ICLR 2020丨V4D:视频级别表示学习的四维卷积神经网络


论文地址:https://arxiv.org/abs/2002.0744
大多数用于视频学习的 3D 卷积神经网络都是 clip-based 的方法,并没有考虑video-level 的时空特征变化。我们提出了视频级别的四维卷积神经网络,简称 V4D,利用四维卷积来建模长距离的时空表示变化,同时利用残差结构来保存三维时空特征。我们进一步地介绍了 V4D 的训练和推理方法。我们在三个视频理解数据集上进行了大量实验,V4D 都取得了很好的结果并超过了 3D 卷积网络。
3D 神经网络及其变体主要用于片段级特征学习,而不是从整个视频中进行训练。在训练期间,基于片段的方法随机地从视频中采样短片段(例如,32 帧)用于表示学习。在测试过程中,它们以滑动窗口的方式均匀地从整个视频中采样多个片段,并独立地计算每个片段的预测分数。最后对所有视频片段的预测得分进行平均,得到视频水平预测结果。在训练过程中,这些 clip-based 的模型忽略了 video-level 结构和远程时空依赖性,因为他们只采样了整个视频的一小部分。同时,在测试过程中,简单地平均所有片段的预测分数也可能是次优的。为了克服这个问题,时间片段网络(TSN)均匀地采样来自整个视频的多个片段,并使用它们的平均得分来指导训练过程中的反向传播。因此,TSN 是一种 video-level 表示学习框架。然而,TSN 中的帧间交互和视频级融合只是在很晚的阶段才进行,无法捕捉到更精细的时间结构。
本文提出了一个通用的、灵活的视频级表示学习框架 V4D,如图 1 所示。V4D 由两个关键设计组成:(1)整体采样策略;(2)4D 卷积交互。我们首先通过引入视频级采样策略,对覆盖整个视频的一系列 short-term 单元进行均匀采样。然后,通过设计 4D 残差块,对长程时空依赖性进行建模。4D 残差块可以很容易地集成到现有的 3D CNN 中,比 TSN 更早和更结构化地进行远程建模。我们还为 V4D 设计了一个特定的视频级推理算法。具体来说,我们在三个视频动作识别基准上验证了 V4D 的有效性: Mini-Kinetics-200、Kinetics-400 和 Something-Something-V1。V4D 结构在这些基准上实现了非常有竞争力的性能,并比 3D CNN 获得了提升。
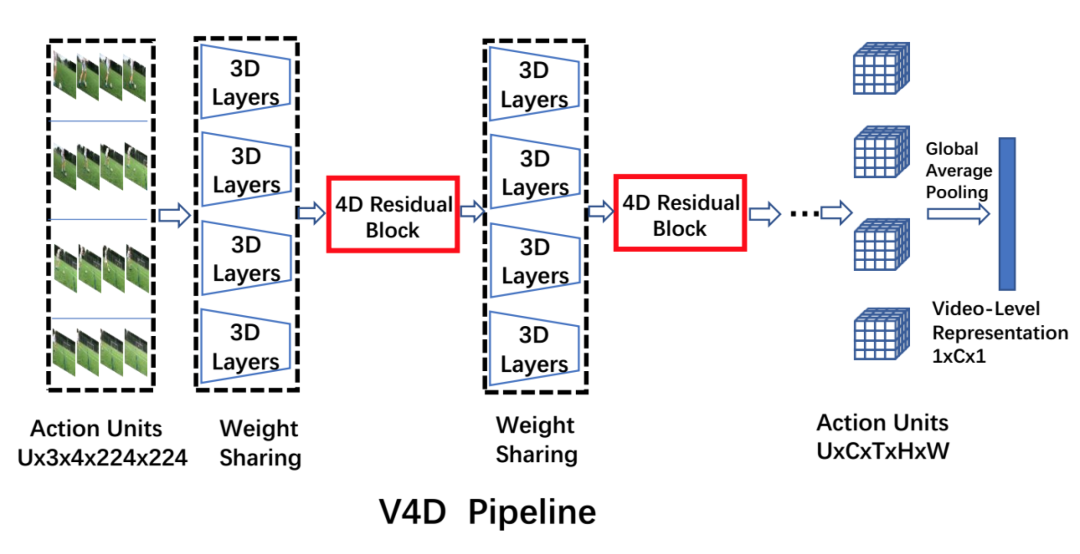
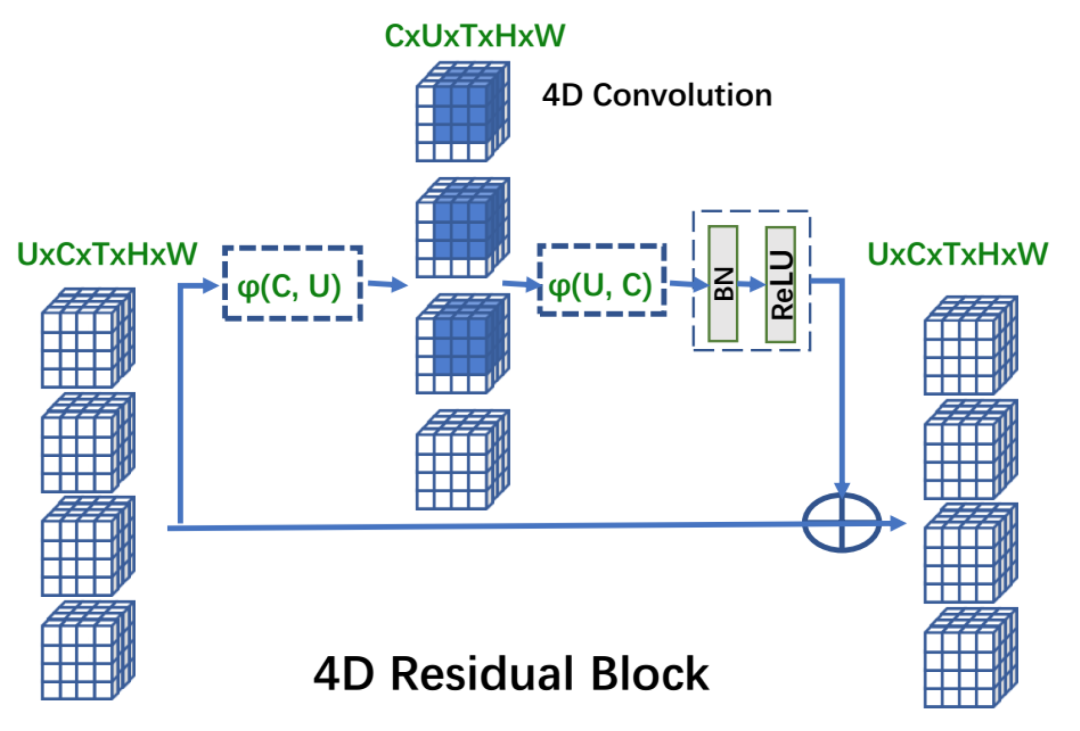
Figure 1: Video-level 4D Convolutional Neural Networks for video recognition.
用于视频识别的体系结构大致可分为三组:双流 CNN、3D CNNs 和长期建模框架。
2.1 双流 CNN
双流架构最早由 Simonyan & Zisserman 提出,其中一个流用于从 RGB 图像学习,另一个流用于建模光流。两个流产生的结果在后期进行融合,得到最终的预测结果。然而,其主要缺点是光流的计算往往需要较长的时间。最近也有一些工作致力于降低模拟光流的计算成本。在视频理解领域,双流输入与融合是一种提高各种结构精度的通用方法,它与我们提出的 V4D 是正交的。
2.2 3D CNNs
3D CNN 经常有较多的参数,需要更多的训练数据来实现高性能。最近在大规模数据集比如 Kinetics-400 上的实验显示了 3D CNN 可以在大多数情况下超过 2D CNN,甚至和双流法相当。然而 3D CNN 中的大多数是基于片段的方法,这意味着在训练阶段他们只探索了一部分视频。
2.3 长期建模框架
目前已经有一些方法开发了长期建模框架,用于捕获更复杂的时间结构。一种方法使用 2D CNN 进行帧级特征提取,用递归神经网络对连续视频帧序列进行运算。而 TSN 利用稀疏采样和聚集从整个视频中提取稀疏的采样帧来学习视频级的表征,最后对这些分数进行平均以生成视频级别的判断。虽然最初设计用于 2D CNN,但是 TSN 也可以应用于 3D CNN,它被设置为本文的基线之一。TSN 的一个明显缺陷是,由于简单的平均聚合,它不能建模更精细的时间结构。
在这一部分中,我们介绍了一种用于视频动作识别的新型视频 4D 卷积神经网络,即 V4D。这是第一次尝试为基于 RGB 的视频识别设计 4D 卷积。现有的 3D CNN 以一个短期片段作为输入,没有考虑三维时空特征的演化来进行视频层的表示。尽管 Nonlocal Network 和 Compact Generalized Nonlocal Network 提出了对非局部时空特征建模的 self-attention 机制,但这些方法最初是为基于片段的 3D CNN 设计的。目前尚不清楚如何将这种操作纳入整体视频表示,以及这种操作是否对视频级学习有用。另外直接将 Nonlocal 应用于整个视频的计算量也比较高。我们的目标是设计一种计算量低而且容易优化的 long-term spatiotemporal model。在这项工作中,我们引入了残差 4D 块,并将 3D CNN 投射到 4D CNN 中,以学习 3D 特征的远程交互,从而得到“time of time”的视频级表示。
3.1 视频级采样策略
为动作识别建模有意义的视频级表示,网络的输入要覆盖给定视频的整体持续时间,同时,保持短期的动作细节。在这项工作中,我们均匀地划分整个视频,并从每个部分随机选择一个片段来表示一个短期动作模式,称为“动作单元”。然后我们用一系列动作单元来表示视频中的整体动作。
3.2 用于学习时空交互作用的 4D 卷积
三维卷积核已被提出多年,对短期时空特征建模具有强大的作用。然而,由于三维核的尺寸较小,三维核的 receptive field 往往受到限制,通常采用 max pooling 来扩大 receptive field,导致信息丢失。这启发了我们开发新的操作,可以同时建模短期和长期的时空表示,易于优化和快速训练。从这个角度出发,我们提出了 4D 卷积来更好地对长程时空相互作用进行建模。
我们定义输入的尺寸是 (C,U,T,H,W),其中 C 是频道数量,U 是动作单元的数量,T、H、W分别代表每个动作单元的时间长度、高度和宽度。一个位于 (u,t,h,w) 的属于第 j 个频道的输出像素用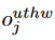
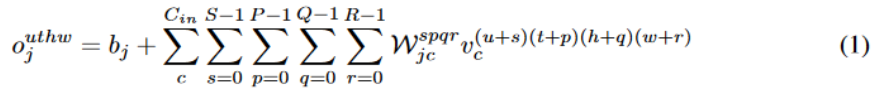
而因为卷积运算是线性运算,所以可以交换求和顺序,从而得到公式(2)
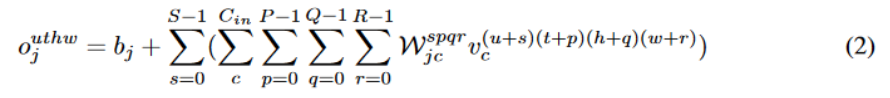
注意到括号里面的运算其实就是 3D 卷积运算,所以其实 4D 卷积可以由 3D 卷积实现。这就是在大多数深度学习框架都没有提供 4D 运算的情况下,我们是如何实现 4D 卷积的。
此外,在图 2 中我们可视化了几种 4D 卷积核的行为并与 3D 卷积核进行了对比,图中蓝色表示卷积核,绿色表示卷积核的中心。
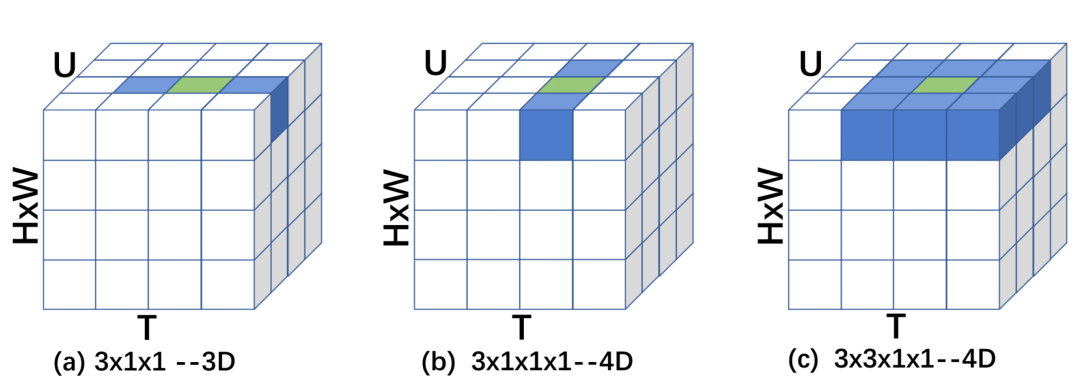
Figure 2: Implementation of 4D kernels, compared to 3D kernel s. U denotes the number of action units, with shape of T;H;W. Channel and batch dimensions are omitted for clarity. The kernels are colored in Blue, with the center of each kernel colored in Green.
与三维卷积相比,我们所提出的 4D 卷积能够在更有意义的 4D 特征空间中对视频进行建模,使其能够学习更复杂的远程三维时空表示交互。然而,4D 卷积不可避免地会引入更多的参数和计算成本。在实际应用中,以 k×k×k×k 的 4D 卷积核为例,比 k×k×k 的 3D 卷积核的参数要多 k 倍,所以我们还对 k×k×1×1 和 k×1×1×1 的 4D kernels 进行了探索,以减少参数,避免过拟合的风险。
3.3 视频层次 4D CNN 架构
我们将 4D 卷积加入到现有的 CNN 结构中。为了充分利用当前效果较好的 3D CNN,我们提出了残差 4D 模块,这使得同时学习视频级别的短程和长程时空变化成为可能。特别地,我们定义一个交换函数,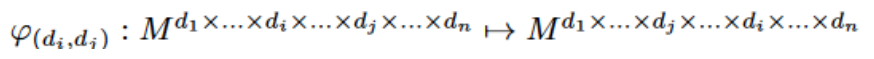
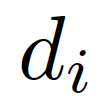
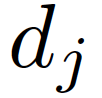
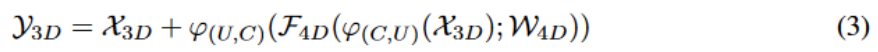
其中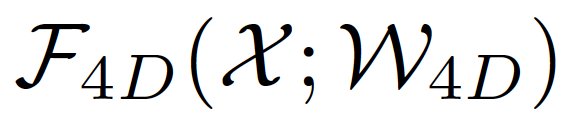
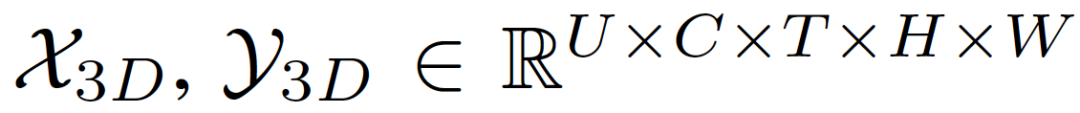
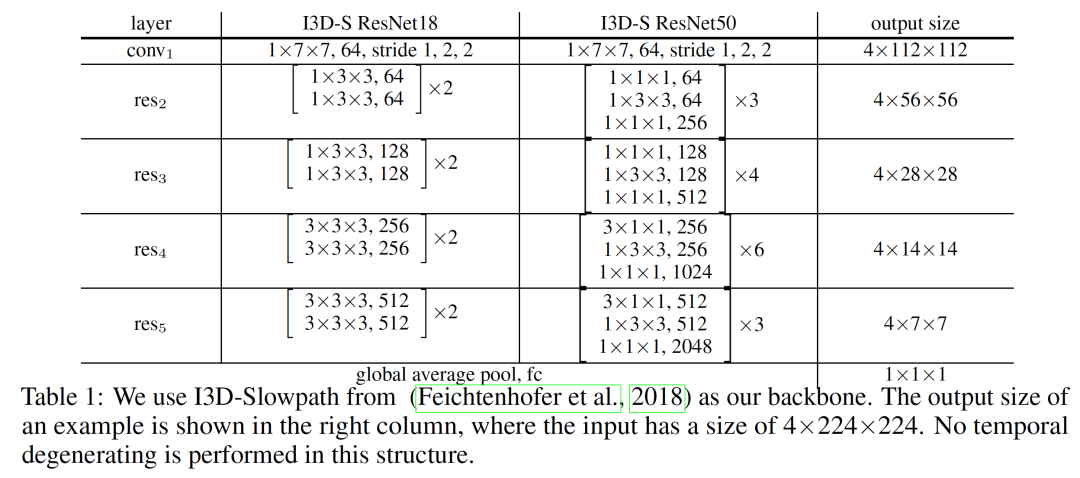
理论上,任何三维 CNN 结构都可以通过集成我们的 4D 卷积块投射到 4D CNN。如先前的工作所示,通过在较低层应用二维卷积和在较高层应用三维卷积可以获得更好的性能。在我们的框架中,我们使用了来自 Feichtenhofer 等人的 Slowpath 作为我们的 backbone,简写为 I3D-S。虽然最初的 Slowpath 是为 resnet50 设计的,但我们可以将其扩展到 I3D-S resnet18 进行进一步的实验。我们的 3D 主干的详细结构如表 1 所示。
3.4 训练和推理训练
训练方法:如图 1 所示,网络的卷积部分由 3D 卷积层和提出的残差 4D 块组成。每个动作单元在共享相同参数的三维卷积层中分别和并行地训练。从每个动作单元计算出的这些单独的 3D 特征然后被输入到残差 4D 块中,以模拟连续动作单元的长期时间演化。最后,对所有动作单元的序列应用全局平均池,形成视频级表示。
推理方法:

3.5 进一步的讨论
在这一节中,我们将展示所提出的V4D可以被看作是对近年来广泛应用的方法的拓展,
(1) 时间段网络
我们的 V4D 与时间段网络(TSN)密切相关,虽然最初是为 2D CNN 设计的,但是 TSN 可以直接应用到 3D CNN 来建模视频级表示。在训练过程中,每一个片段都是单独计算的,然后对全连接层之后的预测分数进行平均。由于全连接层是一个线性运算,在全连接层之前(类似于 global avgpool)或全连接层之后(类似于 TSN)计算平均值在数学上是等价的。因此,如果 4D 块中的所有参数被分配为零,则我们的 V4D 可以被认为是 3D CNN+TSN。
(2) 空洞时序卷积
一种特殊的 4D 卷积核,kx1x1x1,和时序空洞卷积密切相关。当把所有的动作单元在时间维度上连接在一起,输入的视频级别表示可以被看成是 (C,UxT,H,W) 的一个张量。这种情况下,kx1x1x1 的 4D 卷积可以被看成空洞为 T 的 kx1x1 的 3D 卷积。当然 kx1x1x1 的 4D 卷积是最简单的 4D 卷积核形式,其他更加复杂的 4D 卷积核不能用这种方式解释。此外我们提出的 4D 残差块包含了残差结构,从而使得长时间的视频结构和短时间的时空结构可以被同时学习,这是时序空洞卷积所不具有的功能。
实验
4.1 数据集
我们在三个标准基准上进行实验:Mini-Kinetics-200、Kinetics-400、Something-Something-v1。Mini-Kinetics 包含 200 个动作类,是 Kinetics-400 的一个子集。由于 Kinetics 数据集的一些数据缺失,我们版本的 Kinetics-400 在训练和验证子集中分别包含 240436 和 19796 个视频。Mini-Kinetics 版本包含 78422 个训练视频和 4994 个验证视频。每个视频大约有 300 帧。Something-Something-v1 总共包含 108499 个视频,其中 86017 个用于训练,11522 个用于验证,10960 个用于测试。每个视频有 36 到 72 帧。
4.2 Mini-Kinetics 的实验
我们使用预先训练的权重从 ImageNet 初始化模型。为了训练,我们采用了在第 3.1 节中提到的整体采样策略。我们均匀地划分整个视频成 U 个部分,并从每个部分随机选择一个 32 帧的片段。对于每个片段,我们均匀地采样 4 帧,固定步长为 8,形成一个动作单元。我们将在下面的实验中研究它的影响。我们首先将每个帧的大小调整为 320×256,然后随机裁剪,然后将切出的区域进一步调整为 224×224。我们使用 SGD 优化器,初始学习率为 0.01,权重衰减设置为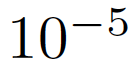
为了进行公平的比较,我们遵循 Nonlocal 和 Slowfast 使用了 FCN Testing。我们从整个视频中均匀地抽取 10 个动作单元,用 3 个 256×256 区域对每个动作单元进行空间覆盖,然后进行 V4D 推理。注意,对于原始的 TSN,在推断期间使用 25 个片段和 10-crop 推理。为了公平比较 I3D 和 V4D,我们对 TSN 也应用 FCN Testing 这种 10 个片段和 3-crop 的推理策略。
结果。为了验证 V4D 的有效性,我们将其与基于片段的方法 I3D-S 和基于视频的方法 TSN+I3D-S 进行了比较。为了补偿由 4D 块引入的额外参数,我们在 I3D-S 的 Res4 中添加 3×3×3 残差块用于进行公平比较,表示为 I3D-S ResNet18++。如表 2A 所示,即使 V4D 比 I3D-S 在推理中使用的帧数少 4 倍,而且比 I3D-S ResNet18++ 的参数少,V4D 仍然比 I3D-S 的准确率高 2%。与视频级别方法 TSN+I3D-S 相比,V4D 提升了 2.6% 的准确率。
不同形式的 4D 卷积核。如前所述,我们的 4D 卷积核可以使用 3 种典型形式:k×1×1×1、k×k×1×1 和 k×k×k×k。在本实验中,我们将 k=3,并在 I3D-S ResNet18 的 res4 末尾应用 1 个 4D 块。如表 2c 所示,3×3×3×3 kernel 的 V4D 可以达到最高性能。然而,通过考虑模型参数与性能之间的权衡,在下面的实验中,我们使用了 3×3×1×1 内核。
4D 块的位置和数量。我们评估了 4D 块的位置和数量对 V4D 的影响,通过在 res3、res4 或 res5 上使用 3×3×1×1 4D 块来研究 V4D 的性能。如表 2d 所示,通过应用 4D 块在 res3 或 res4 可以获得更高的精度。
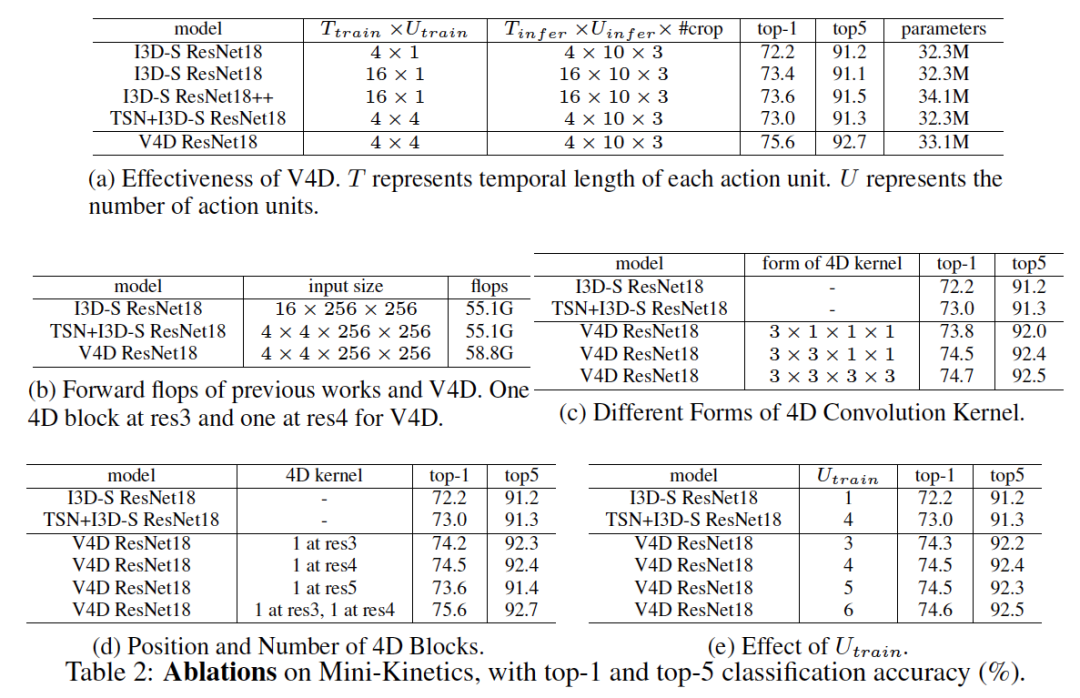
不同数量的动作单元。我们通过使用不同数量的动作单元来训练 V4D,使用不同的 U_train 参数值。本实验在 ResNet18 的 res4 末端插入 1 个 3×3×1×1 4D 块。如表 2e 所示,U_train 对性能没有显著影响,这表明:(1) V4D 是一个视频级特征学习模型,它对短期单元的数量具有鲁棒性;(2)一个动作一般不包含多个阶段,因此增加了无帮助。此外,动作单位数量的增加意味着第四维度的增加,这需要更大的 4D 内核来覆盖时空表示的范围演化。
与最新技术的比较。我们将我们的 V4D 与以前的最新方法进行了比较。在 res3 和 res4 中,4D 残差块每隔一个 3D 模块使用一次。尽管在训练和推断期间使用的帧更少,我们的 V4D ResNet50 比该基准上所有报告的结果都具有更高的精确度,甚至比具有 5 个 Compact Generalized Nonlocal Block 的 3D ResNet101 还要高。此外,我们的 V4D ResNet18 可以比 3D ResNet50 实现更高的精度,而则进一步验证了我们的 V4D 结构的有效性。
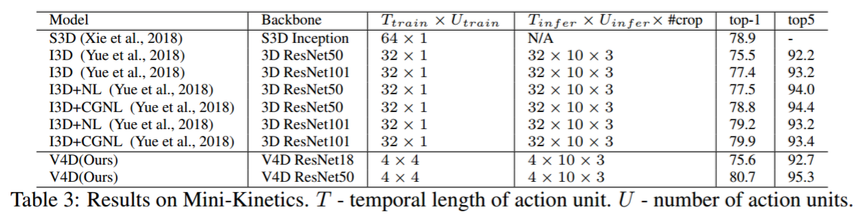
4.3 在 Kinetics 的实验
我们进一步对大规模视频识别基准 Kinetics-400 进行实验,以评估 V4D 的能力。为了公平地比较,我们使用 ResNet50 作为 V4D 的主干。训练和推理采样策略与前一节相同,除了每个动作单元现在包含 8 帧而不是 4 帧。由于训练资源有限,我们选择多阶段训练模型。我们首先用 8 帧输入训练 3D ResNet50 主干网。然后我们加载 3D ResNet50 的参数到 V4D ResNet50 中,同时把所有 4D 参数都冻结成 0。然后用 8×4 输入帧对 V4D ResNet50 进行微调。最后,我们优化了所有 4D 块,并用 8×4 帧来训练 V4D。如表 4 所示,我们的 V4D 在 Kinetics-400 基准上取得了有竞争力的结果。
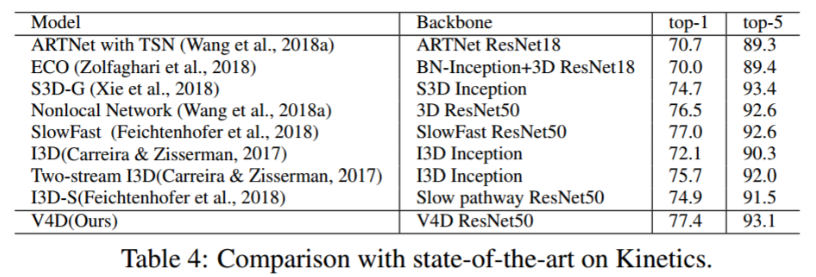
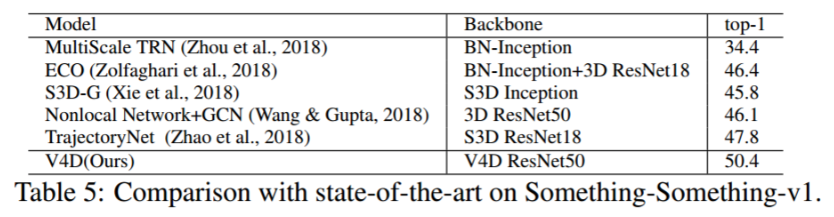
4.4 在Something-Something-v1的实验
与 Mini-Kinetics 和 Kinetics 相比,Something-Something 主要是对时间信息和运动的建模。背景比 Kinetics 更干净,但动作类别的运动要复杂得多。每一个视频中的 Something-Something 包含一个单一的连续动作,在时间维度上具有明确的开始和结束。
结果。与以前的作品相比,如表 4.4 所示,我们的 V4D 在Something-Something-v1 上取得了竞争性的结果。我们使用 Kinetics 预先训练的 V4D ResNet50 进行实验。
时间顺序。通过逆转时间,3D 模型的准确度显著下降,这说明 3D CNN 可以学习到非常强的时间顺序。对于我们的 V4D,有两个等级的时间顺序,短程的顺序和一个长程的顺序。如表 6 所示,通过反转每个动作单元内的帧或反转动作单元的序列,top-1 的精确度显著下降,这表明我们的 V4D 能够捕获长期和短期的时间顺序。

我们引入了新的视频级 4D 卷积神经网络,即 V4D,以学习强时空演化的长距离时空表示,以及保留具有残存连接的 3D 特征。此外,我们还介绍了 V4D 的训练和推断方法,在三个视频识别基准上进行了实验,其中 V4D 获得了不错的结果。
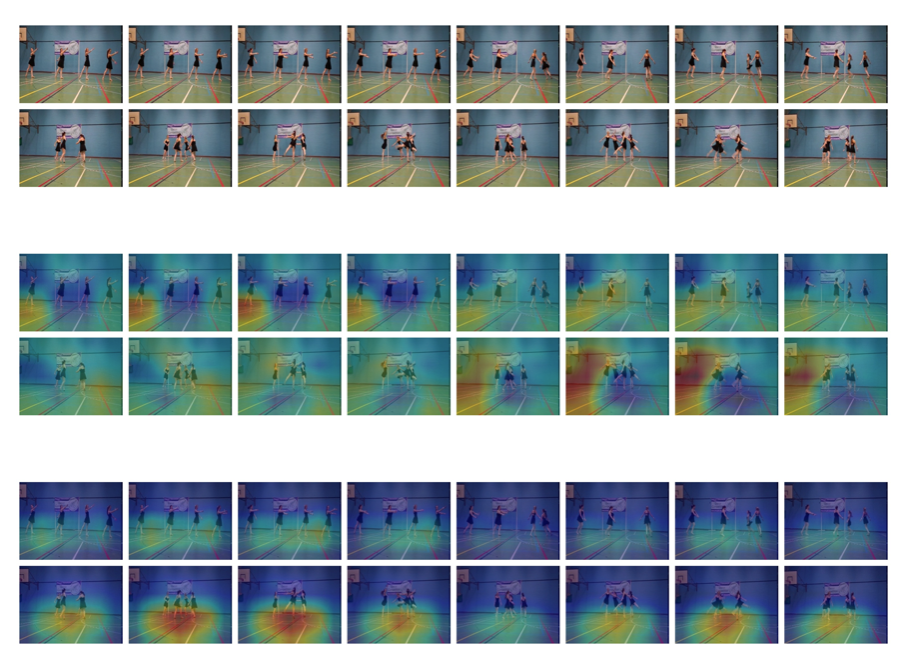
可视化的结果,第一行为 RGB 视频,第二行为 TSN+I3D-S, 第三行为 V4D
1、ACL 2020 - 复旦大学系列解读
直播主题:不同粒度的抽取式文本摘要系统
主讲人:王丹青、钟鸣
回放链接:http://mooc.yanxishe.com/open/course/804(回放时间:4月26日下午10点)
直播主题:结合词典的中文命名实体识别【ACL 2020 - 复旦大学系列解读之(二)】
主讲人:马若恬, 李孝男
直播时间:4月 26 日,(周日晚) 20:00整。
直播主题:ACL 2020 | 基于对抗样本的依存句法模型鲁棒性分析
【ACL 2020 - 复旦大学系列解读之(三)】
主讲人:曾捷航
直播时间:4月 27 日,(周一晚) 20:00整。
2、ICLR 2020 系列直播
直播主题:ICLR 2020丨Action Semantics Network: Considering the Effects of Actions in Multiagent Systems
主讲人:王维埙
回放链接:http://mooc.yanxishe.com/open/course/793
直播主题:ICLR 2020丨通过负采样从专家数据中学习自我纠正的策略和价值函数
主讲人:罗雨屏
回放链接:http://mooc.yanxishe.com/open/course/802
直播主题:ICLR 2020丨分段线性激活函数塑造了神经网络损失曲面
主讲人:何凤翔
回放链接:http://mooc.yanxishe.com/open/course/801
扫码关注[ AI研习社顶会小助手] 微信号,发送关键字“ICLR 2020+直播” 或 “ACL 2020+直播”,即可进相应直播群,观看直播和获取课程资料。

阅读原文,直达“直播间”



