NeurIPS 2020 | MiniLM:通用模型压缩方法

基本信息
标题:
MiniLM: Deep Self-Attention Distillationfor Task-Agnostic Compression of Pre-Trained Transformers
机构:
微软研究院
作者:
Wenhui Wang, Furu Wei, Li Dong, Hangbo Bao,Nan Yang, Ming Zhou
论文地址:
https://arxiv.org/abs/2002.10957
论文代码:
https://github.com/microsoft/unilm/tree/master/minilm
简介
这里尝试通过一问一答的方式来简介MiniLM。
Q:这篇文章要解决什么问题?
A:预训练模型的低效问题。预训练模型过大的话,有2个弊端:(1)推理速度慢(2)内存空间占用大。
Q:文章如何解决上述问题?
A:提出了一种通用的面向Transformer-based预训练模型压缩方法:MiniLM。MiniLM有3个核心点:
(1)蒸馏teacher模型最后一层Transformer的自注意力模块
(2)在自注意模块中引入值之间的点积
(3)引入助教模型辅助模型蒸馏
Q:文章方案最终效果如何?
A:在各种参数尺寸的student模型中,MiniLM的单语种模型优于各种最先进的蒸馏方案。在 SQuAD 2.0和GLUE的多个任务上以一半的参数和计算量就保持住99%的accuracy。此外,MiniLM在多语种预训练模型上也取得不错的结果。
模型
常见的模型蒸馏是让student模型学习teacher模型的特征,并让两者的loss最小。其中用于学习的特征包括:
(1)预测被mask掉token的概率分布
(2)embedding layer的输出
(3)自注意力分布
(4)teacher模型中每个Transformer层的输出
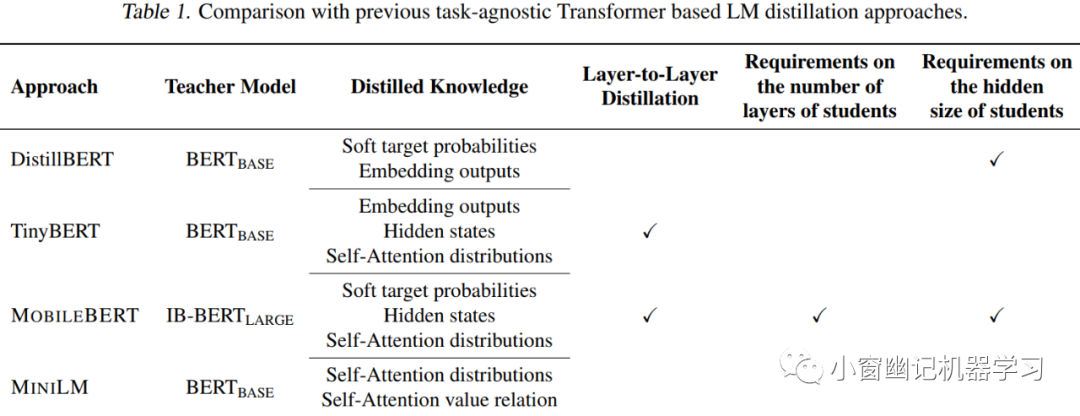
比如,DistillBERT中蒸馏学习了labels 和 embedding layer的输出;TinyBERT 和 MOBILEBERT则进一步学习各层Transformer的自注意力分布和输出。但是,MOBILEBERT要求student模型与teacher模型有相同的层数。此外,MOBILEBERT还引入了bottleneck模块和倒bottleneck模块,以保持teacher和student间隐层尺寸相同。TinyBERT则使用单值函数映射teacher层和student层,实现层与层之间的知识迁移。
文章提出的MiniLM主要有以下3点贡献。
1). 只对teacher模型最后一层Transformer进行深度蒸馏,避免了teacher模型和student模型之间的层映射,这让student模型的层数可以更加灵活。
2). 在MiniLM的自注意力模块中,除了常规的queries和keys缩放点积之外,在values之间也加入缩放点积操作。引入value之间的关系,能让student深入模仿teacher的自注意力行为。此外,使用缩放的点积将不同隐层维数的向量转换为相同大小的关系矩阵,这使得student可以使用更灵活的隐层维数,且无需引入额外的参数转换student的表征。
3). 引入助教机制辅助蒸馏大型预训练模型,并进一步提升蒸馏性能。
Table 1 对比了MiniLM与其他模型蒸馏方案。
深度自注意力蒸馏 MiniLM 的深度自注意力蒸馏流程如 Figure 1所示。
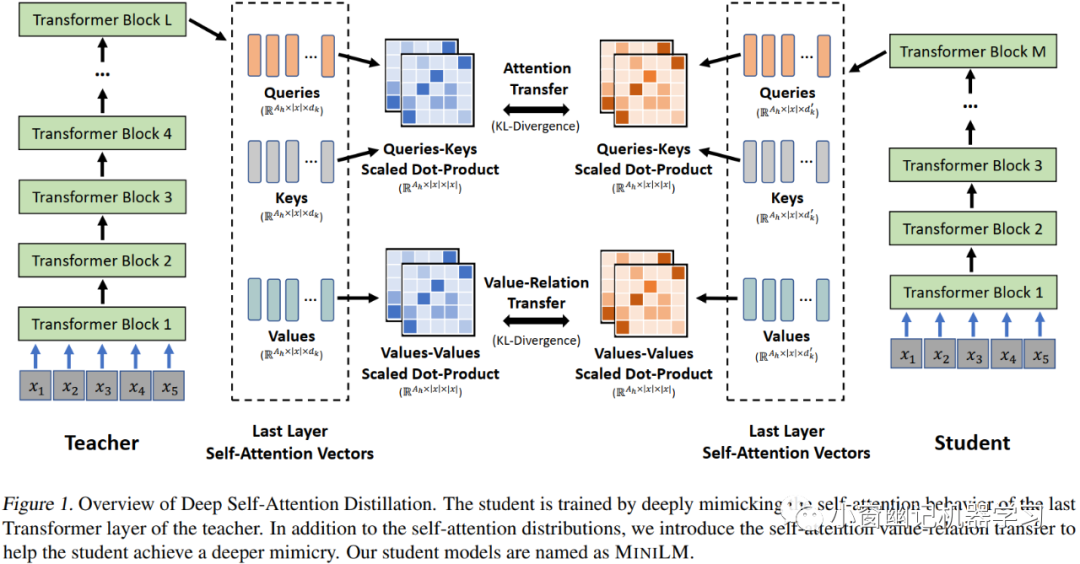
自注意力分布迁移:
预训练模型的自注意力分布捕获了层次丰富的语言信息,所以student模型需要学习teacher模型的自注意力分布。与层-层蒸馏方式不同,MiniLM只学习teacher模型的最后一层Transformer的注意力分布。
自注意力Value关系迁移:
在最后一层Transformer中利用自注意力value之间的关系指导student模型。value之间的关系通过value之间的多头缩放点积计算。训练目标是最小化teacher和student之间的value关系差异。所以,综合的训练损失是自注意力分布差异损失和value关系差异损失之和。
助教模型:
引入助教模型是为了进一步提高更小student模型的表现结果。假设teacher模型的隐层尺寸为 ,Transformer层数为L;student模型隐层尺寸为 ,Transformer层数为M。当想要蒸馏到更小的student模型( ), 先将teacher蒸馏到一个L层Transformer、隐层尺寸为 的助教模型,再使用助教模型指导训练这个更小的student模型。助教模型的引入缩小了teacher模型和更小student模型之间的差距,有助于预训练语模型的蒸馏。
实验
自然理解任务
实验阶段蒸馏出了各种参数大小的student模型,并在抽取式问答数据集SQuAD 2.0和GLUE上进行评测。
以BERT-base为teacher,将其蒸馏出 6层,768维的student模型。Table 2记录了各种蒸馏模型在 SQuAD 2.0 和 GLUE 上的结果。
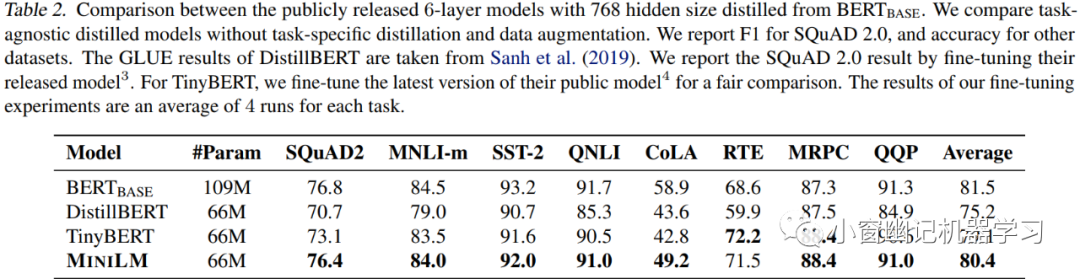
从实验结果可以看出,多数任务上 MiniLM 都优于 DistillBERT 和 TinyBERT。特别是在SQuAD2.0数据集和CoLA数据集上,MiniLM分别高出冠军模型3.0个F1值和5.0个accuracy。Table 4则展现了不同模型的推理时间。
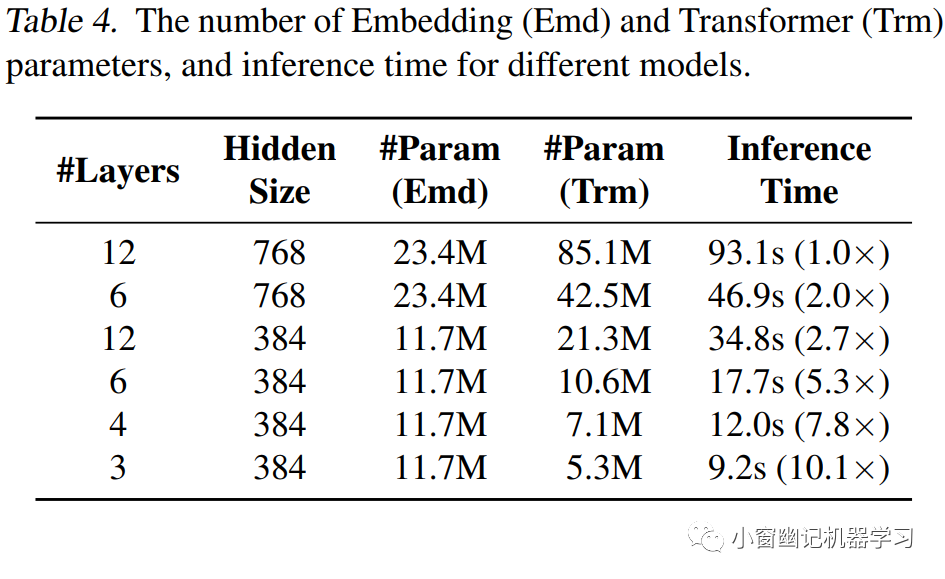
从对比结果可以看出,6层、768维的MiniLM student模型比原始的BERT-base快2倍,且在各个任务上保持99%的精度。
将模型蒸馏到更小student的对比结果如Table 3所示:
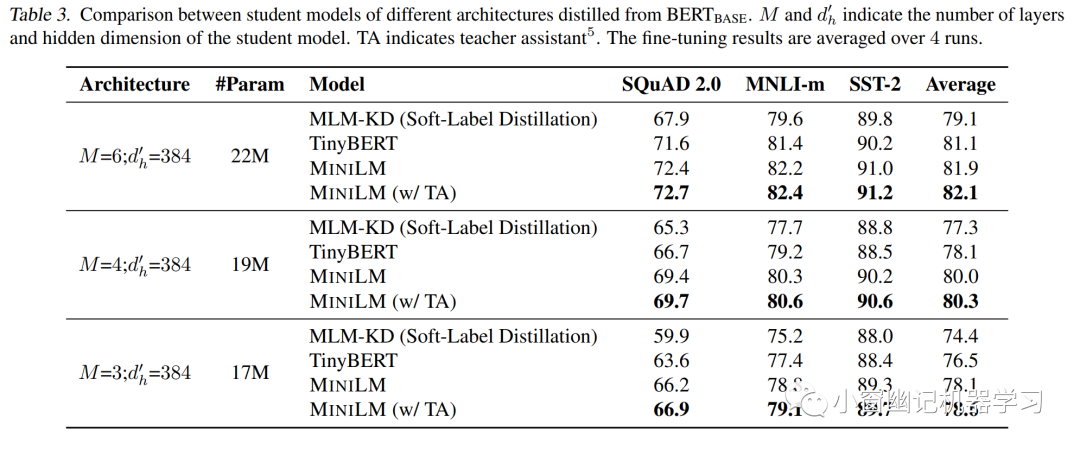
实验结果表明,MiniLM在三项任务上优于soft label蒸馏(MLM-KD)和TinyBERT,且深度自注意力蒸馏对小模型也很有效。此外,助教模型的引入对于蒸馏较小模型,改善效果更加显著!
文本生成任务
文章进一步在自然语言生成任务上评估MiniLM。在自然语义生成任务中,MiniLM微调的时候使用了特定的self-attention mask。
问题生成:
给定文本和答案,产生问题。MiniLM、UNILM-large及其其他先进模型在SQuAD 1.1数据集上的评测结果如Table 9所示。
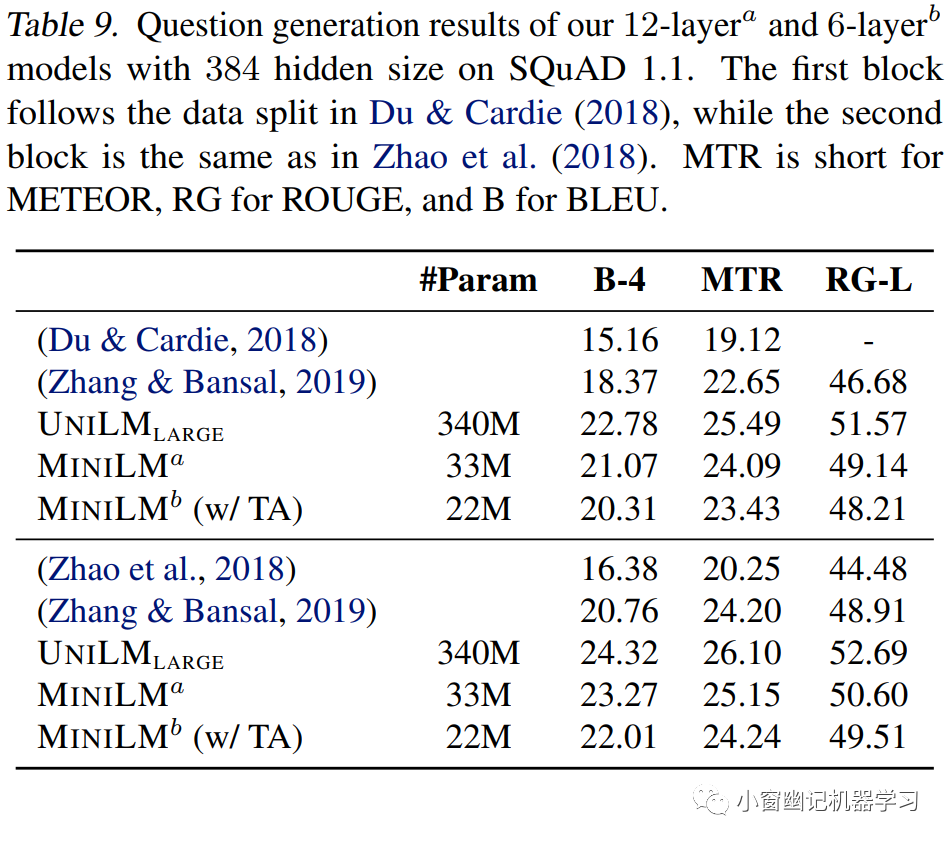
可以看出,12x384 和 6x384版的MiniLM的成绩都蛮不错,与那些先进模型相比,并没有差很多,具有很强的竞争力。
摘要生成:
评测数据集是XSum和CNN/DailyMail。各个模型摘要生成的对比结果如 Table 10所示。

可以看出,12x384版的MiniLM以较少的参数量在ROUGE得分上完胜BERTSUMABS和MASS-base。6x384版的MiniLM效果也还不错。
多语言版MiniLM
蒸馏多语言MiniLM的teacher模型是XLM-R Base。Table 11展示了各模型在XNLI数据集上的实验结果。Table 12则对比了各个模型Transformer层、隐层等模型参数。
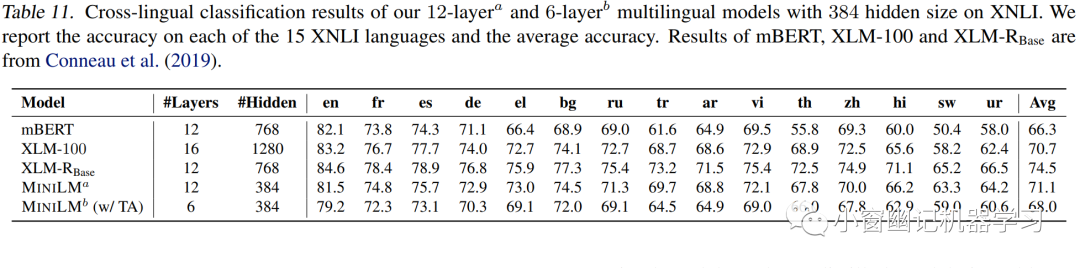
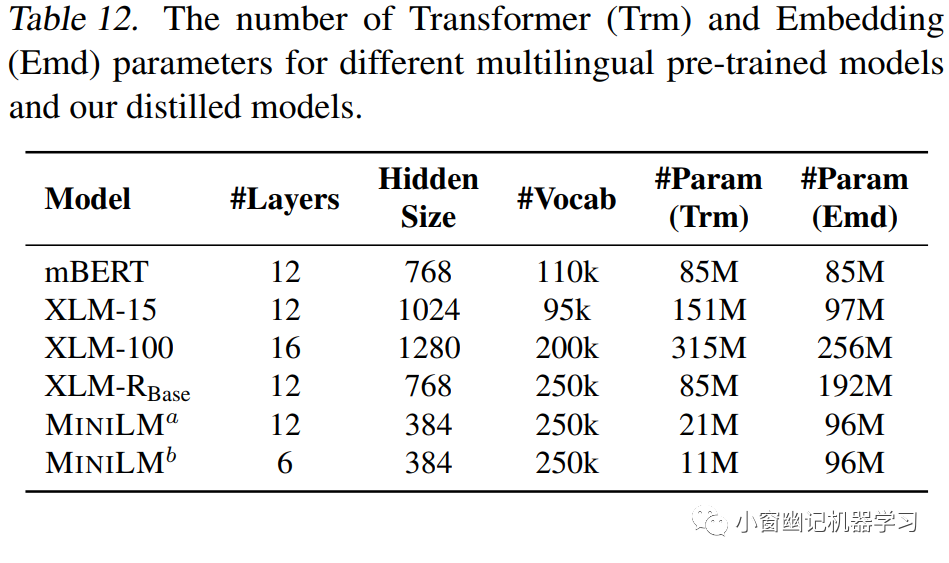
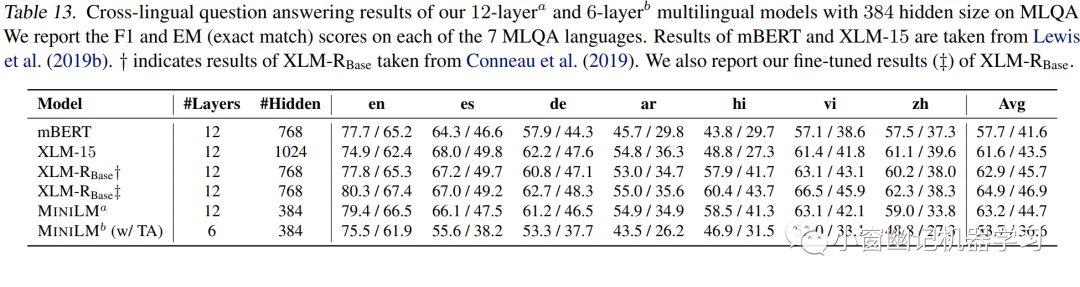
可以看出MiniLM虽然参数量少,但仍然具有较强竞争力。令人倍感意外的是,12x384版的MiniLM竟然优于mBERT和XLM!最后,各模型在跨语言问答数据集MLQA上的评测结果如Table 13所示。12x384版的MiniLM同样优于mBERT和XLM。
总结
文章提出了一种面向Transformer-based预训练模型的通用压缩方法:深度自注意力知识蒸馏(Deep Self-Attention Distillation)MiniLM。通过让student模型深度模仿teacher模型的最后一层自注意力知识,并学习最后一层value关系助力模型蒸馏效果。此外,MiniLM中引入助教模式能够进一步提升students的学习效果。MiniLM的蒸馏方法简单有效,由不同预训练大模型压缩得到单语和多语MiniLM预训练模型不仅更小更快,而且在多个自然语言理解和生成任务上效果显著。
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方"AINLP",进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心

推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏





