsplot(best_model.resid[24+1:], lags=60)
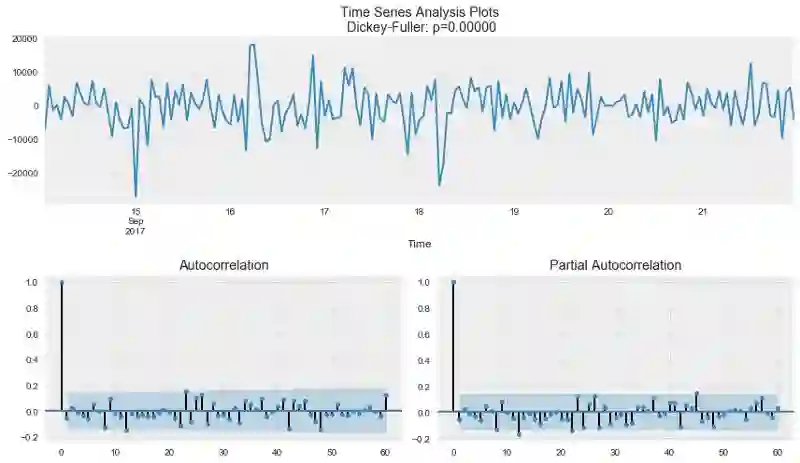
很明显,残余是平稳的,没有明显的自相关性。
让我们使用这一模型进行预测:
def plotSARIMA(series, model, n_steps):
"""
绘制模型预测值与实际数据对比图
series - 时序数据集
model - SARIMA模型
n_steps - 预测未来的步数
"""
data = series.copy()
data.columns = ['actual']
data['arima_model'] = model.fittedvalues
# 平移s+d步,因为差分的缘故,前面的一些数据没有被模型观测到
data['arima_model'][:s+d] = np.NaN
forecast = model.predict(start = data.shape[0], end = data.shape[0]+n_steps)
forecast = data.arima_model.append(forecast)
# 计算误差,同样平移s+d步
error = mean_absolute_percentage_error(data['actual'][s+d:], data['arima_model'][s+d:])
plt.figure(figsize=(15, 7))
plt.title("Mean Absolute Percentage Error: {0:.2f}%".format(error))
plt.plot(forecast, color='r', label="model")
plt.axvspan(data.index[-1], forecast.index[-1], alpha=0.5, color='lightgrey')
plt.plot(data.actual, label="actual")
plt.legend()
plt.grid(True);
plotSARIMA(ads, best_model, 50)
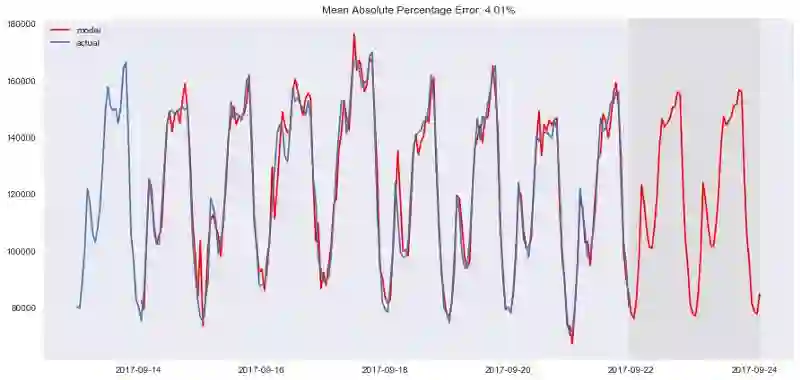
最终我们得到了相当不错的预测,模型的平均误差率是4.01%,这非常非常好。但是为了达到这一精确度,在准备数据、使序列平稳化、暴力搜索参数上付出了太多。
时序数据上的线性(以及不那么线性)模型
在我的工作中,创建模型的指导原则常常是快、好、省。这意味着有些模型永远不会用于生产环境,因为它们需要过长的时间准备数据(比如SARIMA),或者需要频繁地重新训练新数据(比如SARIMA),或者很难调整(比如SARIMA)。相反,我经常使用轻松得多的方法,从现有时序中选取一些特征,然后创建一个简单的线性回归或随机森林模型。又快又省。
也许这个方法没有充分的理论支撑,打破了一些假定(比如,高斯-马尔可夫定理,特别是误差不相关的部分),但在实践中,这很有用,在机器学习竞赛中也相当常用。
特征提取
很好,模型需要特征,而我们所有的不过是1维时序。我们可以提取什么特征?
首先当然是时差。
窗口统计量:
窗口内序列的最大/小值
窗口的平均数/中位数
窗口的方差
等等
日期和时间特征
每小时的第几分钟,每天的第几小时,每周的第几天,你懂的
这一天是节假日吗?也许有什么特别的事情发生了?这可以作为布尔值特征
目标编码
其他模型的预测(不过如此预测的话会损失速度)
让我们运行一些模型,看看我们可以从广告序列中提取什么
时序的时差
将序列往回移动n步,我们能得到一个特征,其中时序的当前值和其t-n时刻的值对齐。如果我们移动1时差,并训练模型预测未来,那么模型将能够提前预测1步。增加时差,比如,增加到6,可以让模型提前预测6步,不过它需要在观测到数据的6步之后才能利用。如果在这期间序列发生了根本性的变动,那么模型无法捕捉这一变动,会返回误差很大的预测。因此,时差的选取需要平衡预测的质量和时长。
data = pd.DataFrame(ads.Ads.copy())
data.columns = ["y"]
for i in range(6, 25):
data["lag_{}".format(i)] = data.y.shift(i)
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import cross_val_score
# 5折交叉验证
tscv = TimeSeriesSplit(n_splits=5)
def timeseries_train_test_split(X, y, test_size):
test_index = int(len(X)*(1-test_size))
X_train = X.iloc[:test_index]
y_train = y.iloc[:test_index]
X_test = X.iloc[test_index:]
y_test = y.iloc[test_index:]
return X_train, X_test, y_train, y_test
def plotModelResults(model, X_train=X_train, X_test=X_test, plot_intervals=False, plot_anomalies=False):
prediction = model.predict(X_test)
plt.figure(figsize=(15, 7))
plt.plot(prediction, "g", label="prediction", linewidth=2.0)
plt.plot(y_test.values, label="actual", linewidth=2.0)
if plot_intervals:
cv = cross_val_score(model, X_train, y_train,
cv=tscv,
scoring="neg_mean_absolute_error")
mae = cv.mean() * (-1)
deviation = cv.std()
scale = 1.96
lower = prediction - (mae + scale * deviation)
upper = prediction + (mae + scale * deviation)
plt.plot(lower, "r--", label="upper bond / lower bond", alpha=0.5)
plt.plot(upper, "r--", alpha=0.5)
if plot_anomalies:
anomalies = np.array([np.NaN]*len(y_test))
anomalies[y_test<lower] = y_test[y_test<lower]
anomalies[y_test>upper] = y_test[y_test>upper]
plt.plot(anomalies, "o", markersize=10, label = "Anomalies")
error = mean_absolute_percentage_error(prediction, y_test)
plt.title("Mean absolute percentage error {0:.2f}%".format(error))
plt.legend(loc="best")
plt.tight_layout()
plt.grid(True);
def plotCoefficients(model):
"""
绘制模型排序后的系数
"""
coefs = pd.DataFrame(model.coef_, X_train.columns)
coefs.columns = ["coef"]
coefs["abs"] = coefs.coef.apply(np.abs)
coefs = coefs.sort_values(by="abs", ascending=False).drop(["abs"], axis=1)
plt.figure(figsize=(15, 7))
coefs.coef.plot(kind='bar')
plt.grid(True, axis='y')
plt.hlines(y=0, xmin=0, xmax=len(coefs), linestyles='dashed');
y = data.dropna().y
X = data.dropna().drop(['y'], axis=1)
# 保留30%数据用于测试
X_train, X_test, y_train, y_test = timeseries_train_test_split(X, y, test_size=0.3)
# 机器学习
lr = LinearRegression()
lr.fit(X_train, y_train)
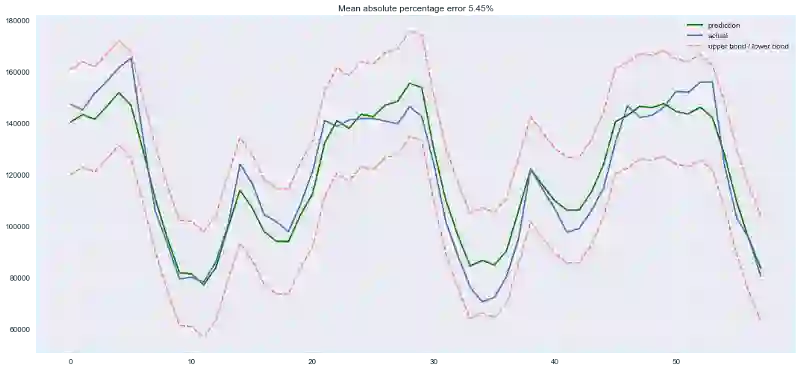
plotModelResults(lr, plot_intervals=True)
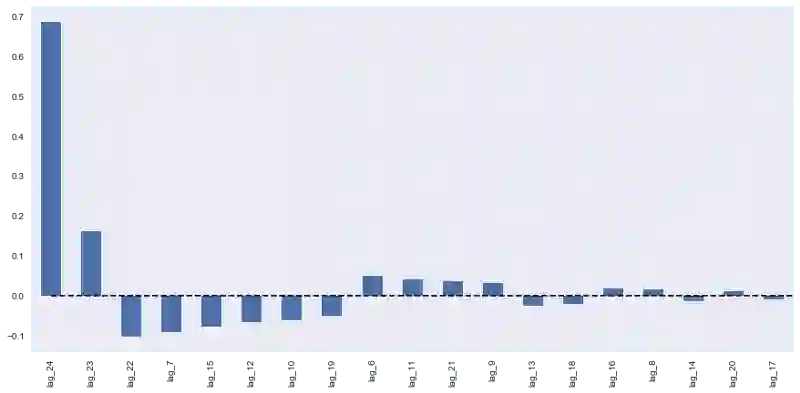
plotCoefficients(lr)
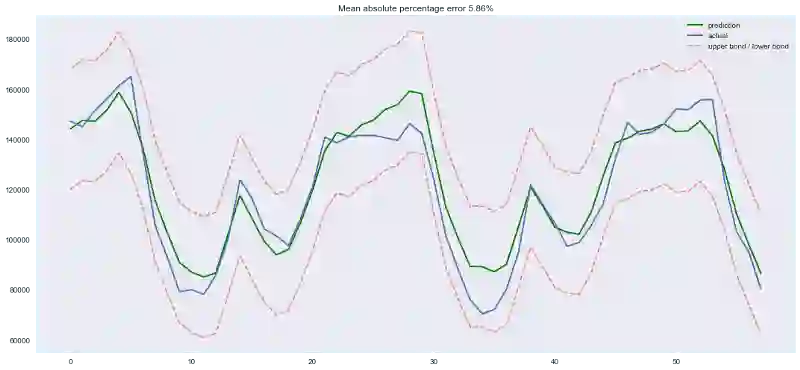
模型预测值:绿线为预测值,蓝线为实际值
好吧,简单的时差和线性回归给出的预测质量和SARIMA差得不远。有大量不必要的特征,不过我们将在之后进行特征选择。现在让我们继续增加特征!
我们将在数据集中加入小时、星期几、是否周末三个特征。为此我们需要转换当前dataframe的索引为datetime格式,并从中提取hour和weekday。
data.index = data.index.to_datetime()
data["hour"] = data.index.hour
data["weekday"] = data.index.weekday
data['is_weekend'] = data.weekday.isin([5,6])*1
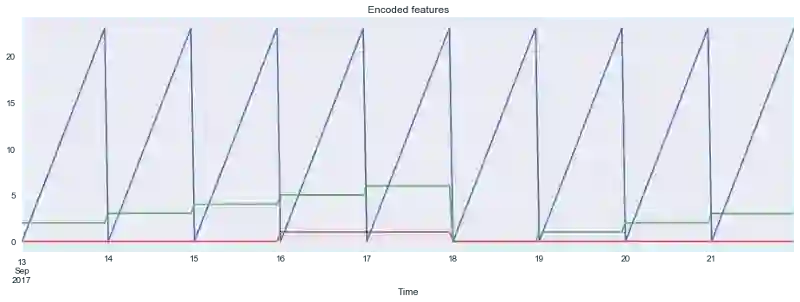
可视化所得特征:
plt.figure(figsize=(16, 5))
plt.title("Encoded features")
data.hour.plot()
data.weekday.plot()
data.is_weekend.plot()
plt.grid(True);
由于现有的变量尺度不同——时差的长度数千,类别变量的尺度数十——将它们转换为同一尺度再合理不过,这样也便于探索特征重要性,以及之后的正则化。
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
y = data.dropna().y
X = data.dropna().drop(['y'], axis=1)
X_train, X_test, y_train, y_test = timeseries_train_test_split(X, y, test_size=0.3)
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
lr = LinearRegression()
lr.fit(X_train_scaled, y_train)
plotModelResults(lr, X_train=X_train_scaled, X_test=X_test_scaled, plot_intervals=True)
plotCoefficients(lr)
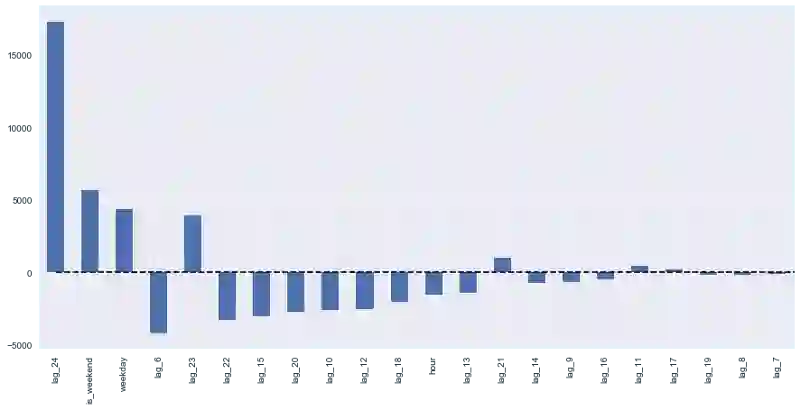
测试误差略有下降。从上面的系数图像我们可以得出结论,weekday和is_weekend是非常有用的特征。
目标编码
我想介绍另一种类别变量编码的变体——基于均值。如果不想让成吨的独热编码使模型暴涨,同时导致距离信息损失,同时又因为“0点 < 23点”之类的冲突无法使用实数值,那么我们可以用相对易于解释的值编码变量。很自然的一个想法是使用均值编码目标变量。在我们的例子中,星期几和一天的第几小时可以通过那一天或那一小时浏览的广告平均数编码。非常重要的是,确保均值是在训练集上计算的(或者交叉验证当前的折),避免模型偷窥未来。
def code_mean(data, cat_feature, real_feature):
"""
返回一个字典,键为cat_feature的类别,
值为real_feature的均值。
"""
return dict(data.groupby(cat_feature)[real_feature].mean())
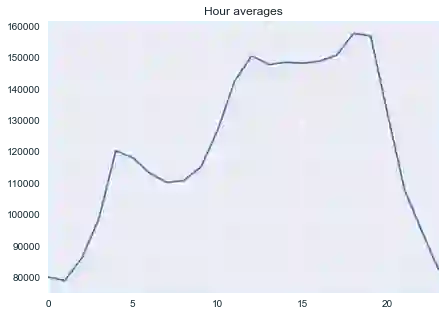
让我们看下小时平均:
average_hour = code_mean(data, 'hour', "y")
plt.figure(figsize=(7, 5))
plt.title("Hour averages")
pd.DataFrame.from_dict(average_hour, orient='index')[0].plot()
plt.grid(True);
最后,让我们定义一个函数完成所有的转换:
def prepareData(series, lag_start, lag_end, test_size, target_encoding=False):
data = pd.DataFrame(series.copy())
data.columns = ["y"]
for i in range(lag_start, lag_end):
data["lag_{}".format(i)] = data.y.shift(i)
data.index = data.index.to_datetime()
data["hour"] = data.index.hour
data["weekday"] = data.index.weekday
data['is_weekend'] = data.weekday.isin([5,6])*1
if target_encoding:
test_index = int(len(data.dropna())*(1-test_size))
data['weekday_average'] = list(map(
code_mean(data[:test_index], 'weekday', "y").get, data.weekday))
data["hour_average"] = list(map(
code_mean(data[:test_index], 'hour', "y").get, data.hour))
data.drop(["hour", "weekday"], axis=1, inplace=True)
y = data.dropna().y
X = data.dropna().drop(['y'], axis=1)
X_train, X_test, y_train, y_test =\
timeseries_train_test_split(X, y, test_size=test_size)
return X_train, X_test, y_train, y_test
X_train, X_test, y_train, y_test =\
prepareData(ads.Ads, lag_start=6, lag_end=25, test_size=0.3, target_encoding=True)
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
lr = LinearRegression()
lr.fit(X_train_scaled, y_train)
plotModelResults(lr, X_train=X_train_scaled, X_test=X_test_scaled,
plot_intervals=True, plot_anomalies=True)
plotCoefficients(lr)
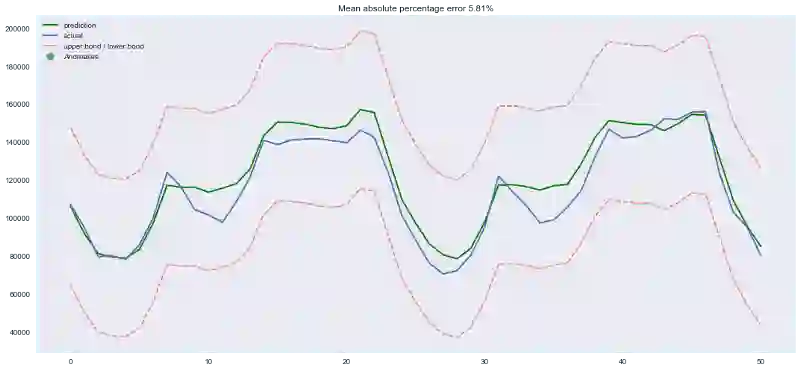
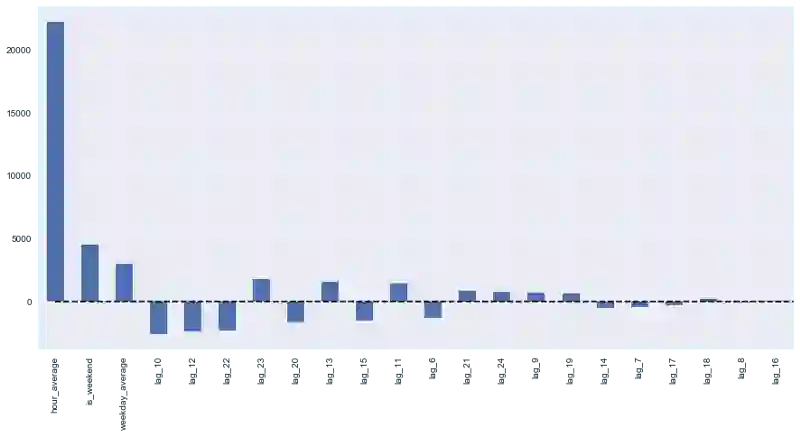
这里出现了过拟合!Hour_average变量在训练数据集上表现如此优异,模型决定集中全力在这个变量上——这导致预测质量下降。处理这一问题有多种方法,比如,我们可以不在整个训练集上计算目标编码,而是在某个窗口上计算,从最后观测到的窗口得到的编码大概能够更好地描述序列的当前状态。或者我们可以直接手工移除这一特征,反正我们已经确定它只会带来坏处。
X_train, X_test, y_train, y_test =\
prepareData(ads.Ads, lag_start=6, lag_end=25, test_size=0.3, target_encoding=False)
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
正则化和特征选取
正如我们已经知道的那样,并不是所有的特征都一样健康,有些可能导致过拟合。除了手工检查外我们还可以应用正则化。最流行的两个带正则化的回归模型是岭(Ridge)回归和Lasso回归。它们都在损失函数上施加了某种限制。
在岭回归的情形下,限制是系数的平方和,乘以正则化系数。也就是说,特征系数越大,损失越大,因此优化模型的同时将尽可能地保持系数在较低水平。
因为限制是系数的平方和,所以这一正则化方法称为L2。它将导致更高的偏差和更低的方差,所以模型的概括性会更好(至少这是我们希望发生的)。
第二种模型Lasso回归,在损失函数中加上的不是平方和,而是系数绝对值之和。因此在优化过程中,不重要的特征的系数将变为零,所以Lasso回归可以实现自动特征选择。这类正则化称为L1。
首先,确认下我们有特征可以移除,也就是说,确实有高度相关的特征:
plt.figure(figsize=(10, 8))
sns.heatmap(X_train.corr());
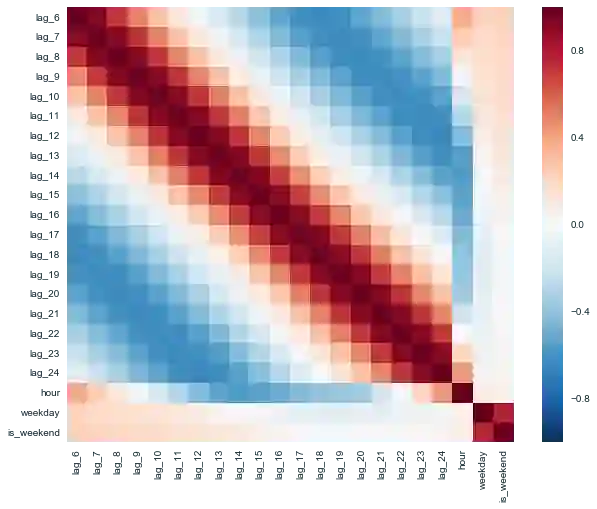
比某些现代艺术要漂亮
from sklearn.linear_model import LassoCV, RidgeCV
ridge = RidgeCV(cv=tscv)
ridge.fit(X_train_scaled, y_train)
plotModelResults(ridge,
X_train=X_train_scaled,
X_test=X_test_scaled,
plot_intervals=True, plot_anomalies=True)
plotCoefficients(ridge)
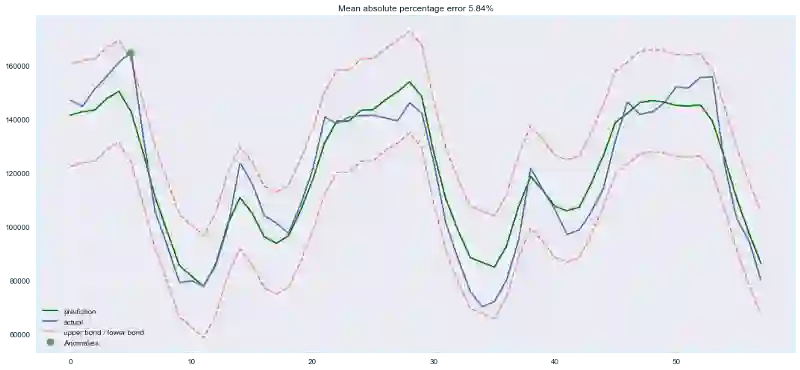
我们可以很清楚地看到,随着特征在模型中的重要性的降低,系数越来越接近零(不过从未达到零):
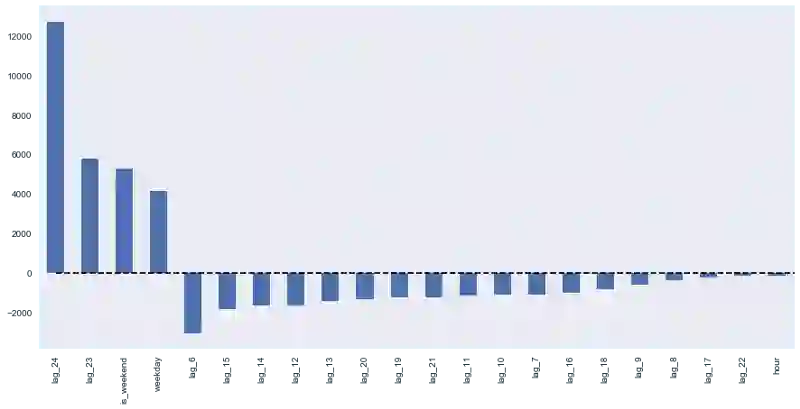
lasso = LassoCV(cv=tscv)
lasso.fit(X_train_scaled, y_train)
plotModelResults(lasso,
X_train=X_train_scaled,
X_test=X_test_scaled,
plot_intervals=True, plot_anomalies=True)
plotCoefficients(lasso)
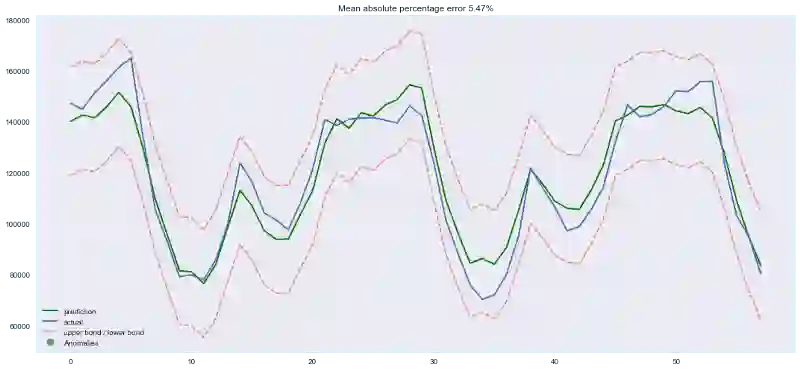
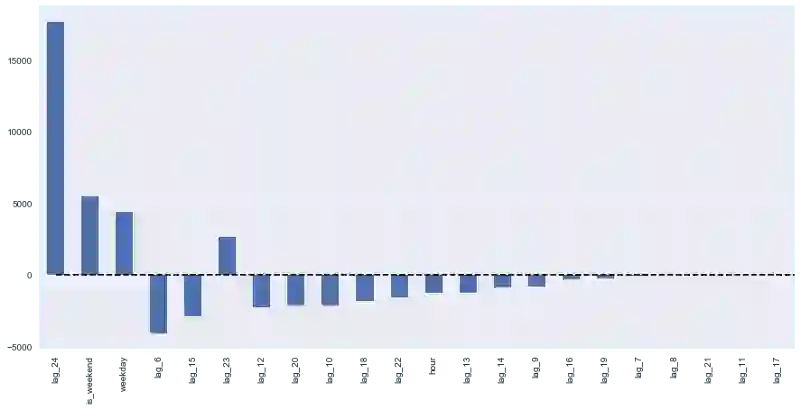
Lasso回k看起来更保守一点,没有将第23时差作为最重要特征,同时完全移除了5项特征,这提升了预测质量。
XGBoost
为什么不试试XGBoost?

from xgboost import XGBRegressor
xgb = XGBRegressor()
xgb.fit(X_train_scaled, y_train)
plotModelResults(xgb,
X_train=X_train_scaled,
X_test=X_test_scaled,
plot_intervals=True, plot_anomalies=True)
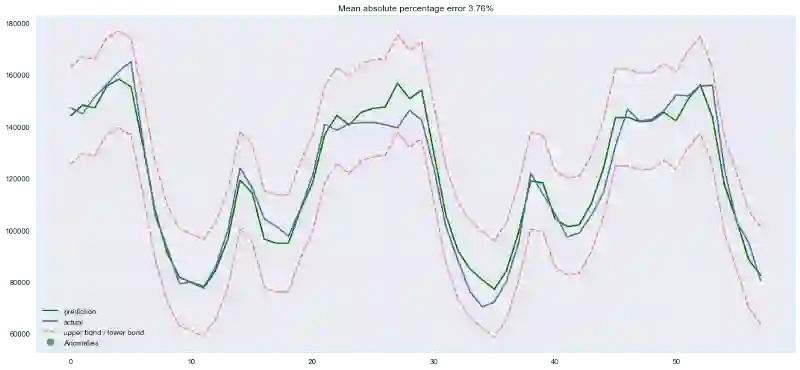
我们的赢家出现了!在我们目前为止尝试过的模型中,XGBoost在测试集上的误差是最小的。
不过这一胜利带有欺骗性,刚到手时序数据,马上尝试XGBoost也许不是什么明智的选择。一般而言,和线性模型相比,基于树的模型难以应付数据中的趋势,所以你首先需要从序列中去除趋势,或者使用一些特殊技巧。理想情况下,平稳化序列,接着使用XGBoost,例如,你可以使用一个线性模型单独预测趋势,然后将其加入XGBoost的预测以得到最终预测。
结语
我们熟悉了不同的时序分析和预测方法。很不幸,或者,很幸运,解决这类问题没有银弹。上世纪60年代研发的方法(有些甚至在19世纪就提出了)和LSTM、RNN(本文没有介绍)一样流行。这部分是因为时序预测任务和任何其他数据预测任务一样,在许多方面都需要创造性和研究。尽管有众多形式化的质量测度和参数估计方法,我们常常需要为每个序列搜寻并尝试一些不同的东西。最后,平衡质量和成本很重要。之前提到的SARIMA模型是一个很好的例子,经过调节之后,它常常能生成出色的结果,但这需要许多小时、许多复杂技巧来处理数据,相反,10分钟之内就可以创建好的简单线性回归模型却能取得相当的结果。
相关资源
杜克大学的高级统计预测课程的在线教材,其中介绍了多种平滑技术、线性模型、ARIMA模型的细节:https://people.duke.edu/~rnau/411home.htm
比较ARIMA和随机森林预测H5N1高致病性禽流感爆发:https://bmcbioinformatics.biomedcentral.com/articles/10.1186/1471-2105-15-276
基于Python进行时序分析——从线性模型到图模型,其中介绍了ARIMA模型家族,及其在建模财经指数上的应用:http://www.blackarbs.com/blog/time-series-analysis-in-python-linear-models-to-garch/11/1/2016
原文地址:https://medium.com/open-machine-learning-course/open-machine-learning-course-topic-9-time-series-analysis-in-python-a270cb05e0b3



