仅训练了1000个样本,我完成了400万条评论分类
编者按:关于NLP领域的迁移学习我们已经介绍过了,fast.ai也有很多相应的讨论。今天给大家展示一个在亚马逊评论数据集上实现的任务,即将评论分为积极或消极两类。
GitHub地址在这里:github.com/feedly/ml-demos/blob/master/source/TransferLearningNLP.ipynb,感兴趣的同学可以自己动手试试。
相关阅读:《概览迁移学习在NLP领域中的应用》
什么是迁移学习?
得益于迁移学习,计算机视觉领域的发展非常迅速。有着几百万个参数的高度非线性模型通常需要大型数据集的训练,经过几天甚至几周的训练,也只能分辨猫狗。

有了ImageNet挑战赛后,每年各种队伍都会设计出不同的图像分类器。我们发现这类模型的隐藏层可以捕捉图像的通用特征(例如线条、形式、风格等)。于是,这样就不用每次都为新的任务重建模型了。
以VGG-16模型为例:
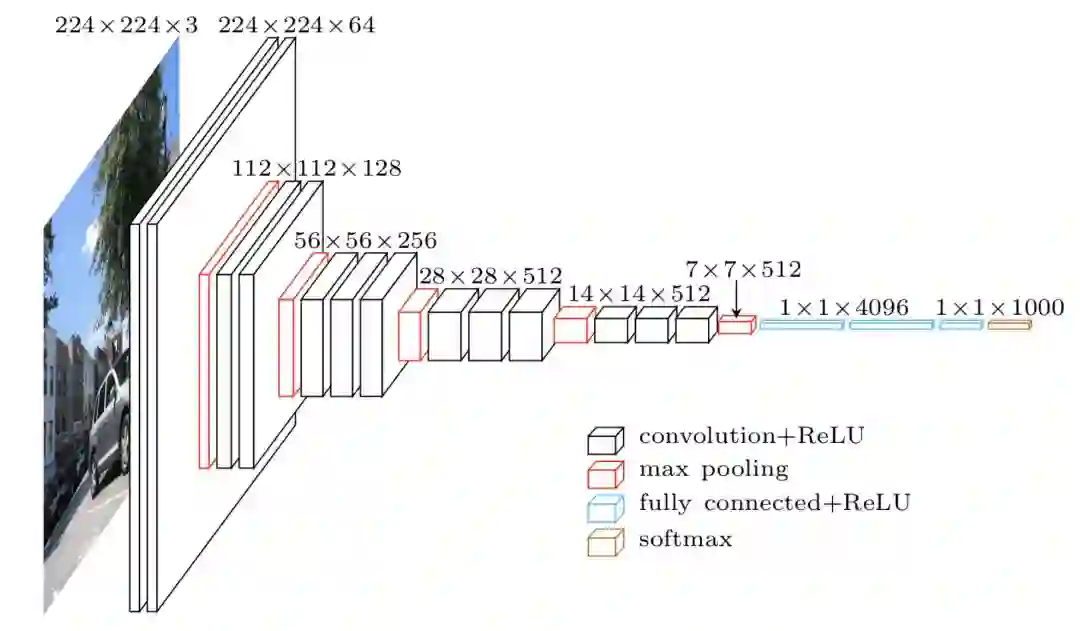
它的结构相对复杂,图层较多,同时参数也很多。论文作者称需要用四个GPU训练三周。
而迁移学习的理念是,由于中间的图层是学习图像一般特征的,所以我们可以将其用作一个大型“特征生成器”!我们可以先下载一个预训练模型(在ImageNet任务上训练了好几周),删去网络的最后一层(全连接层),根据我们的任务进行调整,最后只训练我们的分类器图层。由于使用的数据可能和之前训练的模型所用数据不同,我们也可以花点时间训练所有图层。
由于只在最后一层进行训练,迁移学习会用到更少的标记数据。对数据进行标注非常费时,所以创建不需要大量数据的高质量模型就非常受欢迎了。
NLP中的迁移学习
说实话,迁移学习在自然语言处理中的发展并不像在机器视觉里那样受重视。让机器学习线条、圆圈、方块,然后再用于分析还是比较容易设计的。但是用来处理文本数据似乎不那么容易。
最初用来处理NLP中的迁移学习问题的是词嵌入模型(常见的是word2vec和GloVe),这些词嵌入表示利用词语所在的语境来用向量表示它们,所以相似的词语有相似的词语表示。
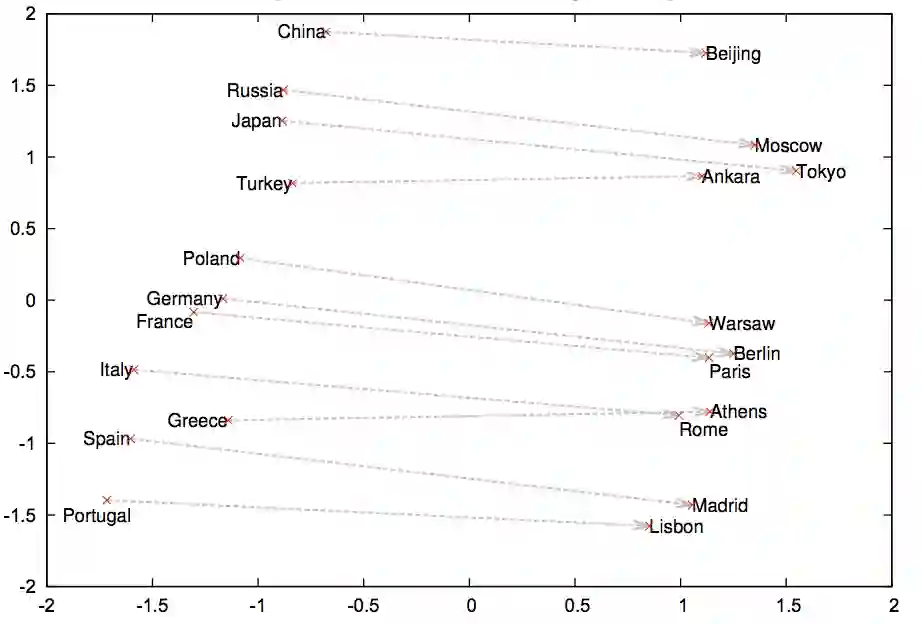
然而,词嵌入只能表示大多数NLP模型的第一个图层,之后我们仍需要从零开始训练所有的RNN/CNN等图层。
对语言模型进行微调
今年年初,Jeremy Howard和Sebastian Ruder提出了ULMFiT模型,这也是对NLP领域迁移学习的深入尝试。具体可参考论智此前报道的:《用迁移学习创造的通用语言模型ULMFiT,达到了文本分类的最佳水平》。
他们所研究的问题基于语言模型。语言模型是能够基于已知单词预测下一个单词的模型(例如手机上的智能拼写)。就像图像分类器一样,如果NLP模型能准确预测下一个单词,那就可以认为该模型学了很多自然语言组合的规则了。这一模型可以作为初始化,能够针对不同任务进行训练。
ULMFiT提出要在大型语料上训练语言模型(例如维基百科),然后创建分类器。由于你的文本数据可能和维基百科的语言风格不同,你就需要对参数进行微调,把这些差异考虑进去。然后,我们会在语言模型的顶层添加一个分类图层,并且只训练这个图层!论文建议逐渐解锁各个图层进行训练。
ULMFiT论文中的收获
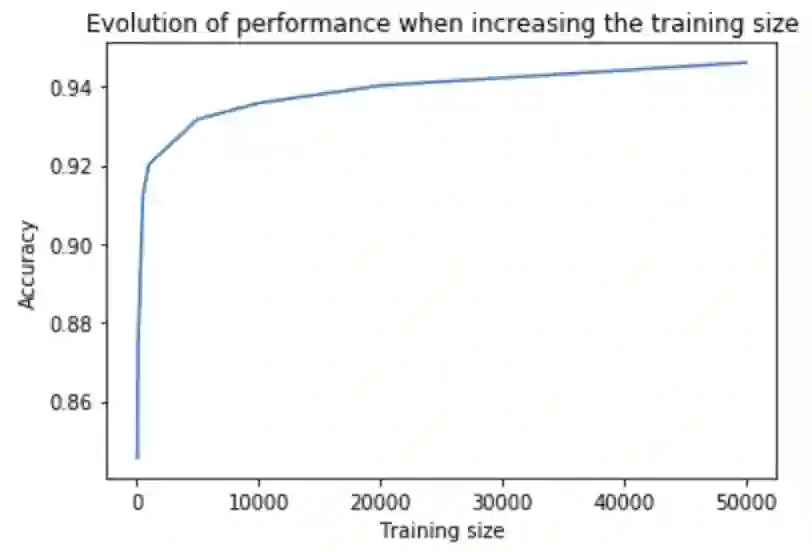
这篇论文最让人惊喜之处就是用非常少的标记数据训练分类器。虽然未经标记过的数据随处可见,但是标记过的数据获取的成本是很高的。下面是对IMDb进行情感分析之后的结果:

只用了100个案例,他们就达到了和用2万个案例训练出的模型同样的错误率水平。除此之外,他们还提供了对模型进行预训练的代码,因为维基百科有多种语言,这使得我们能快速地进行语言转换。除英语之外,其他语种并没有很多经过标记的公开数据集,所以你可以在语言模型上对自己的数据进行微调。
处理亚马逊评论
为了加深对这种方法的理解,我们在另一个公开数据集上试了试。在Kaggle上发现了这个“亚马逊评论情感分析数据集”(地址:www.kaggle.com/bittlingmayer/amazonreviews/home)。它含有400万条商品评论已经相关的情感标签(积极或消极)。我们用fast.ai提出的ULMFiT对亚马逊的评价进行分类。我们发现,仅用1000个案例,模型就达到了在全部数据上训练的FastText模型的表现成果。而用100个案例进行训练,模型也能表现出不错的性能。
如果你想复现这个实验,可以参考notebook:github.com/feedly/ml-demos/blob/master/source/TransferLearningNLP.ipynb,在微调和分类过程中有一个GPU还是很高效的。
NLP中非监督 vs 监督学习
在使用ULMFiT的过程中,我们用到了非监督和监督学习两种方法。训练一个非监督式语言模型很“便宜”,因为你可以从网上找到很多文本数据。但是,监督式模型的成本就很高了,因为需要标记数据。
虽然语言模型可以捕捉到很多有关自然语言组织的信息,但是仍不能确定模型能否捕捉到文本的含义,即它们能否了解说话者想传达的信息。
Emily Bender在推特上曾提出了一个有趣的“泰语实验”:“假设给你所有泰语书籍,没有译文。假如你一点都不懂泰语,你永远不会从中学会什么。”
所以,我们认为语言模型更多的是学习语法规则,而不是含义。而语言模型能做的不仅仅是预测在语法规则上相近的句子。例如“I ate this computer”和“I hate this computer”两句话结构相同,但是一个良好的模型应该会将后者看作是“更正确”的句子。所以我们可以将语言模型看作是学习自然语言句子的架构的工具,从而帮助我们了解句子含义。
想了解更多这方面的话题,可以观看ACL 2018上Yejin Choi的演讲:sites.google.com/site/repl4nlp2018/home?authuser=0
NLP迁移学习的未来
ULMFiT的出现推动了迁移学习在自然语言处理中的发展,同时也出现了其他的微调工具,例如FineTune Transformer LM。我们注意到随着更多更好地语言模型的出现,迁移的效率也在不断提高。
最后再附上ULMFiT的原论文:arxiv.org/pdf/1801.06146.pdf
原文地址:blog.feedly.com/transfer-learning-in-nlp/






