寒武纪研究院院长杜子东:寒武纪解决了AI处理器哪些问题?
▲点击上方 雷锋网 关注

文 | 王金旺
来自雷锋网(leiphone-sz)的报道
在人工智能领域,或者说深度学习领域,寒武纪成为我国一大利器已然人尽皆知,但是大家知道最多的仍只是华为用到了寒武纪的IP。而具体寒武纪的发展历路,解决了AI处理器的哪些问题,仍是被轻描淡写地草草略去,鲜有问津。
9月22日,在北京的CCF YOCSEF TDS专题探索班上,寒武纪研究院院长杜子东以《深度学习处理器》为主题,就寒武纪在学术领域的研究、解决的问题,就寒武纪几代人打下的“江山”进行了分享解读。

从人类大脑到人工神经网络
2007年,以深度学习、人工神经网络为核心的AI浪潮再次兴起。而人工神经网络的提出其实可以追溯到1956年达特茅斯会议,在该会议上,与会专家提出了人工智能的概念。随之而来的则是人工神经网络,人工神经网络模仿人类大脑,通过神经元传输信息。
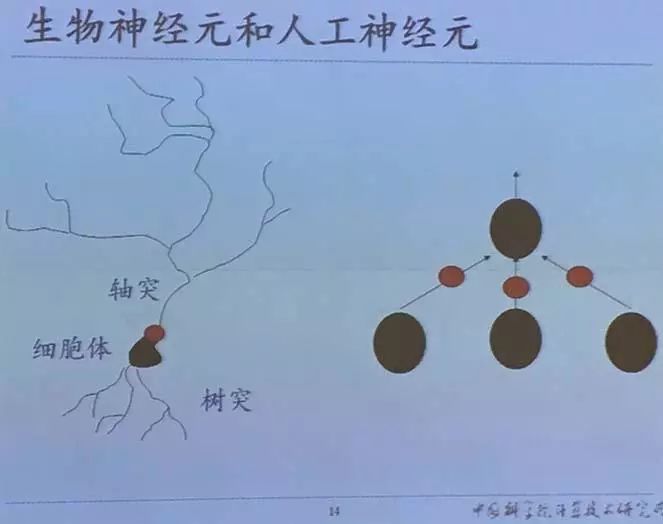
生物神经元和人工神经元仍有一定区别。生物神经元很复杂,在人脑中有860亿个神经元,根据生物学家的估算,每个神经元中有1000个突触,也就是说每个神经元会和其他1000个神经元连接,对于这样一个庞大规模的大脑组织,具体到每一个神经元上,不仅有这样的连接,还有很多化学现象和生理现象。
对于这样复杂的神经元,研究人员之前做的工作是将其简化成简单的抽象模型。简化后的模型主要包含两部分:输入和权值。
如果是输入向量和权值向量的话,实际上就是进行内积,然后构建激活函数,在非线性激活函数引入后,其在非线性分类问题上会有一定的这种效果。
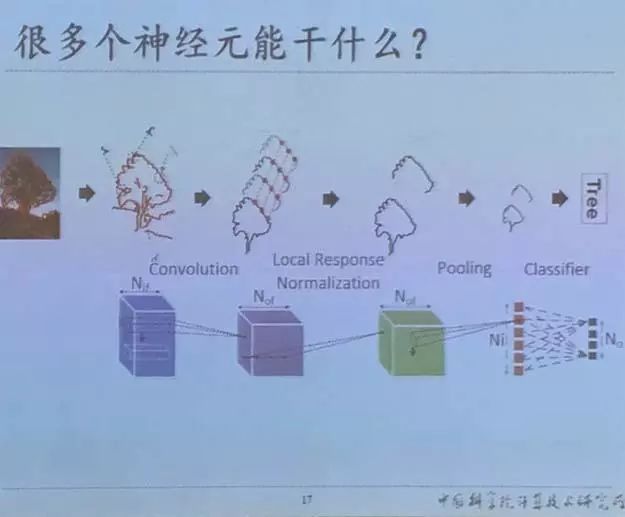
从单个神经元到多个神经元
单个神经元有两个输入,它可以用来处理二分类问题,典型例子是在二维平面中寻找最优分割面。通过不同的输入样本对模型进行训练,不停地修正找到的分割面。如果将多个神经元组合起来,能够完成一些更复杂的任务。例如可以完成多分类,甚至加入一些其他复杂的处理,从而实现诸如图像识别的任务。
智能处理器成刚需
与此同时,高算力也成为刚需。
在图像识别方面,从过去不需要专门的处理器到现在图像处理需求的不断增加,尤其在游戏领域,随着图像分辨率的提升及实时渲染的需求,将图像处理作为单独任务转移到专用处理器上已成必须,因而有了GPU;
在信号处理方面,由于类似多任务场景的出现,也需要将信号处理转移到专用设备上进行处理,也就有了现在的DSP;
而随着智能硬件的出现及相关领域算力需求持续走高,对功耗、延时等要求更高的智能处理器也成为继上述处理器之后的又一专用处理器类型。
从云服务到智能手机,未来每台计算机都可能需要一个专用的深度学习处理器,这一市场预计将成为和GPU同样规模,每年拥有6.4亿颗芯片,数百亿美元销售额的市场。
寒武纪的学术背景
据雷锋网了解,自2008年初步拥有一定研究成果到2016年成立寒武纪科技公司,在全球人工智能学术界曾取得诸多学术成果,包括2013年发布国际首个深度学习处理器(DianNao),2014年发布国际首个多核深度学习处理器(DaDianNao),2015年发布国际首个通用机器学习处理器(PuDianNao)及摄像头上的智能识别IP(ShiDianNao),2016年发布国际首个神经网络通用指令集(Cambricon)等。
谈到2015年发布的通用机器学习处理器,寒武纪研究院院长杜子东表示,“在很多领域,尤其是一些小样本的应用领域,深度学习并不是最优选项,甚至用SVM(Support Vector Machine,支持向量机)就已经足够,对于这类应用,我们完全可以用一些传统机器学习代替深度学习。这就是我们2015年做这个通用机器学习处理器的主要原因。”
也正是基于这样深厚的学术积淀,寒武纪科技在2016年成立后,即推出寒武纪1A处理器。另外,寒武纪机器学习处理器MLU100采用TSMC 16nm工艺,拥有1.3GHz主频,166Tops峰值,80W平均功耗,110W峰值功耗。
ASIC用于深度学习存在的三大矛盾
传统ASIC将一个特定算法硬体化的思路无法很好地解决深度学习处理需求,主要存在以下三个矛盾:
有限规模的硬件和任意规模的算法的矛盾
结构固定的硬件和千变万化的算法的矛盾
能耗受限的硬件和精度优先的算法的矛盾
以能耗问题为例,现在的图像显示已经从之前的高清、超清,逐渐发展到1080P、4K,现在主流摄像头已经开始进入到1080P,甚至4K的量级。对于这样规模的算法,如何将它部署到一个有限规模的硬件上就成了一个大问题。
寒武纪的解决之道
寒武纪过去做的学术工作主要也是针对这三大矛盾,展开研究工作。
采用硬件神经元虚拟化解决有限规模的硬件和任意规模算法的这个矛盾。创新之处在于通过时分复用,将有限规模的硬件虚拟成任意大规模的人工神经网络。其中关键技术在于控制架构和访存架构,控制架构方面支持硬件神经元的动态冲配置和运行时编程,访存架构方面支持分离式的输入神经元、输出神经元和突触的片上存储。
从软件角度来看,我们将整个软件或网络切割成不同的片,然后在硬件上进行运算,根据输入数据的不同特征,将数据分别存储,使得在访存时能够高效利用其局部特性。
硬件运算单元的分时复用(虚拟化)示意图如下图所示。一个硬件运算单元如果每次能够处理两处,针对图中所示网络,需要完成在不同时刻载入所需数据,或计算不同的输出神经元,然后通过往返复用,从而最完成整个网络的运算。
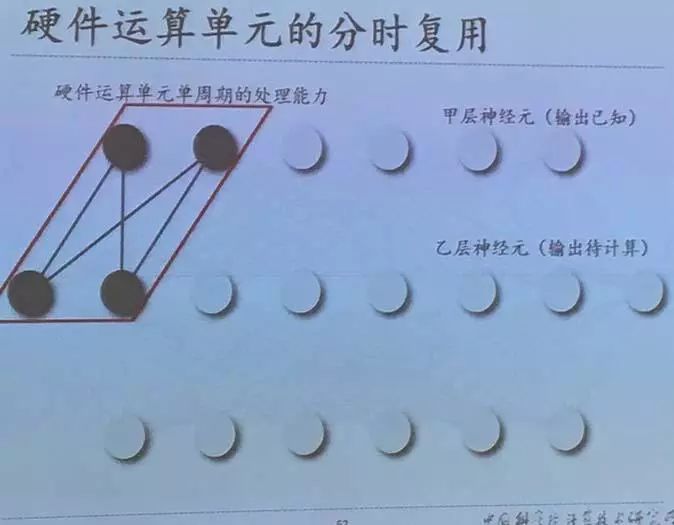
其中,通过对输入神经元的复用,当把两个所需神经元载入到片上后,下一步的运行是接着重复利用这两个输入神经元,这样能够节省访存次数,把这两个神经元或两个所需数据完全用完后,再在片上载入新的数据,进行下一步的这样的运算。
通过通用指令集解决结构固定硬件和千变万化的算法的矛盾。主要学术创新之处在于自动抽取各种深度学习(机器学习)算法共性基本算子,设计了首个深度学习指令集来高效处理这些算法。其中关键技术在于算子聚类和运算架构。算子聚类自动化抽取算法核心片段,基于数据特性聚为少数几类;运算架构通过设计共性神经元电路,支持变精度流水级。
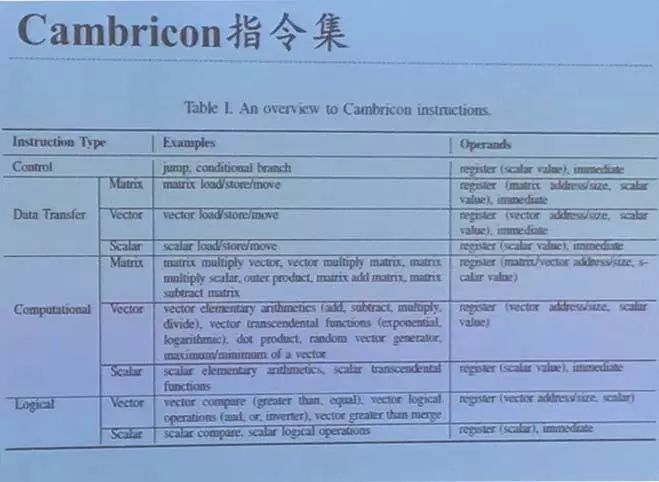
寒武纪设计通用指令集的策略主要分为三步;
通过模型、用途、计算复杂度等方面的差异分析,选择差异化的算法进行加速;
分析数据的计算模型和数据局部性,寻找最耗时/最普遍的运算操作集合,并研究算法的局部性,降低各算法的访存需求;
针对功能部件或片上存储设计合适的加速器结构。
通过稀疏神经网络处理器结构解决能耗受限的硬件和精度优先的算法的矛盾。其学术创新之处在于利用神经网络对于计算误差的容忍能力,进行稀疏化神经网络处理,在有限的能耗下实现高精度的智能处理。
神经网络中的参数量很大,数据量也很大,同时,神经元权值并不是很重要,如果将这些数据去除也不影响最后计算的识别结果。因而稀疏化是目前为止的一个重要数据处理方法。
神经网络模型最重要的是识别结果,识别结果并不是一个绝对量,而是一个相对量。例如采用传统的Softmax进行处理,最终是要选择输出最大神经元。只要能保证采用稀疏神经网络或采用变精度神经网络计算出的最终输出结果仍是之前的大神经元,就可以认为最后的输出结果没有错。当然,计算结果中的error和loss都会有变化。
寒武纪研发团队利用神经网络对于识别结果之间的计算误差的区别进行稀疏化处理,从而使得整个网络中所含有的神经元和权值的数量大幅度减少。根据实验数据得出的结果是:有90%的权值都是可以被去除的。也就是说,理论上,通过稀疏化处理可以降低十倍的计算和访存效率。针对这样的稀疏特性设计处理器结构,从而可以提高计算和访存效率。
雷锋网小结
寒武纪现在主要产品包括智能处理器IP和智能芯片,尤其在智能芯片方面,从产品层面来看,已经应用到华为等智能手机上;从技术层面来看,寒武纪也开发了自己的处理器架构和指令集,通过硬件神经元虚拟化、开发通用指令集、运用稀疏化处理器架构解决了ASIC用于深度学习时存在的三大问题。
其实在寒武纪之前,已有龙芯的研发。除了同为中科院背景的两个团队,在寒武纪研发团队中其实也可以看到龙芯的影子,尤其是,寒武纪创始人之一陈云霁教授师从胡威武研究员,而胡威武正是龙芯团队的主心骨。
经历了时代的更迭,在智能化浪潮下,杜子东告诉雷锋网编辑,寒武纪目前主要推动两个生态的建设:通过寒武纪的芯片给软件开发人员提供更好的编程能力(小生态);推动智能处理器上下游生态建设(大生态)。
而就现在来看,要想在这波智能化浪潮中迎风竖起这杆大旗,为国内智能设备带来更多优质AI处理器,寒武纪仍是任重道远。
雷锋网大招募开始了!如果你对人工智能、大数据、云计算、自动驾驶等前沿科技感兴趣,对采编、运营、品牌等职位感兴趣,请猛戳 招聘启事
◆ ◆ ◆
推荐阅读
黎曼猜想证明了?Michael Atiyah的愚人节难道在9月吗
iPhone XS Max评测:来自一万二的碾压!?
美团上市了!市值超越小米京东,王兴感谢乔布斯
详解腾讯AI布局,2B业务或将崛起
为什么 AI 芯片时代必然到来——从TPU开始的几十倍性能之旅

关注雷锋网(leiphone-sz)回复 2 加读者群交个朋友




