【速览】TPAMI 2022 | 基于可配置上下文路径的图像语义分割方法
学会“成果速览”系列文章旨在将图像图形领域会议期刊重要成果进行传播,通过短篇文章让读者用母语快速了解相关学术动态,欢迎关注和投稿~
◆ ◆ ◆ ◆
基于可配置上下文路径的图像语义分割方法
*通讯作者:冯伟
◆ ◆ ◆ ◆
语义分割是推断RGB图像中每个像素的对象标签的一个计算机视觉领域的基本任务。语义分割的挑战主要在于外观的变化和像素级别的物体类别的不确定性,因此在像素间交换上下文信息对于使用卷积神经网络解决此类问题就是很重要的。现有的构造上下文路径的方式主要有构造加权路径[1,2,3]和构造增强路径[4]两种,如图1所示。本文提出基于可配置上下文路径的语义分割方法在不同尺度上选取更有效的信息。
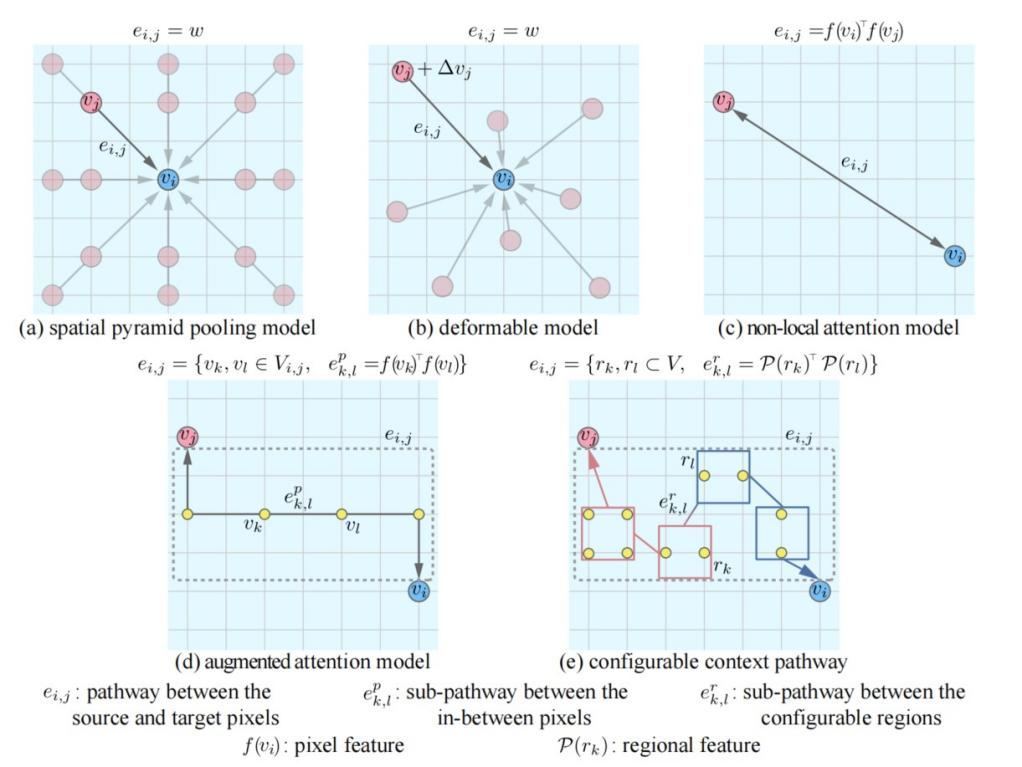
图 1 像素间上下文交换的不同加权路径(a-c)和增强路径(d)方法对比
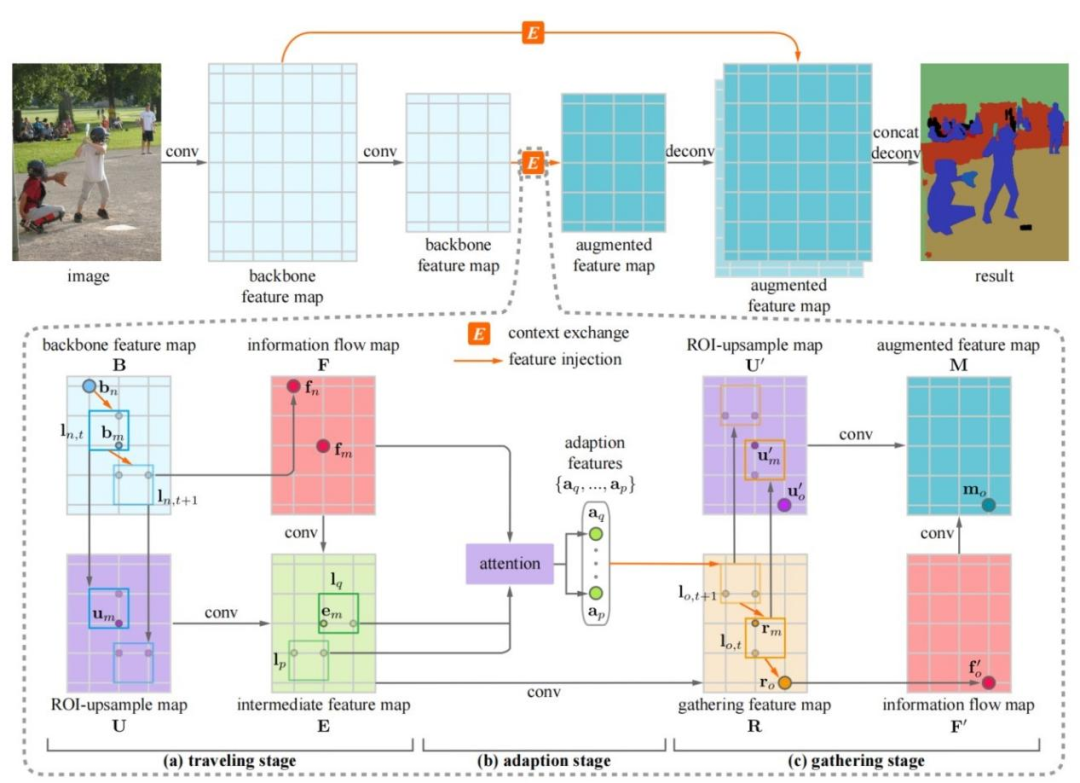
图 2 模型结构图
图2是模型的整体结构图。首先对输入图像进行裁剪和将裁减之后的图像通过骨干网络得到特征图。然后计算上下文路径,并根据这些上下文路径计算得到外观特征图,并根据上下文路径计算特征图,包括三个部分。第一部分为traveling stage,traveling stage中源像素沿着一系列区域移动其深层特征,并产生一个信息流。第二部分为adaption stage,适应不同的信息流,这些信息流通过可配置的融合区域,并合并成更少但更具代表性的信息流。第三部分为gathering stage, 代表性信息流沿着相关区域序列收集在目标像素处,生成信息增强的特征图。然后我们根据融合系数对增强特征图进行融合得到语义特征图
我们以第n和o个像素之间的信息传播为例,简要阐述traveling,adaption以及gathering的计算流程。在traveling stage中,第n个像素的上下文路径计算如下。其中,
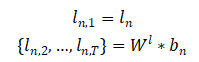
使用上下文路径进行像素信息的traveling的计算如下。 其中,
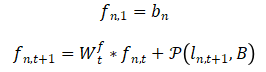
在adaption stage中,我们令
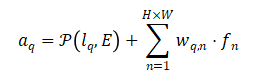
通过adaption的特征向量,我们在gathering stage中增强每个像素的特征向量,计算如下。
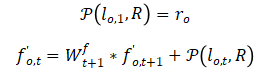
其中,
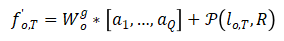
最终,我们将用于第o个像素的分割。
本文在Cityscapes数据集、PASCAL VOC 2012数据集、COCO-Stuff数据集上验证了该方法完成语义分割任务的有效性。其中Cityscapes数据集一共19个语义类别,包含2975张训练图片,500张验证图片,1525张测试图片;PASCAL VOC 2012数据集一共21个语义类别,包含10582张训练图片,1449张验证图片,1456张测试图片;COCO-Stuff数据集一共172个语义类别,分为两个版本:一个版本包含9000张训练图片,1000张验证图片;另一个版本包含120000张训练图片,5000张验证图片。图3、图4和图5分别展示在三个不同的数据集上不同方法的分割效果对比。根据表1中所展示的本方法和已有最优图像语义分割方法在不同数据集上的实验结果表明:无论在室内或室外场景,大规模或小规模数据集,本方法的语义分割效果都要比现有的最优方法要好。
表 1 本方法与现有最优语义分割方法比较

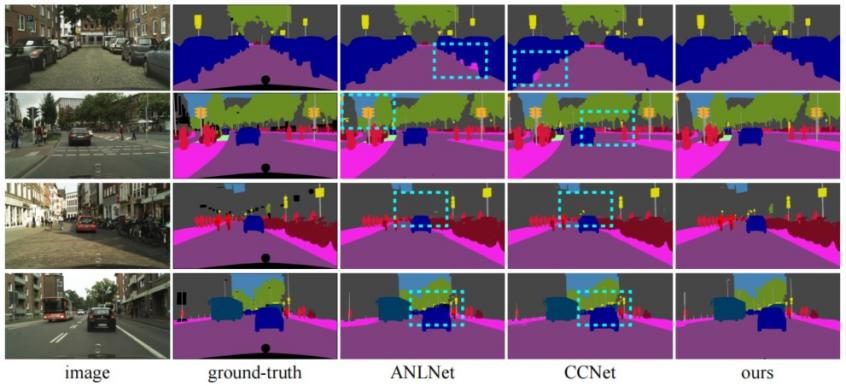
图 3 在Cityscapes数据集上不同方法分割效果对比

图 4 在PASCAL VOC 2012数据集上不同方法分割效果对比
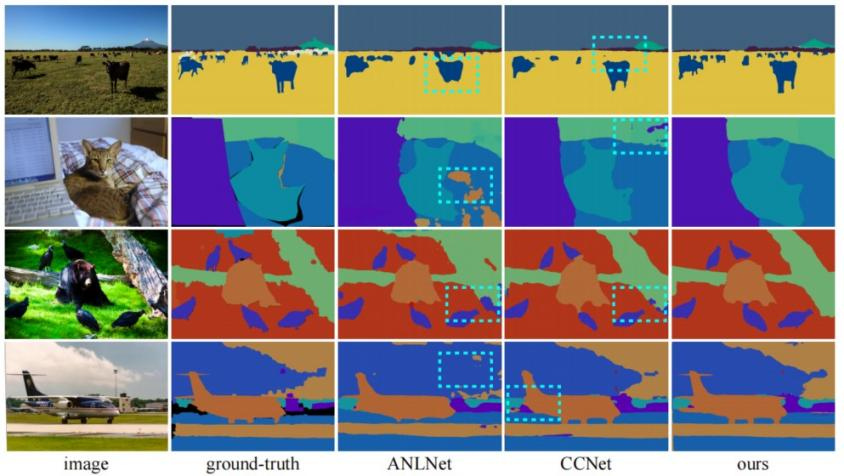
图 5 在COCO-Stuff-10K和-164K数据集上不同方法分割效果对比
图6为TAGNet在Cityscapes数据集上关于可配置上下文路径长度的实验,可以看到在当前实验中T=3达到最佳效果。(T=1表示沿路径没有可配置区域)
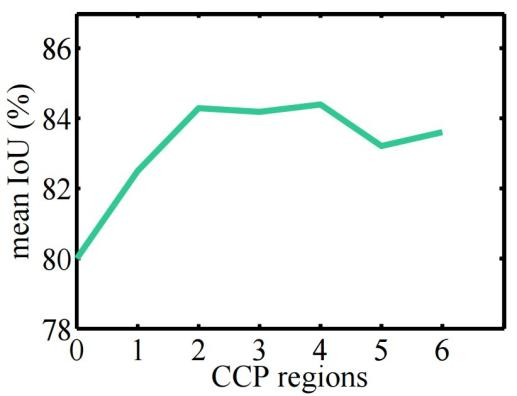
图 6 不同可配置路径长度对比
图7为TAGNet在Cityscapes数据集上关于可配置区域大小的实验,可以看到在当前实验中较大的可配置区域会达到更好的效果,但如果可配置区域过大也可能带来较少的性能提升。
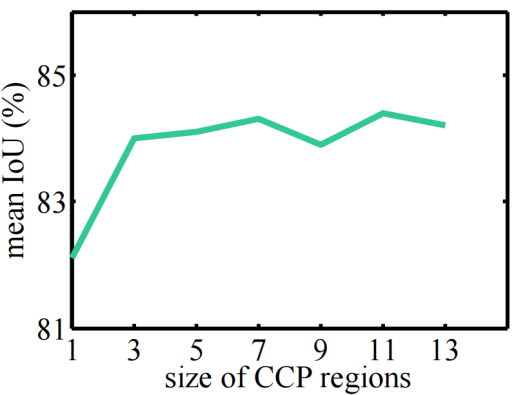
图 7 不同可配置区域大小对比
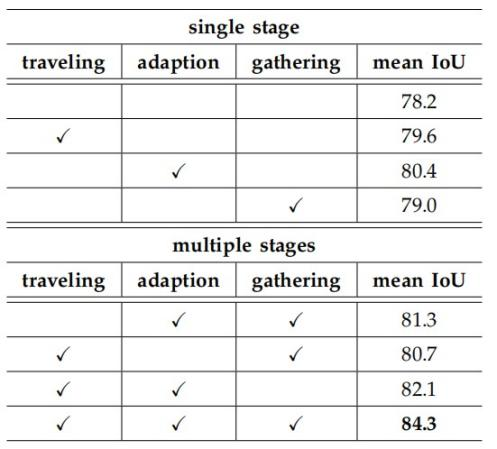
表2为TAGNet在Cityscapes数据集上traveling、adaption、gathering三个模块的消融实验,可以看到三个模块均能给baseline模型带来分割效果的提升。
表 2 消融实验
本文为了解决上下文交换丢失底层细节信息和缺乏灵活性的问题,提出基于可配置上下文路径的图像语义分割方法,并且在Cityscapes数据集、PASCAL VOC 2012数据集、COCO-Stuff数据集上验证了该方法完成语义分割任务的有效性。
[1] L.-C. Chen, G. Papandreou, F. Schroff, and H. Adam. Rethinking atrous convolution for semantic image segmentation. arXiv, 2017.
[2] J. Dai, H. Qi, Y. Xiong, Y. Li, G. Zhang, H. Hu, and Y. Wei. Deformable convolutional networks. In ICCV, 2017.
[3] X. Wang, R. Girshick, A. Gupta, and K. He. Non-local neural networks. In CVPR, 2018.
[4] Z. Huang, X. Wang, L. Huang, C. Huang, Y. Wei, and W. Liu. Ccnet: Criss-cross attention for semantic segmentation. In ICCV, 2019.



