达观数据张健分享文本分类方法和应用案例 | 学术青年分享会

自然语言处理(NLP)一直是人工智能领域的重要话题,而人类语言的复杂性也给 NLP 布下了重重困难等待解决。随着深度学习(Deep Learning)的热潮来临,有许多新方法来到了 NLP 领域,给相关任务带来了更多优秀成果,也给大家带来了更多应用和想象的空间。
近期,AI 研习社就邀请到了达观数据的张健为大家分享了一些 NLP 方面的知识和案例。
▷ 观看完整回顾大概需要 49 分钟
分享主题
达观数据 NLP 技术的应用实践和案例分析
分享人
张健,达观数据联合创始人,文本挖掘组总负责人,包括文本审核系统的架构设计、开发和日常维护升级,文本挖掘功能开发。复旦大学计算机软件与理论硕士,曾在盛大创新院负责相关推荐模块,在盛大文学数据中心负责任务调度平台系统和集群维护管理,数据平台维护管理和开发智能审核系统。对大数据技术、机器学习算法有较深入的理解和实践经验。

此次分享中,张健按照 NLP 概述、文本分类的传统方法、深度学习在文本分类中的应用和案例介绍四个板块,结合在达观数据的系统设计和应用经验,分享了他的见解。
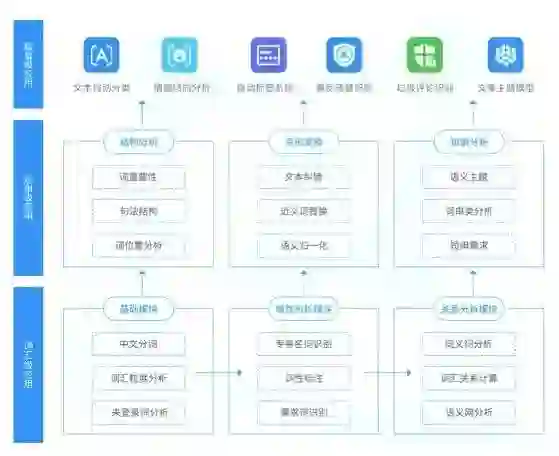
达观数据是一家专注于文本挖掘和搜索推荐技术服务的企业,总部位于上海浦东软件园。达观的 NLP 挖掘系统的设计思路是,用户直接接触的到的最终功能,他们称为是篇章级应用,可以处理整段的文本,提供的功能包括文本自动分类、情感分析、自动文本标签、违禁词汇和垃圾评论识别等。在下方支持编章级应用的是短串级应用,更底层一些,在词组、短句的层面上提供结构分析和变形、词位置分析、近义词替换等功能。最底层、最小粒度的是词汇级应用,比如中文分词、词粒度分析、调性标柱等等。


文本挖掘的任务可以分成四类:
同步的序列到序列,特点是输入文本的每一个位置都有对应的输出
异步序列到序列,输入和输出可以不完全对应
序列到类别,给文本加上标签
类别到序列,根据给定的标签生成文本
然后张健依次介绍了序列到序列任务中几种问题的常见解决方案。
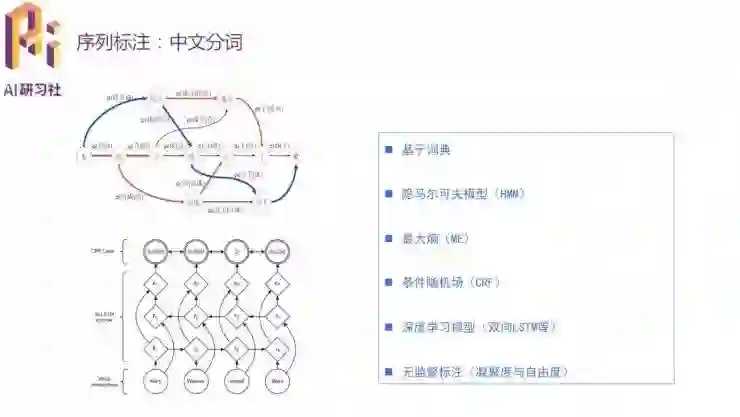
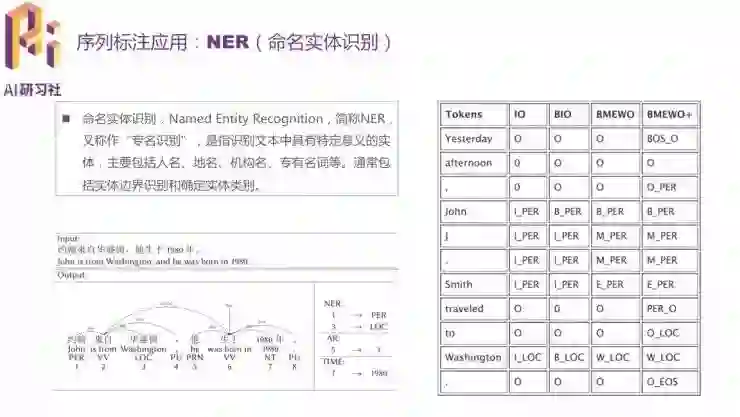
在序列标注/命名实体识别问题中,每个词都会有各自的标签;选用的词汇标签体系越复杂,标注精度就越高,但同时训练也就越慢。所以需要根据人力、时间等成本选择合适的标签体系。

英文不需要分词,但是多了词形还原和词根提取的问题。在这里,张健推荐 WordNet 来帮助解决相关问题。


接下来进入了今天讲解的重点,就是文本分类。

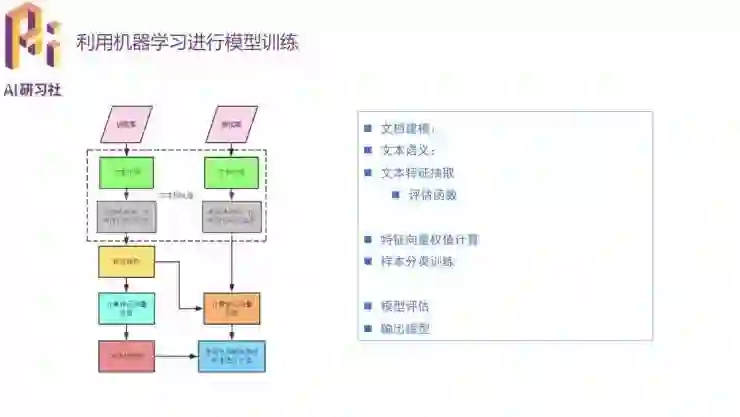
传统机器学习方法做文本分类会需要文档建模、文本语意、特征抽取、特征向量赋权等步骤。



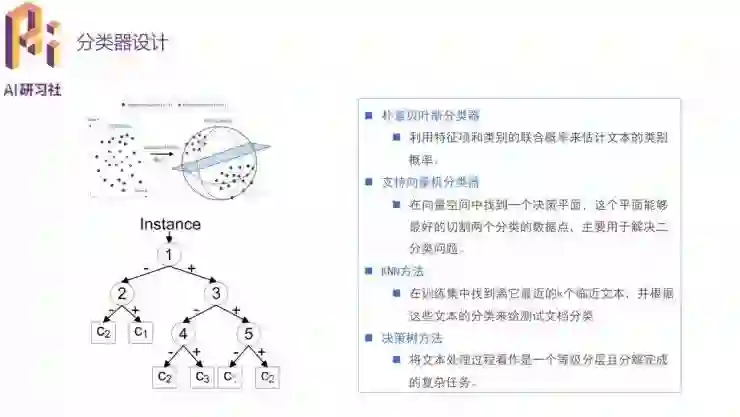
具体到分类器的设计,常用的四种思路为朴素贝叶斯分类器、支持向量机分类器、KNN 方法和决策树方法。
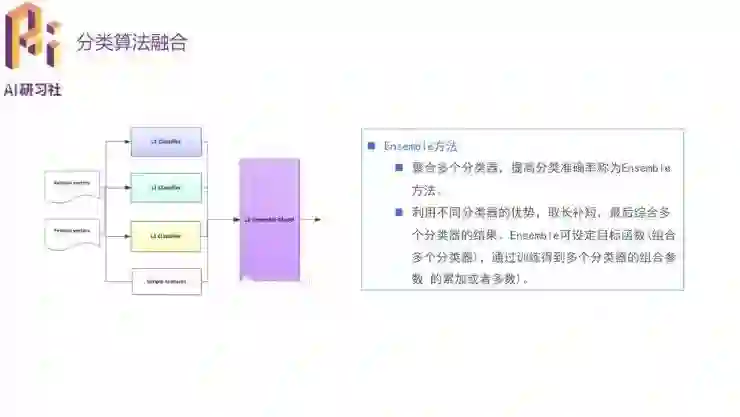
然后还可以聚合多个分类器来提高准确率。最简单的想法是用多个模型分别预测然后投票,实际的聚合方法是另外训练一个分类器,模仿多个分类器组合后的结果。这里需要原来的几个分类器效果不能太接近,而且不能有太差的。

在有了深度学习以后,文本分类又有了很多效果出色的新方法。
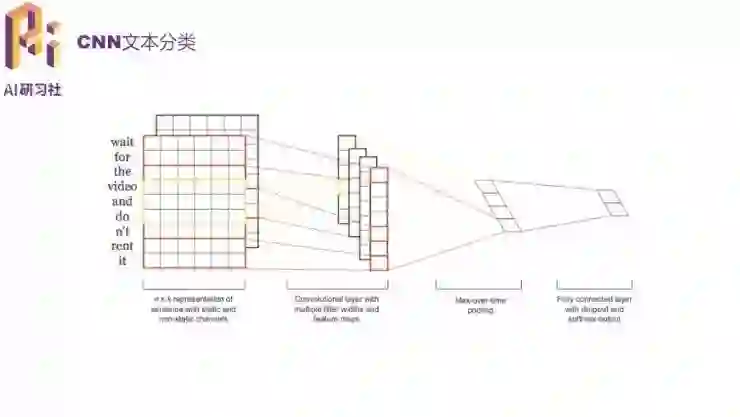
首先可以用 CNN 做文本分类,它不需要人工特征,而对词序包含的信息提取能力更强。
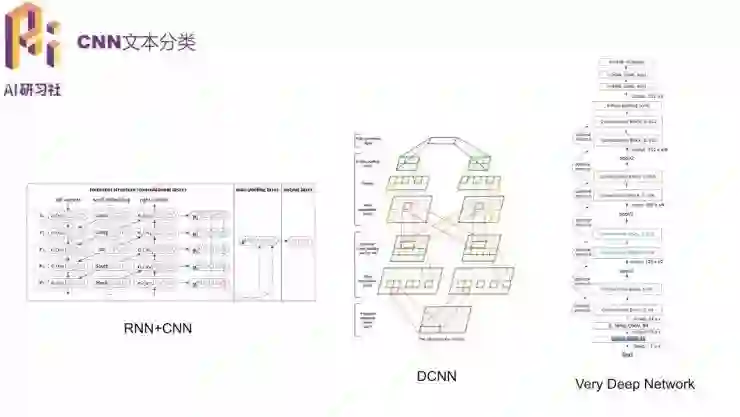
在基础的 CNN 之上,可以在其中不同的层使用不同的思路,衍生出来 RNN+CNN、DCNN(动态池化,更适合不同长度的文本)、Very Deep Network 等等。
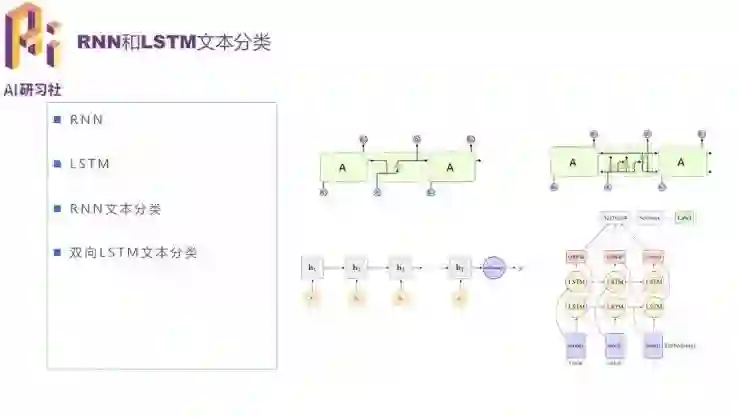
常用的方法还有 RNN 和 LSTM,适合变长序列的建模。序列过长的时候,一般的 RNN 因为容量的问题会丢失信息、误差增大,它的变种 LSTM 中通过三个门之间的信息保留和更新,更好地解决了长距离依赖的问题。双向 LSTM 同时有正向和反向的部分,可以同时捕获上文和下文的信息,表现也比单向的更好。
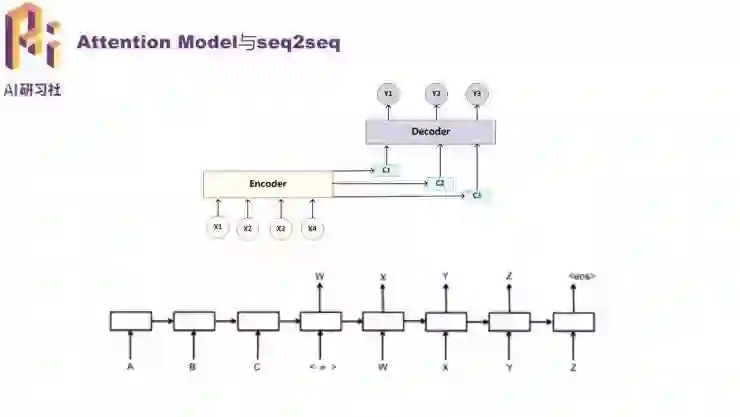
然后就是近期风靡的注意力模型,是编码解码器的升级版本。Encoder-Decoder 模型的问题是,输入中的每个词都对输出有同样程度的影响。但实际语言中往往不是这样的,注意力模型就可以对输入中的不同词赋予不同的权重,让对语意影响程度更高的词语对输出有更高的影响力,从而在输出中更好地体现了输入的关键信息。

张健最后结合达观数据的业务介绍了一些 NLP 的应用案例。

比如结合定制行业专业语料、垂直语意模型、离线统计、语意拓展等等方法进行新闻分类,结合无监督预训练 + 持续 Fune Tuning 的训练方法,不仅可以分为新闻、财经、科技、体育、娱乐、汽车等大类,财经中股票、基金、外汇,体育中 NBA、英超、中超等细分类别也可以分得出来。
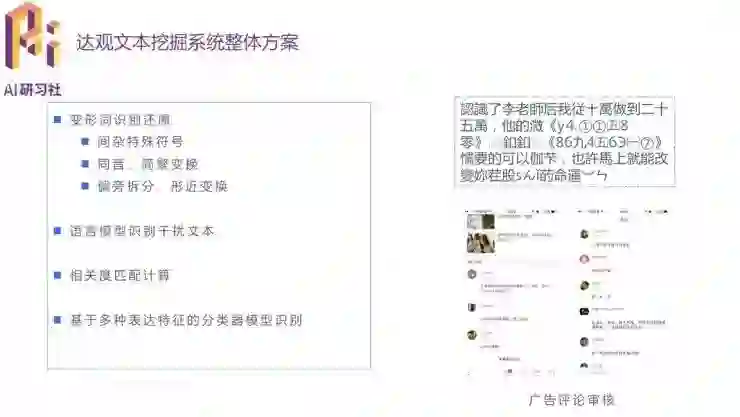
第二个案例是垃圾信息识别。现在许多广告信息都会用特殊字符(火星文)尝试骗过识别系统,就需要对变形词做识别还原,方法包括去除特殊符号、同音和繁简变换、偏旁拆分等。还可以先用语言模型识别文字,发现语意不通顺、胡言乱语的,就很有可能是故意规避关键字检查的垃圾信息。
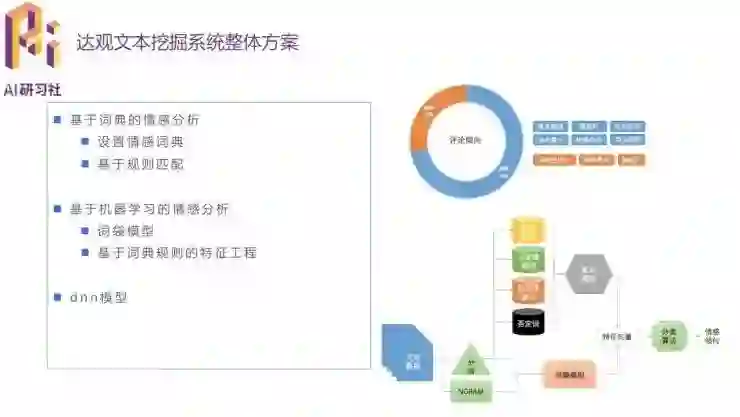
第三个案例是情感分析。简单的方法可以根据直接表达感情的关键词做判断,还可以做特征工程然后用机器学习的方法识别语句模式,以及用深度学习的方法得到更好的信息提取效果。

最后张健还分享了一个他们的文本挖掘系统的使用链接,感兴趣的读者可以尝试一下他们系统不同层次的丰富功能。


新人福利
关注 AI 研习社(okweiwu),回复 1 领取
【超过 1000G 神经网络 / AI / 大数据,教程,论文】
CNN 中千奇百怪的卷积方式大汇总
▼▼▼





