微软人工智能系统联合中心亮相,讲述如何打造全栈AI平台
▲点击上方 雷锋网 关注

文 | 李诗
来自雷锋网(leiphone-sz)的报道
(微软微软全球执行副总裁、人工智能及微软研究事业部负责人沈向洋博士在微软2018人工智能大会)
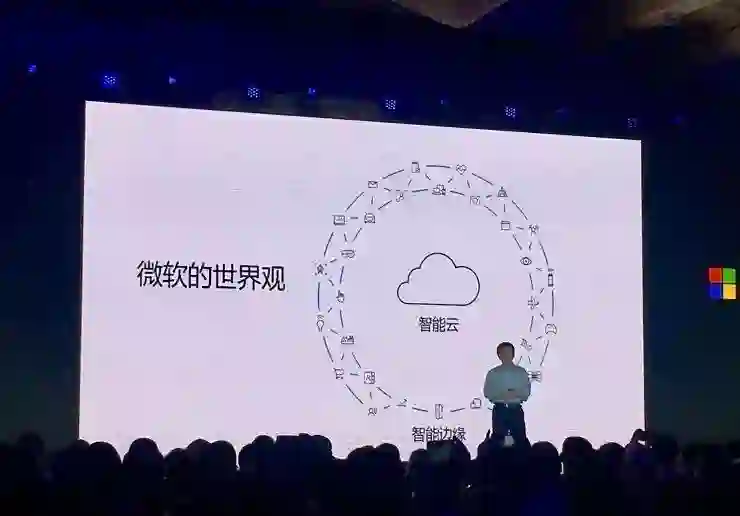
在近来的大会上,微软反复强调其全新的世界观“智能云&智能边缘”。在移动互联网时代掉队的微软,似乎要以这个新口号在人工智能时代脱胎换骨。
然而,以Windows操作系统起家的微软,并没有放弃“系统”。2017年,微软定位北京,成立了微软亚洲研究院-微软(亚洲)互联网工程院人工智能系统联合中心,旨在为微软的AI生态搭建最核心、最基础的系统平台。

6月20日,微软亚洲研究院副院长、人工智能系统联合中心负责人周礼栋以及其团队召开了一次深度workshop,向包括雷锋网在内的十余家科技媒体介绍微软如何做“人工智能时代的系统创新”。
何为系统?微软给出的定义是系统就是把零散、复杂的个体组织成有序的整体。在计算机领域,不妨将这个抽象又简单的名词理解为平台。“一直以来,微软都是一个平台公司,从早期的操作系统、数据库,到云平台、分布式系统,其实都可以被称为‘系统’。”
PC时代有操作系统,互联网时代有分布式系统,AI对系统提出了新的要求。现阶段的人工智能有三个非常重要的支柱点——大数据、新算法和大计算。而“系统”作为连接数据和算法的纽带,是一个不为大众所熟知的关键要素,一个好的系统可以有效支撑AI应用的架构、开发、部署和落地。
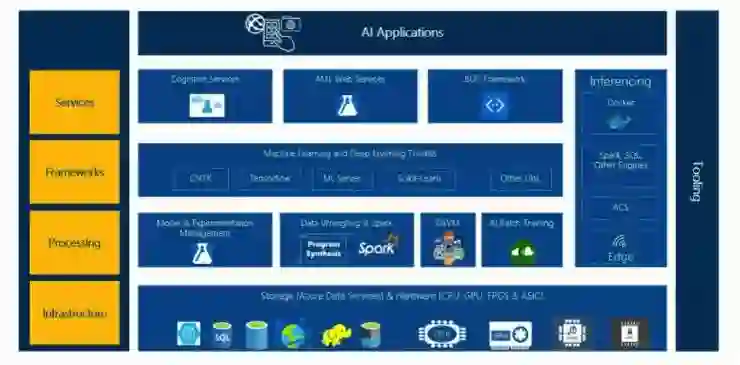
周礼栋介绍道,微软人工智能系统联合中心要做一个全栈的AI平台(AI Stack),可以为AI开发者提供全方位支持,让广大AI开发者、AI应用背后的技术团队,让他们在开发AI应用时更加得心应手,没有后顾之忧,目前主要分为三个层次:
一,AI计算能力。从硬件到基础设施再到管理系统全部覆盖,充分利用GPU、FPGA等新兴技术,以及云计算、大数据等现有的相对成熟的大规模分布式系统,让AI的计算能力实现价值最大化。
二,AI平台中间层。其中包括编程语言、各种工具包等,供开发AI算法的人使用,为他们提供完善的开发和运行环境。
三,AI算法。提供成熟的AI算法供应用开发者使用,例如让微软认知工具包CNTK与TensorFlow、Caffe等框架实现灵活转换,在一种框架下训练好的模型,可以在另一种框架下无缝使用,并将更多算法集成到Visual Studio中去。
全栈AI平台(AI Stack)体现了微软的系统理念,连接底层技术和工具包直接提升开发者进行深度学习开发、模型训练的效率,但是对于开发者来说整个系统又像是无形的、不可见的。这样的系统思路有助于实现“AI普及化”,打造一个通用AI平台的目标。当然,目前还需要各个层面的协同发展。
雷锋网了解到,在AI计算能力方面,英特尔、谷歌等主要发力AI芯片,微软则强调Azure智能云。Azure智能云汇聚了微软在人工智能领域的大量投入与技术积累,是开发、部署、运行人工智能的云平台,同时也是将智能云与智能边缘融会贯通的关键环节。微软一直在拓展Azure的功能。

Azure目前有四个方面:公有云Azure、混合云Azure Stack、物联网Azure IoT Edge和Azure Sphere,以这四个方面打造出完整的计算环境,支持全新应用场景。
在AI平台中间层,微软已有多种工具:Project Brainwave 、ML.NET、ONNX、OpenPAI、Tools for AI、NNI等,都旨在提供更简易、高效的人工智能开发工具。
微软于2017年发布的Project Brainwave能利用Azure上的FPGA基础架构完成实时的人工智能处理。用户只需要通过实时的单一批数据,就能得到以往需要多得多的批量数据处理才能得到的结果。
在Build 2018微软全球开发者大会上,微软宣布推出跨平台、开源机器学习框架ML.NET的预览版。ML.NET让任何开发者都能开发出自己的定制化机器学习模型,并将其融入到自己的应用中去——开发者完全无需具备开发和调试机器学习模型的经验。
在随后的微软2018人工智能大会上,微软介绍了两个新的工具:Open Platform for AI(OpenPAI)和Tools for AI。

OpenPAI由微软亚洲研究院和微软(亚洲)互联网工程院联合研发,旨在为深度学习提供一个深度定制和优化的人工智能集群管理平台,其支持多种深度学习、机器学习及大数据任务,可提供大规模GPU集群调度、集群监控、任务监控、分布式存储等功能。
Tools for AI也是中国团队打造,为开发者提供了一个全平台、全软件产品生命周期、支持各种深度学习框架的开发套件。开发者可以通过熟悉的Visual Studio和Visual Studio Code开发工具,快速开发深度学习相关的程序。Tools for AI的一键安装功能可以帮助开发者配置深度学习的开发环境,配合Visual Studio (Code)自带的Python语言开发功能,开发者可以方便地编辑和调试基于CNTK、TensorFlow、PyTorch等主流深度学习框架下构建的深度学习训练程序。

除了以上已经发布的工具外,微软亚洲研究院资深研究员伍鸣和研究员薛卉在workshop现场演示了微软在人工智能系统上的创新。
伍鸣展示了三种深度学习框架后端优化路径,第一种是一种硬件网络技术RDMA网卡,目前许多以深度学习为目标应用的GPU集群都部署了这样的网络。为了更好地利用如RDMA、NVLink等的高速网络硬件的能力,微软设计了一种零拷贝通信机制,将Tensor数据直接传输到接收端。经过在TensorFlow上的实验,该方法在一系列神经网络模型上的收敛速度提高2-8倍。第二种是内核融合,其主要思路是如何自动对任意深度学习网络模型实施优化,提升单个计算单元运算效率,实现约10倍左右的性能加速。第三种是扩展TensorFlow API,使用户可以在模型脚本中直接控制压缩和量化,另一个思路是将输入数据异步拷贝到CPU中,掩盖数据拷贝的开销,这种做法需要和内核融合结合。

研究员薛卉介绍了其开发的NNI。薛卉原本从事自然语言处理,在加入系统组后,从自身在上层技术领域进行科研工作的切身体会出发,和微软亚洲研究院首席研究员杨懋一起开发了名为Neural Network Intelligence(NNI)的底层框架。NNI项目源起于传统机器学习开发的繁琐流程,特别是深度学习目前还处于黑箱状态,研究人员往往需要花费大量的时间进行模型选择和超参数调试。NNI的诞生不仅可以支持不同的操作系统和编程语言,自动地帮助使用者完成数据分析、模型比对、参数调试和性能分析工作,还能方便使用者将模型运行在不同的分布式系统上。近期,NNI就会以开源工具包的形式对外发布,这将给研究、开发人员更多尝试创新的可能性,加快科研和技术发展的脚步。
做系统最重要的是易用性,微软以上的项目通过系统的优化、创新,能够赋能更多科研人员、开发者和实践者。
雷锋网了解到,目前除了微软,其他巨头公司也在积极推广人工智能系统/平台,英特尔有其“人工智能全栈解决方案”,囊括了芯片、处理器、数据库、开源软件工具等;苹果有机器学习框架Core ML、Create ML、对话式人工智能Siri。未来,人工智能时代的标志性系统究竟是什么样?还需要我们继续探索。





