AI居然「暗中」捣乱?港中大深圳联合西安交大发布后门学习新基准|NeurIPS 2022
![]()
新智元报道

新智元报道
【新智元导读】后门学习新基准!BackdoorBench目前已集成了9种攻击方法、12种防御方法、5种分析工具,leaderboard公布了8000组攻防结果!
深度学习的黑盒虽然免去了构造特征的麻烦,但也埋下了一个隐患。
其中一个典型的安全问题是后门学习,它可以通过恶意操纵训练数据或控制训练过程,在模型中插入难以察觉的后门。

目前后门学习的相关研究呈火热之势,但还没有完善的基准用来评估相关工作。
最近香港中文大学(深圳)吴保元教授课题组与西安交通大学沈超教授课题组联合发布了一个后门攻击与防御基准BackdoorBench。

论文链接:https://arxiv.org/abs/2206.12654
代码链接:https://github.com/SCLBD/backdoorbench
项目链接:https://backdoorbench.github.io
截至2022年10月22日,BackdoorBench已集成了9种攻击方法、12种防御方法、5种分析工具,leaderboard公布了8000组攻防结果。
该工作目前已被NeurIPS 2022 Datasets and Benchmarks Track接收。
简介
随着深度神经网络(DNNs)在许多场景中的广泛运用,DNN的安全问题已经引起了越来越多的关注。
如果用户从第三方平台下载未经验证的数据集/checkpoint来训练/微调自定义的模型,甚至将模型训练过程直接外包给第三方平台,后门攻击会对这类用户产生极大的威胁 。当后门模型输入正常样本时,会预测出正确的结果;但是一旦后门模型遇到被故意篡改的样本时,则会输出恶意的结果。
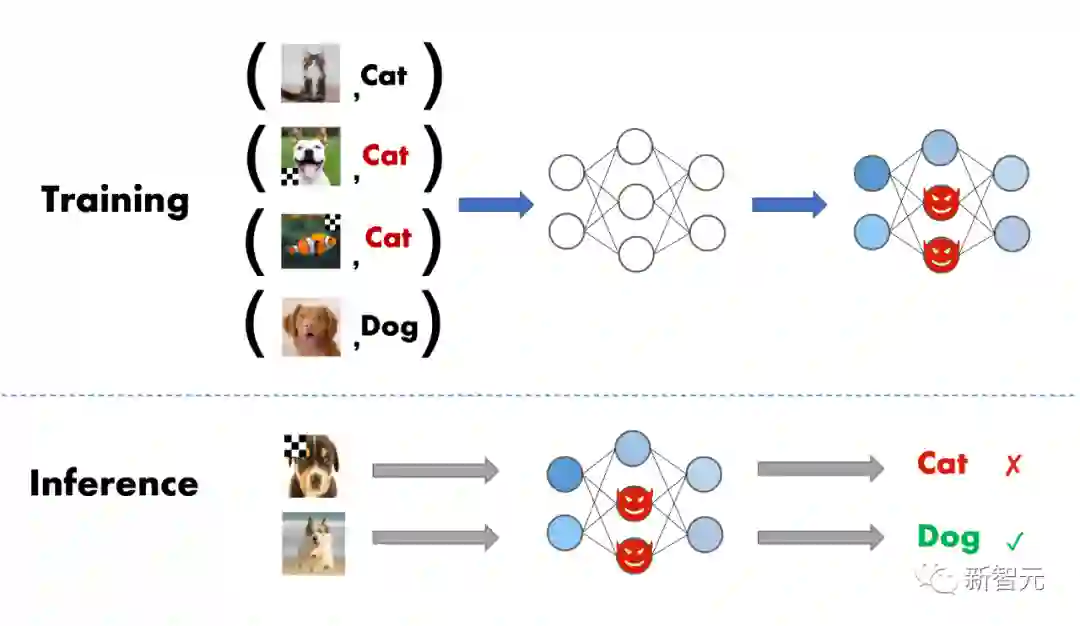
虽然后门学习在机器学习领域是一个新型的研究方向,但其发展速度惊人,并呈现出快速军备竞赛的态势。
然而,我们注意到很多新方法的评估往往不够充分,通常其论文中只会对比一小部分方法/模型/数据集。如果没有完整的评估和公平比较,则很难验证和评估新方法的真实性能,并且会阻碍对后门学习的内在原理的探索。
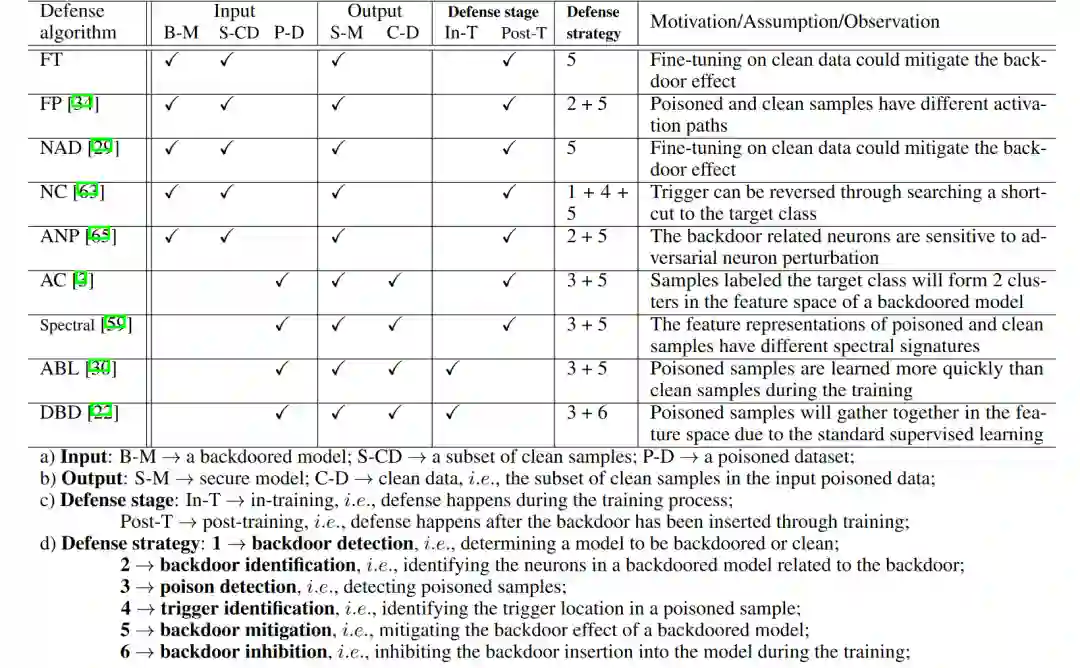
为了缓解这种困境,我们建立了一个全面的后门学习基准,称为BackdoorBench。它由输入模块、攻击模块、防御模块以及评估和分析模块组成。
到目前为止,我们已经实现了9种SOTA的后门攻击和12种防御方法,并提供了5种分析工具(t-SNE、Shapley value、Grad-CAM、Frequency saliency map、Neuron activation)(更多方法和工具将不断更新)。
此外,我们在5种DNN模型和4个数据集上,对其中的8种攻击和9种防御方法、设置了5个投毒比例进行了综合评估,因此总共进行了8000次攻防实验。在实验结果的基础上,我们从方法、投毒比例、数据集、模型、泛化性、记忆与遗忘等多个角度进行了分析。
BackdoorBench最新版本还集成了ViT、ImageNet、NLP等模型和数据集。
框架介绍
框架介绍
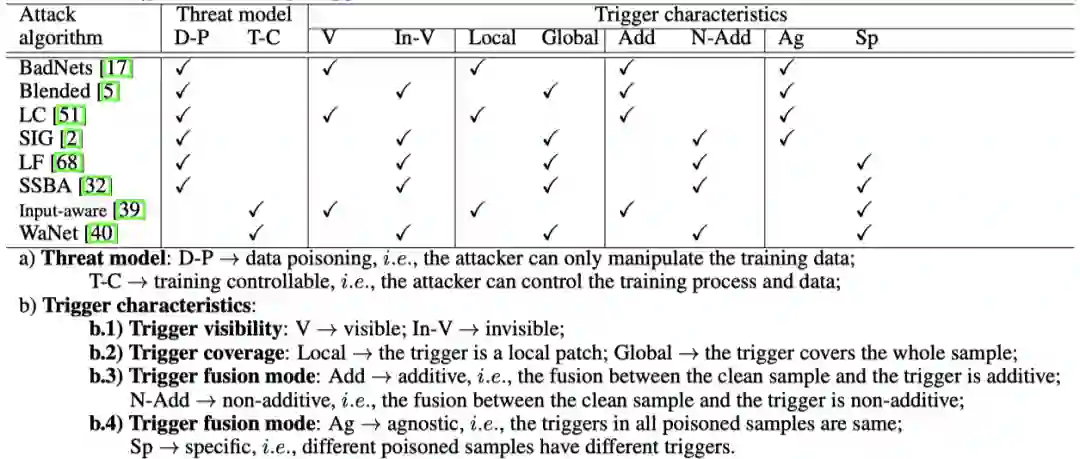
BackdoorBench目前已经集成了主流的9种攻击和12种防御算法,目前已经进行完整测试的攻击和防御方法如下图所示:
代码框架如下所示。
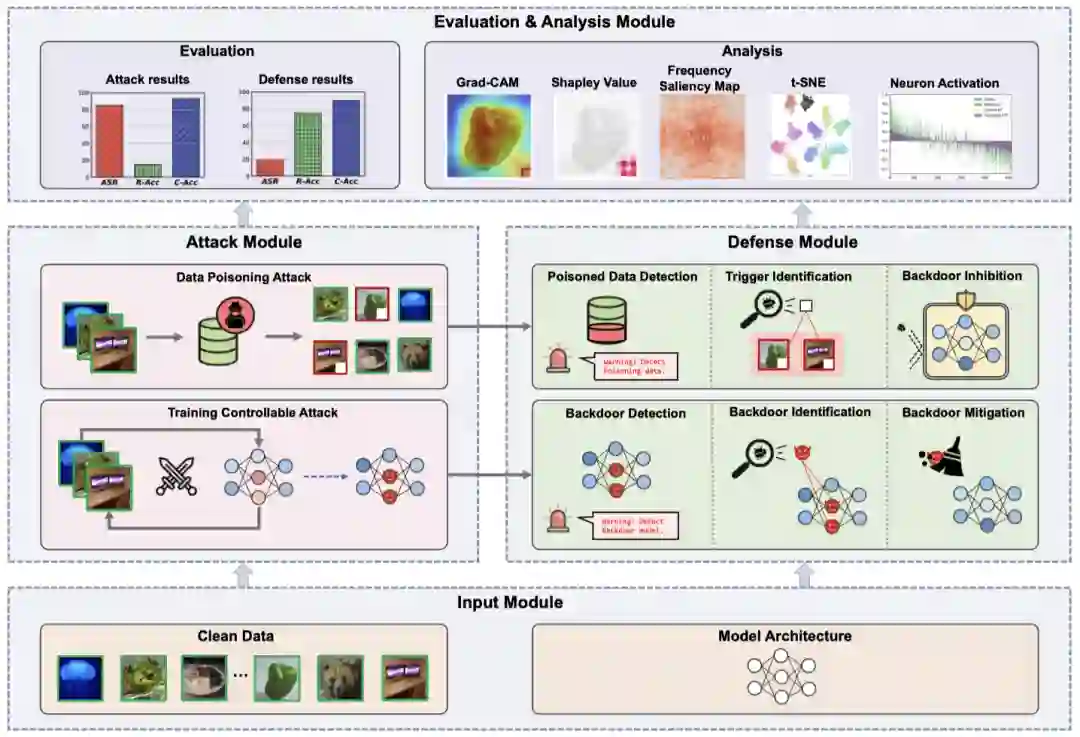
整体上来说,我们的框架包含四个部分:
1、输入模块:主要负责数据读取、预处理以及不同模型的构建。
2、攻击模块:可进一步分为数据投毒和控制训练过程投毒两个子模块,前者输出被投毒的数据集,而后者则是输出训练好的后门模型。
3、防御模块:接收攻击模块的输出,为投毒数据集提供了投毒样本检测、后门定位和后门抑制等防御方法;为后门模型提供了后门检测、后门神经元定位、后门消除等防御方法。
4、评估和分析模块:除了传统的准确率(C-Acc)和攻击成功率(ASR)之外,还引入了R-Acc作为鲁棒性的评测标准,通过计算投毒样本被分类成原始类别的比率来衡量模型的鲁棒性。此外,框架中还包含了五种分析工具来帮助理解后门,分别为:t-SNE、Grad-CAM、Shapley Value、Frequency saliency map和Neuron activation。
实验结果分析
实验结果分析
实验设置
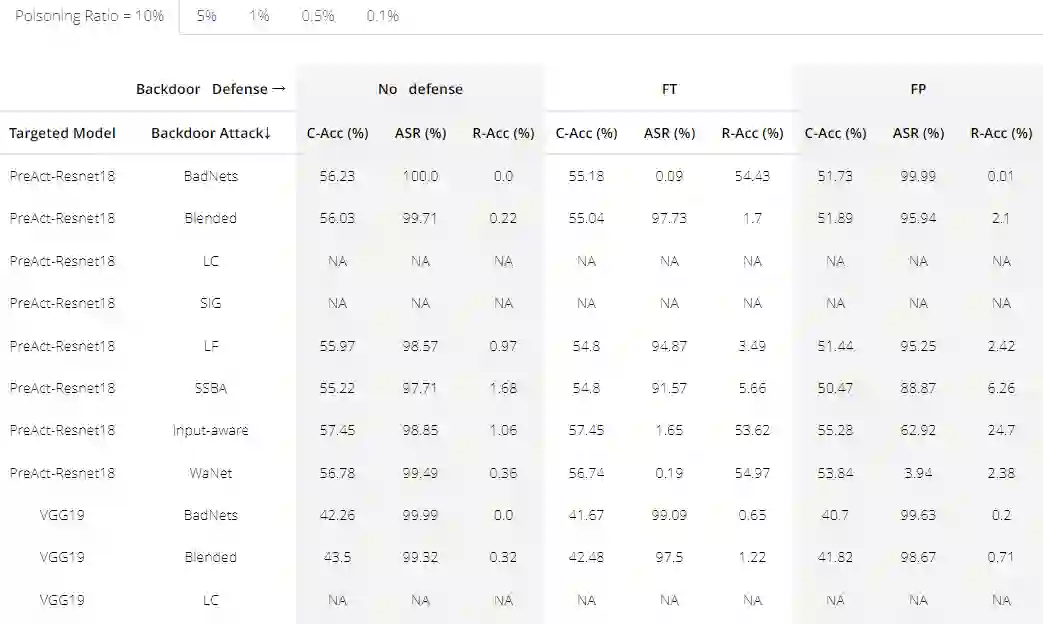
研究人员在4个数据集(CIFAR-10、CIFAR-100、GTSRB、Tiny ImageNet),5个模型结构(PreAct-ResNet18, VGG19, EfficientNet-B3, MobileNetV3-Large, DenseNet-161),8个攻击,9个防御,5个投毒浓度(0.1%、0.5%、1%、5%、10%)下进行了实验(正常的训练流程,考虑到普适性没有使用复杂的预处理)。
实验结果中ACC是模型准确率的缩写,ASR是投毒样本被模型分为目标类的比例,R-Acc是投毒样本被模型分为原标签的比例。
整体效果
在固定投毒比例和网络结构的情况下对攻防的整体的效果进行了可视化,结果如下所示。
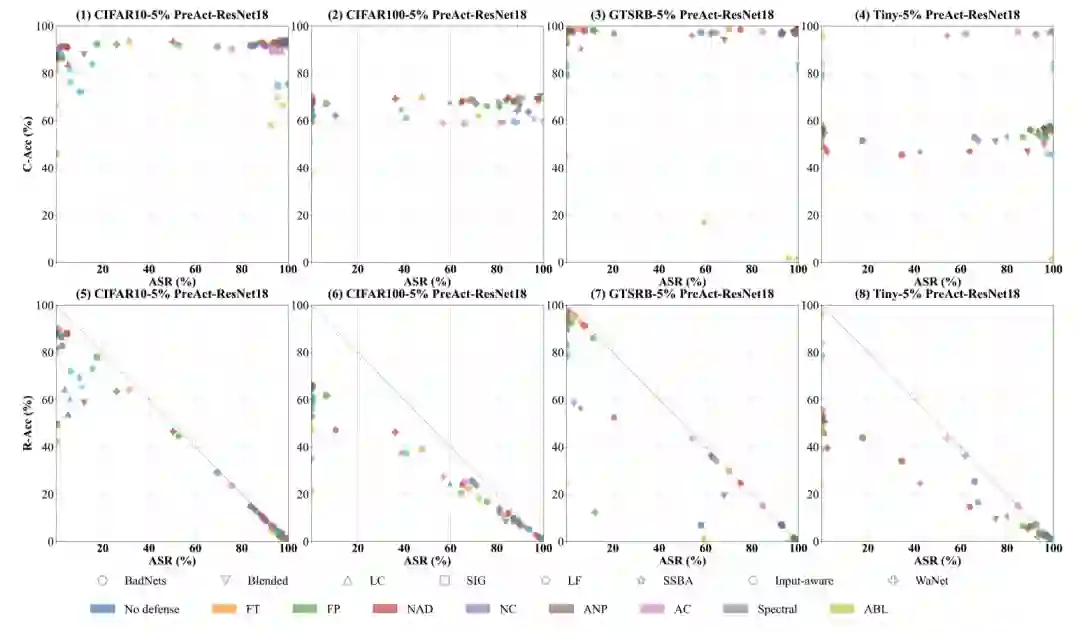
第一排的图用C-Acc vs ASR作为坐标,攻击者和防御者都希望点落在较高的区域,但是攻击者希望能尽量落在右上角而防御者则是希望落在左上角。实际情况是大部分的点都是在同一水平线上,说明部分防御方法都能在不太影响模型自身准确率的情况下抑制后门模型的影响。
第二排的图则是用的R-Acc vs ASR,根据定义出发可知他们二者和最大为1,从防御者的角度来说,自然是希望被恢复的模型能将大部分样本转为正确的分类,也就是靠近反对角线的情况。
从图中可以看出,仅仅在CIFAR10、GTSRB上大部分的点能靠近反对角线,在CIFAR100和TinyImageNet两个更加困难的数据集上则大部分的点都偏离了反对角线,意味着大部分攻击方法经过防御后,投毒样本并没有被重新分对,仅仅是不再被分为目标类而已。
投毒比例的影响
如下图所示,研究人员在不同的投毒比例下记录了攻防后的ASR。
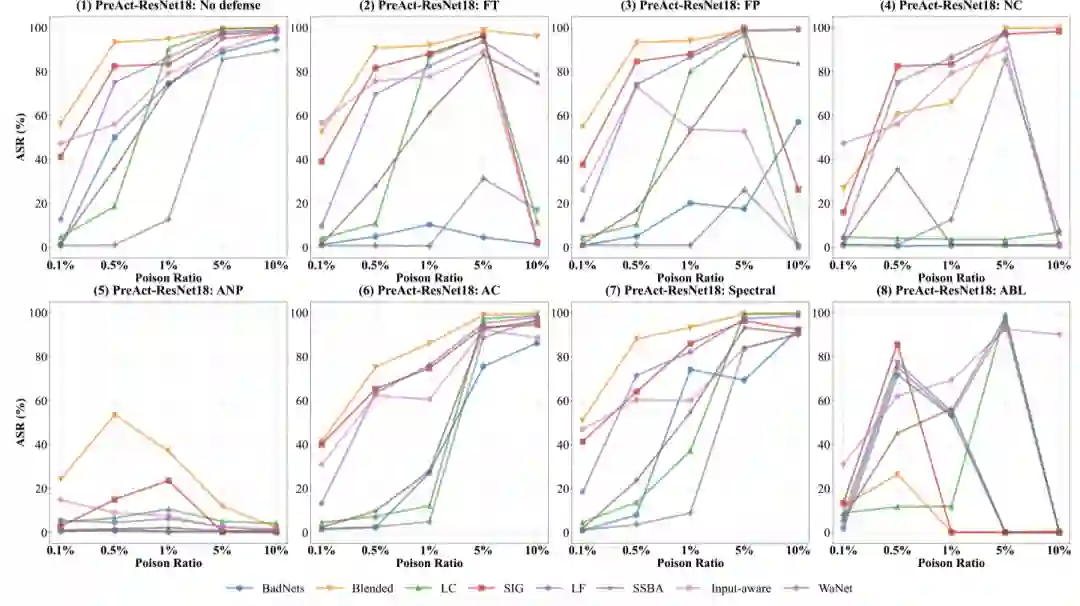
整体上来说实验反映了一个有趣的点:并不是浓度越高攻击效果越好。
可以明显观察到不少的攻击在浓度提升到一定比例后都会造成防御后的ASR下降,也可以认为这是高浓度的攻击样本带来了较大的干净/投毒样本差异造成的,所以对于后门攻防来说,在低投毒浓度下保持攻击性能/抵御攻击将成为一个重要的方向。
模型结构的影响
如下图所示,研究人员对不同的模型结构记录了攻防后的ASR。
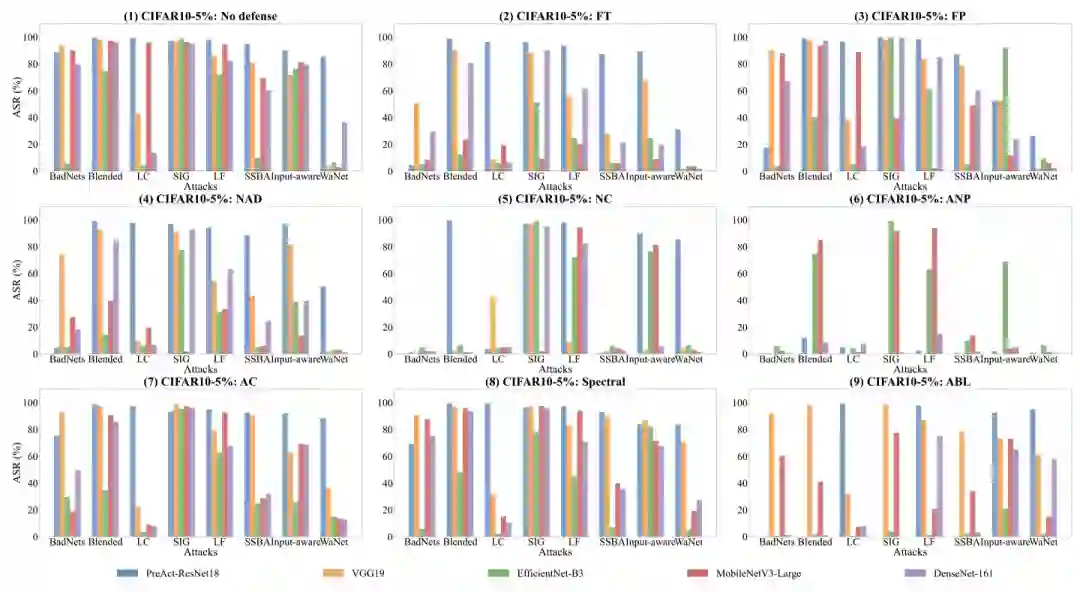
总体上来说,我们的实验结果表明同种攻击和防御方法可能会在不同的模型结构下有完全不一样的效果。所以未来探索模型结构对后门的影响/设计鲁棒的模型结构也非常重要。
不同数据集的影响
从无防御的角度下看,我们可以看到,大体上,攻击的效果在不同的数据集上是波动的。
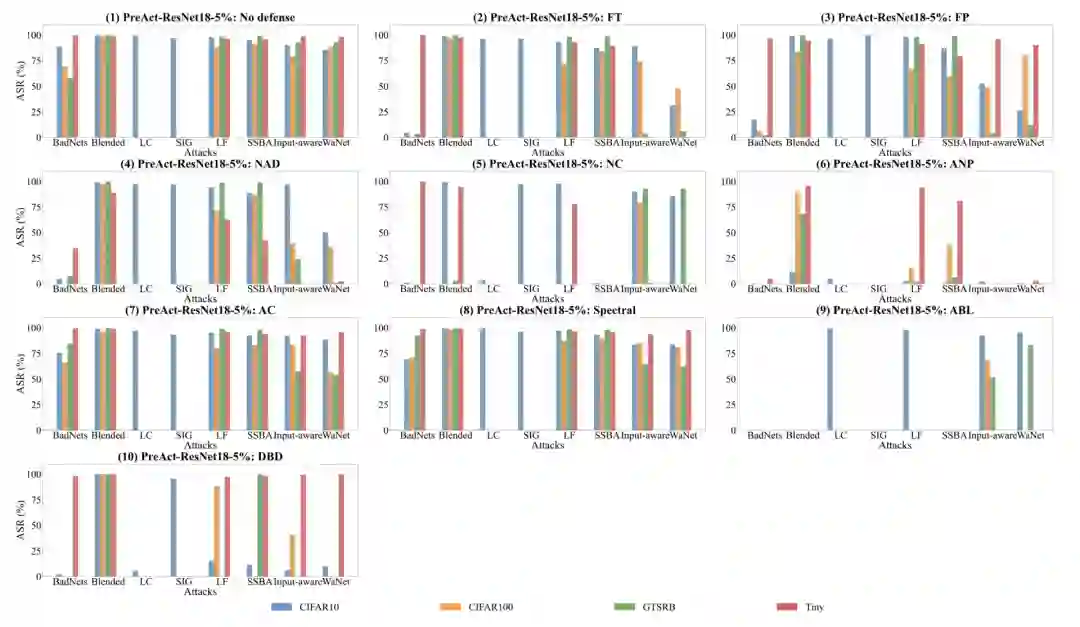
Blended在不同的数据集中是最稳定的,而BadNets在不同的数据集中具有最波动的效果。
对于BadNets,我们发现CIFAR-100和GTSRB比CIFAR-10更复杂,这导致了在这两个数据集上的效果下降,但是由于trigger大小的扩大,Tiny ImageNet上的ASR明显反弹了。
从不同的防御角度来看,我们可以发现,AC和Spectral Signature这两种方法与其他方法相比,相对不受数据集变化的影响,但是效果也较为一般。
相比之下,其余的防御方法在面对具体的攻击时,其效果都可能有较大的波动。虽然有波动,但ANP在CIFAR-10上对所有攻击方法都有较好的效果,而ABL在Tiny ImageNet上对所有攻击方法也非常有效。
可视化
对于不同的攻击方法和防御方法,,一些简单的可视化效果如下图所示:
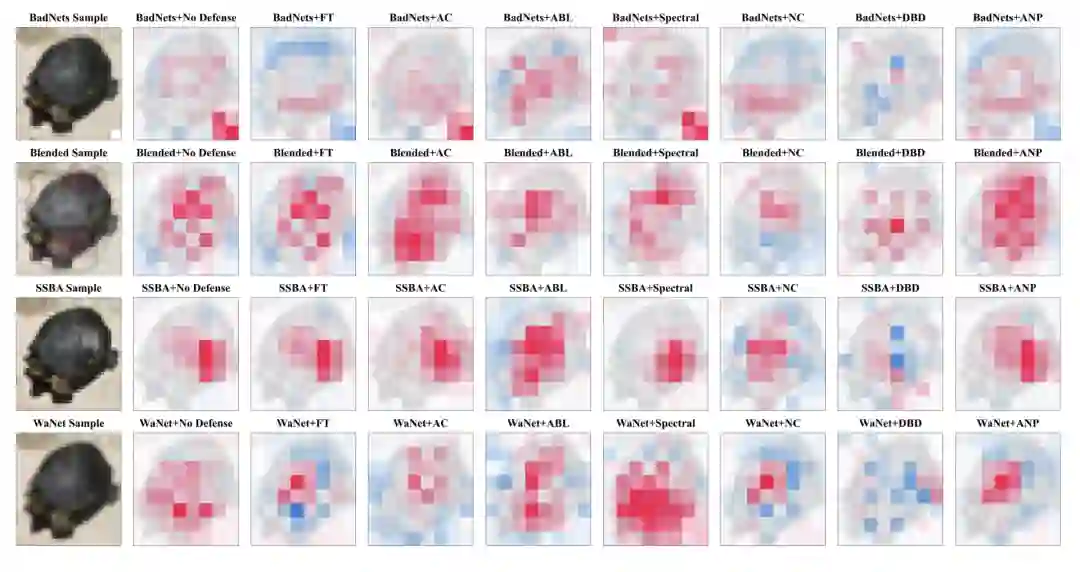
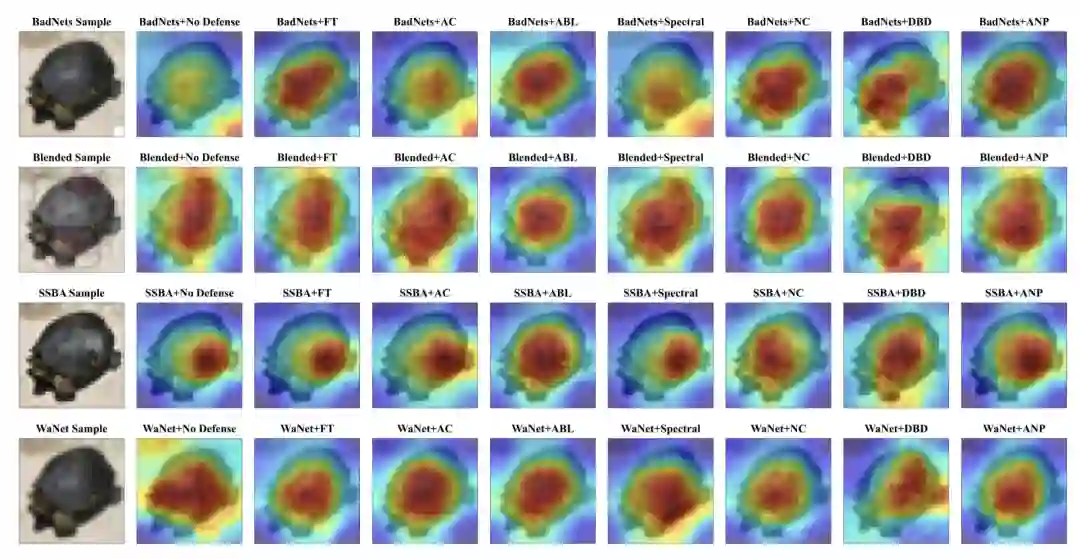
早生成性的探索
除了攻防实验,我们也对后门攻击中广泛存在的早生成现象做出了探索。具体来说,我们收集了攻击早期的五个指标,包括损失函数(Loss),准确率(Accuracy)、梯度信噪比(GSNR)、样本梯度模长(Gradient Norm)和样本梯度间的余弦相似度(Cosine Similarity),并对部分攻击进行了实验,结果如下图所示:
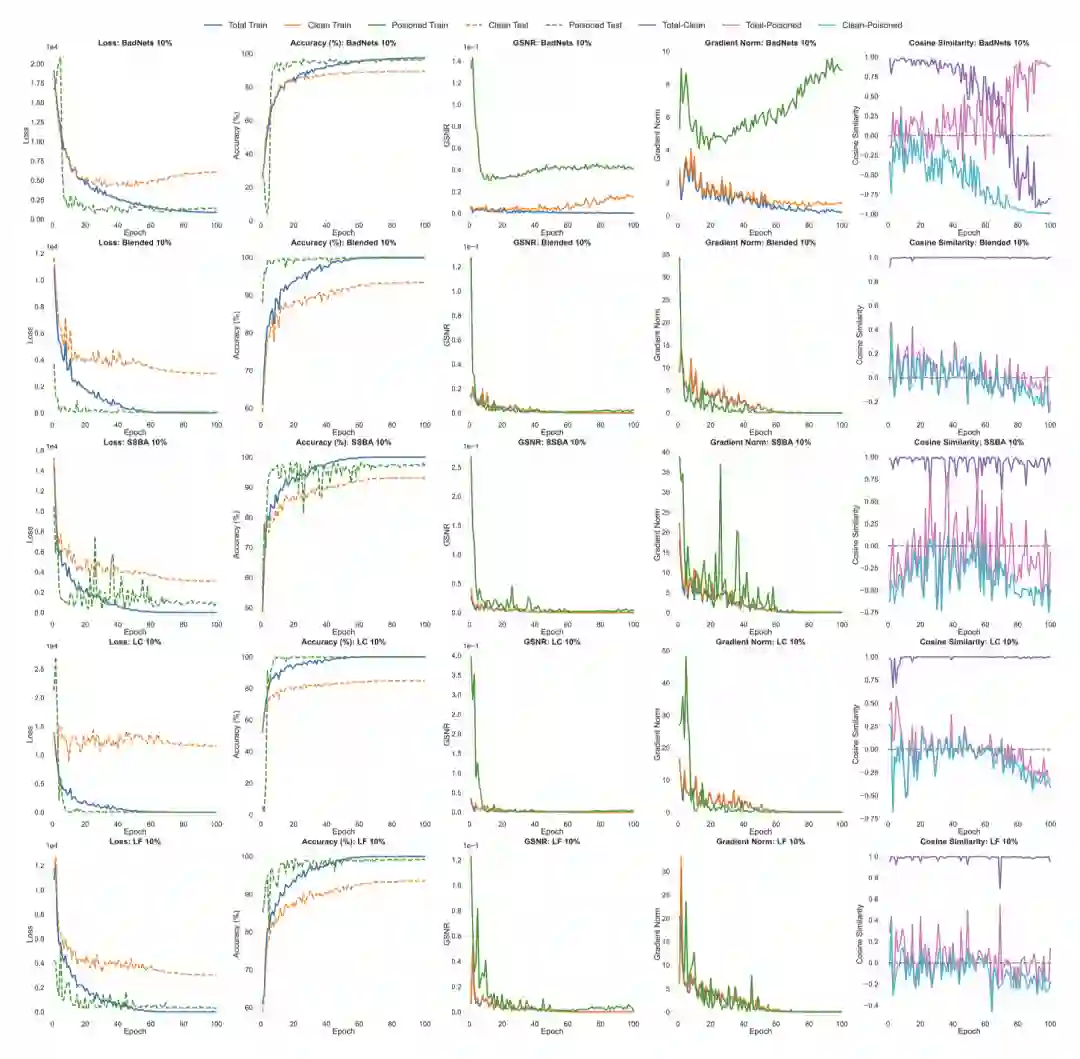
首先,如第一列所示,中毒样本的损失函数在训练的早期阶段迅速下降,并收敛到一个低值,而干净样本的损失函数下降速度较慢且最终收敛到了一个更大的值。这个结果表明后门的早生成现象广泛存在于上述实验中。
为了解释这样的现象,我们首先观察到在训练的早期阶段,中毒样本的梯度信噪比明显大于干净样本的梯度信噪比 (如第三列所示)。中毒样本的高梯度信噪比表明,后门具有更好的泛化性能,这与中毒测试样本上更高的准确性(ASR)和更低的损失函数是一致的。
其次,在训练的早期阶段,中毒样本上的梯度模长比干净样本上的梯度模长大得多 (如第四列所示)。与之对应,总训练样本梯度和中毒训练样本梯度的余弦相似度明显大于干净训练样本梯度和中毒训练样本的梯度的余弦相似度,尽管中毒样本的数量远远小于干净样本的数量。
这些现象表明,在训练的早期阶段,中毒训练样本对模型的训练有着明显的影响,这一定程度上解释了后门的早生成现象。
遗忘性的探索
后门攻击有一个非常重要但少有探索的问题——遗忘性。事实上,我们对后门攻击遗忘性的认知影响着我们对攻击和防御方法的设计。因此,我们的文章对遗忘性做出了一些初步探索,并且对BadNets、Blended、SSBA三种攻击方法的遗忘性有了相应的实验结果。
我们采用论文《An empirical study of example forgetting during deep neural network learning》中提出的研究方法,使用遗忘事件的数量来衡量后门的遗忘性,我们的结果如下图所示:
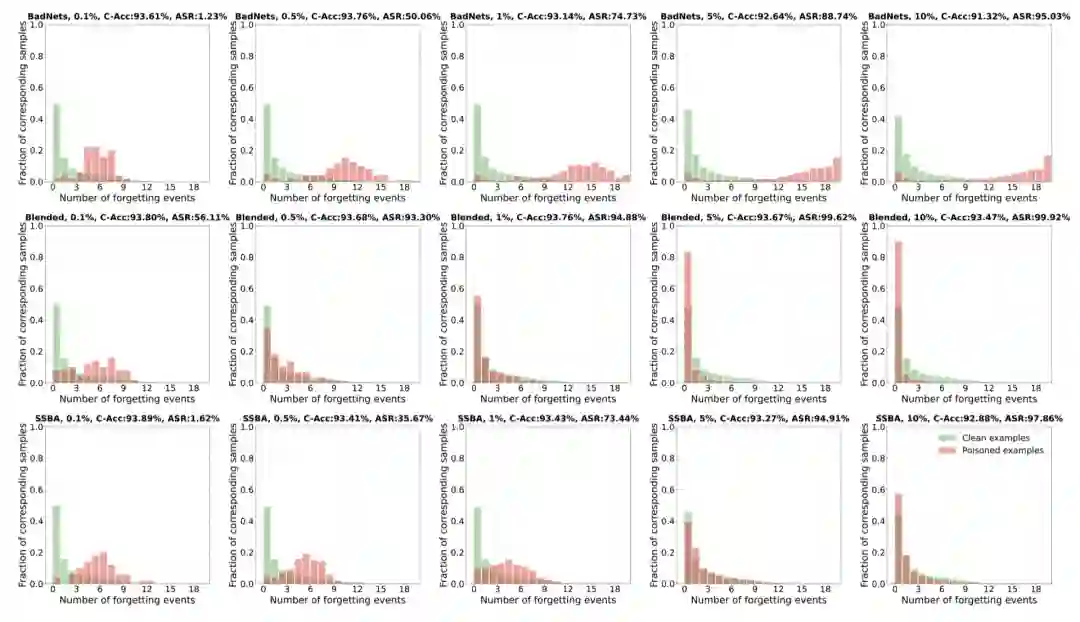
我们发现:
1. 干净训练样本的遗忘事件遵循指数分布,在不同情况下是相似的。
2. 对于中毒的训练样本。
a) 当中毒率较低时(如0.1%,0.5%),中毒样本的遗忘事件往往比干净样本的遗忘事件多;
b) 当中毒率较高时(如5%,10%),中毒样本的遗忘事件往往比干净样本的遗忘事件少。
上述实验结果与我们的观察大致吻合,即中毒率较高的后门攻击可以快速学习从中毒样本到目标类的稳定映射。此外,遗忘性的评估实验中提供了一个精细的工具来分析每个单独的训练样本的贡献,这可以促进开发更先进的后门攻击和防御方法。
总结
总结
我们为后门学习建立了一个全面且最新的基准,采用了基于模块化的可扩展代码结构,实现了9种后门攻击和12种后门防御算法。此外,我们还提供了可用于分析、评估后门攻击和防御的可视化工具,并且已对8000组攻防对做出了深入的评估和分析。
我们希望这个新的基准能够在以下几个方面为后门社区做出贡献:提供更清晰的后门学习当前进展情况;方便研究人员在开发新方法时快速与现有方法进行比较;从对后门综合剖析中启发新的研究问题。



