CVPR2022 | 北交大提出EDTER:基于Transformer的边缘检测
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
作者:小海马 | 已授权转载(源:知乎)编辑:CVer
https://zhuanlan.zhihu.com/p/488148078

EDTER: Edge Detection with Transformer
代码:https://github.com/MengyangPu/EDTER
论文:https://arxiv.org/abs/2203.08566
卷积神经网络通过逐步探索上下文和语义特征,在边缘检测方面取得了重大进展。然而,随着感受野的扩大,局部细节逐渐被抑制。最近,vision transformer在捕获远程依赖方面表现出了出色的能力。受此启发,我们提出了一种新的基于变换器的边缘检测器,边缘检测变换器(EDTER),通过同时利用完整的图像上下文信息和详细的局部线索来提取清晰清晰的对象边界和有意义的边缘。EDTER分两个阶段工作。在第一阶段,使用全局转换器编码器在粗粒度图像块上捕获长距离全局上下文。然后在第二阶段,本地transformer编码器在细粒度补丁上工作,以挖掘短程本地线索。每个transformer编码器后面都有一个精心设计的双向多级聚合解码器,以实现高分辨率功能。最后,通过特征融合模块将全局背景和局部线索相结合,并将其输入决策头进行边缘预测。
一、1.Introduction
1.首先介绍一下边缘检测,定义:标识数字图像中亮度变化明显的点。(对像素点分类)
从示例图1可以看出,边缘检测的信息包含物体的轮廓(比如杆,马和人的轮廓),也包扩衣服上的花纹等一些细致的线索。边缘检测与 图像语义和上下文的线索密切相关。捕捉高水平和低水平的视觉线索对边缘检测是至关重要。

2. 介绍一下目前的边缘检测算法的现状-引出论文解决的问题
传统的边缘检测方法:Canny算子,Sobel算子,Laplace算子 等,这些算法大多是基于低水平的局部线索(例如颜色和纹理)获取边缘。
CNN卷积神经网络的方法:得益于卷积神经网络(CNN)在学习语义特征方面的有效性,边缘检测取得了重大进展。CNN的特点是随着感受野的扩大,逐步捕捉全局和语义的视觉概念,同时许多重要的细节不可避免地逐渐丢失。如图2所示,从左到右表示浅层到深层的特征。
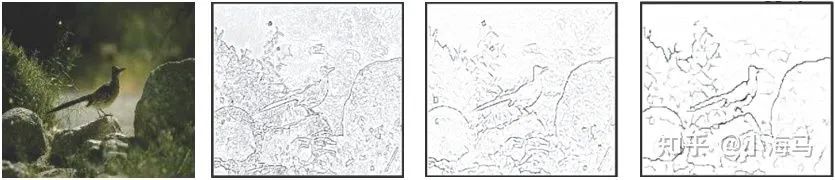
动机一:浅层信息没有考虑上下文的信息
目前的深度学习边缘检测算法都是基于CNN的,为了包含图像的细节和局部信息通常是融合深层和浅层的特征。比如、、、、(近几年的边缘检测的顶会)但是这些浅层信息是主要是反映了图像局部的强弱变化,并没有考虑上下文的信息。(我们都知道CNN再做卷积的时候感受野是逐步扩大的,再浅层也就是前几层卷积的感受野很小,根本拿不到全局的上下文信息,或者说只能拿到局部的上下文信息。)作者提出使用Transformer架构提取特征,在该架构中图像切片进去网络中,由于特有的q、k、v机制 ,在浅层就可以拿到全局上下文的信息。也就是说 Transformer的浅层块中,就可以提取到带有全局上下文信息的浅层特征。
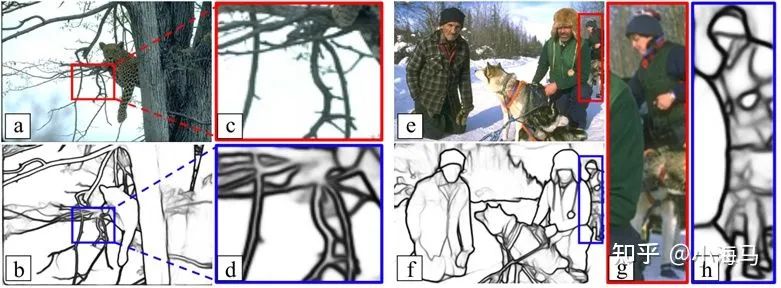
动机二:边缘检测方向常见的问题(如图3所示):从相交的、薄的物目标中提取精细的边缘是一项挑战。目前的transformer,为了节省计算资源通常是16*16的大patch,粗粒度的切片,不利于学习精细的边缘特征。作者提出设计一种细粒度的编码器在不增加过多计算资源,同时设计一种解码器对 编码器生成的边缘感知高分辨率特征解码。
二、Flow chart
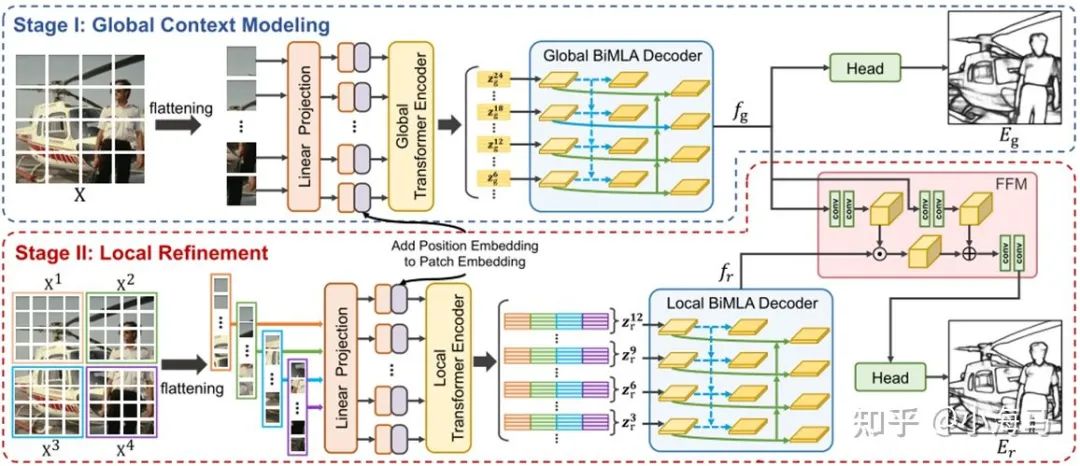
首先看这张网络结构图,网络分为两个阶段Stage Ⅰ用来探索全局上下文信息;Stage Ⅱ局部优化,挖掘局部区域的细粒度线索。网络结构重要是参考了1、2021年CVPR Transformer语义分割的SETR《Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspective with Transformers》地址;2、2018 CVPR 超分辨率重建GAN的《Recovering Realistic Texture in Image Super-resolution by Deep Spatial Feature Transform》地址

本文的主要工作是1.改进SETR中的解码器模块,2. 运用Feature Fusion Module特征融合模块,FFM将全局上下文作为先验知识,对局部上下文进行调制,生成包含全局上下文和细粒度局部细节的融合特征。(其实是使用的一篇超分的论文的空间特征换坏模块)。
三、 Method:
1.BiMLA Decoder
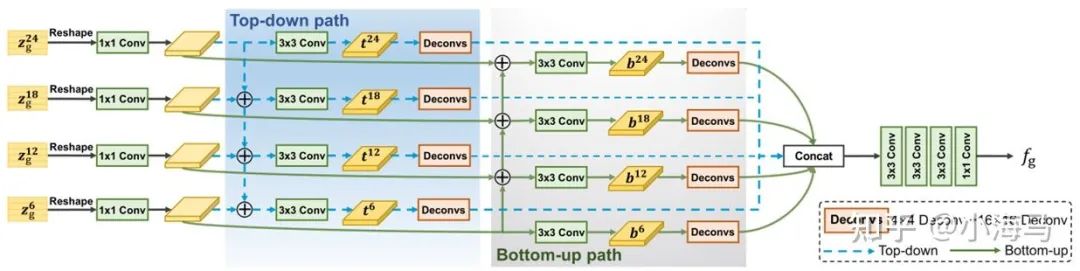
解码器根据SETR的自顶向下的结构,修改为双流解码器,自顶向下和自底向上相结合。自顶向下(从深层信息向浅层融合,可以让边界轮廓越来越清晰去点渐层的杂乱的背景;再从浅层向深层融合可以为深层特征补上轮廓不全、有间断的信息。)
2.Feature Fusion Module
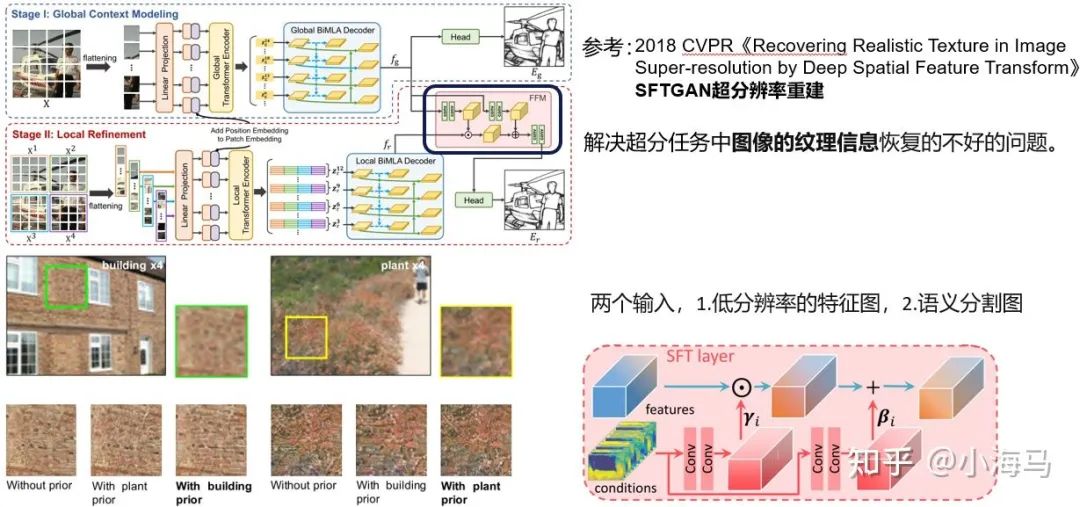
理解特征融合层才能理解两阶段的含义,借鉴了(超分辨率重建的一篇2018CVPR)空间特征变换层。这篇主要的思想大概说一下,在超分辨率任务中,其实就是对原图像的不同类别的目标进行上采样,解决超分任务中图像的纹理信息恢复的不好的问题。
以下面这幅图为例:墙壁和草地的颜色和纹理都很接近,这两个类别低分辨率的rgb值是很相似的,那么在上采样的时就,模型就很难区分当前图像的片断属于哪一个类别,从而导致合成的图像的纹理不真实。超分中的这个模块使用先验类别信息来解决超分辨率纹理不真实的问题。语义分割图作为先验知识的条件,添加到特征图中,就能知道是那个类别然后更好的重建像素。
用到这篇论文的作用是,全局的边缘模糊不精细,但是它可以当作先验知识给出一个大概的边缘的范围,第二阶段在进行局部的优化,因为第二阶段肯定包含的不需要的细节边缘,通过第一阶段的先验知识相当于去掉了不需要的细节,只是优化局部迷糊。(全局特征与局部特征相乘,算是对局部特征加权,可以起到去掉局部特征杂色的作用;全局特征与局部特征相加,不全边缘信息,使轮廓部分特征图响应值更高,更清晰。)
3. Loss function
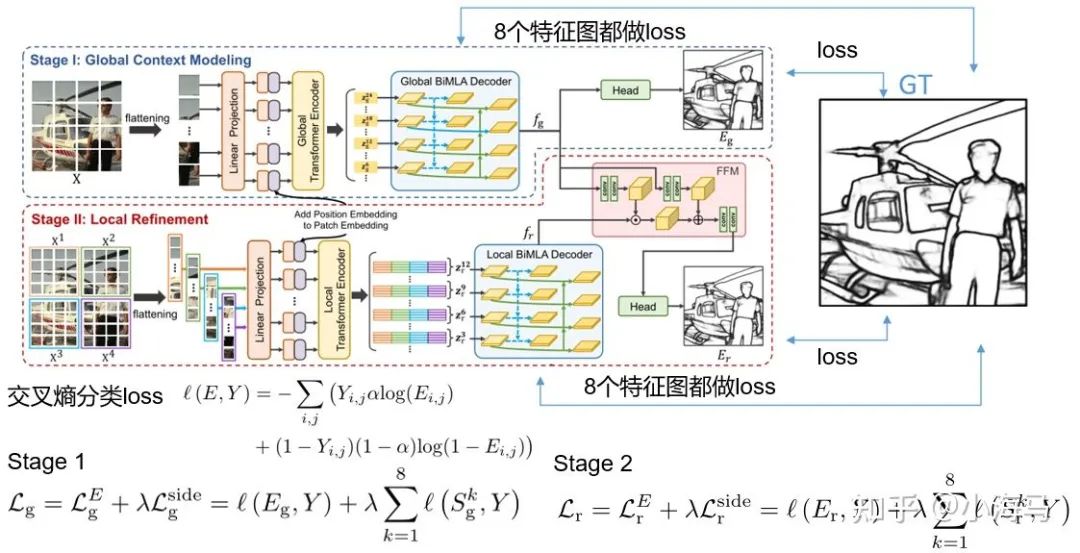
损失函数采用一种:交叉熵分类损失,为图像中每个像素点进行分类,分为(是边缘、不是边缘)两类;沿用边缘检测常用的方式对网络多层级添加损失。训练:先训练第一阶段,预测的 Eg 边缘图与GT做损失+全局双流解码器产生的8张特征图也与GT做损失;当第一阶段训练完成,冻结第一阶段的网络参数,训练第二阶段损失与第一阶段类似,预测的 Er 与GT做损失+局部双流解码器的8张特征图与GT做损失。整个过程与上节超分类似,第一阶段的作用相当与给第二阶段一个先验知识、给第二阶段加权,最后得出局部优化的图像 Er 。预测时只输出 Er 边缘检测图。
四、Experiment
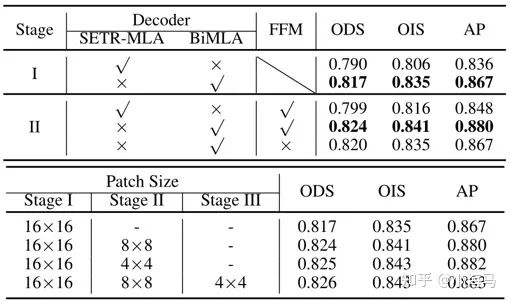
1.消融实验
2.对比实验
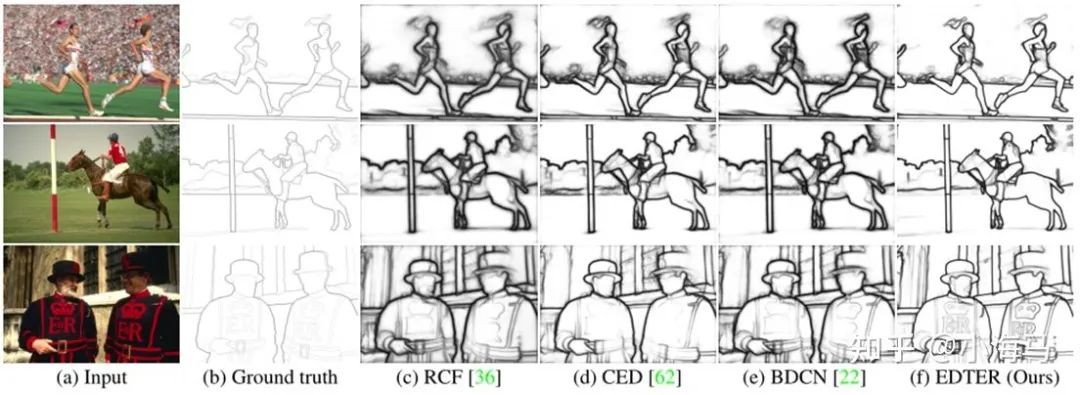
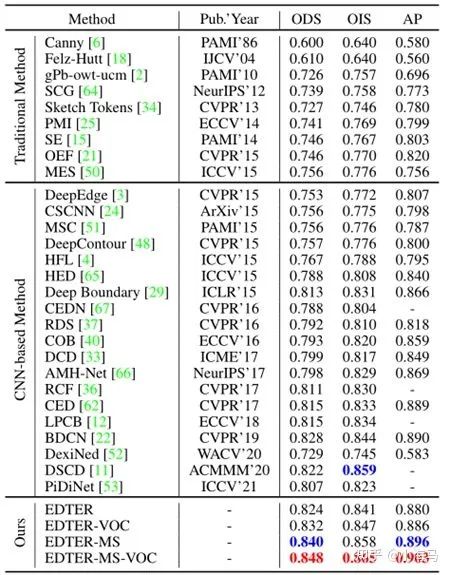
BSDS500测试集上的结果。最好的两个结果分别以红色和蓝色突出显示,其他表格也是如此。MS是多尺度测试,VOC意味着使用额外的PASCAL VOC数据进行训练。
ICCV和CVPR 2021论文和代码下载
后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
后台回复:ICCV2021,即可下载ICCV 2021论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
目标检测和Transformer交流群成立
扫描下方二维码,或者添加微信:CVer6666,即可添加CVer小助手微信,便可申请加入CVer-目标检测或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测或者Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信: CVer6666,进交流群
CVer学术交流群(知识星球)来了!想要了解最新最快最好的CV/DL/ML论文速递、优质开源项目、学习教程和实战训练等资料,欢迎扫描下方二维码,加入CVer学术交流群,已汇集数千人!
▲扫码进群
▲点击上方卡片,关注CVer公众号


整理不易,请点赞和在看


