Python 还能实现哪些 AI 游戏?附上代码一起来一把!

来源:AI科技大本营
作者:李秋键
责编:Carol

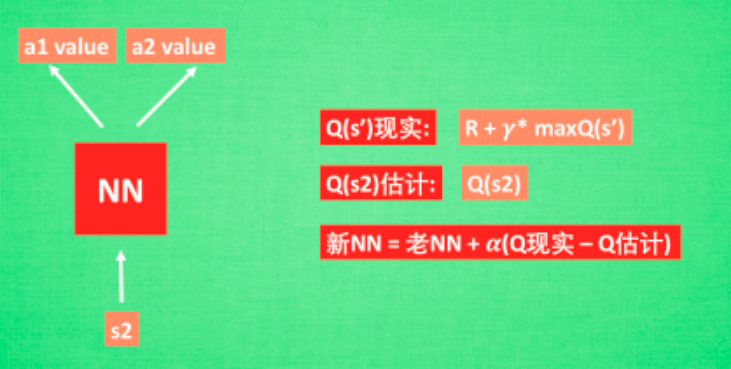
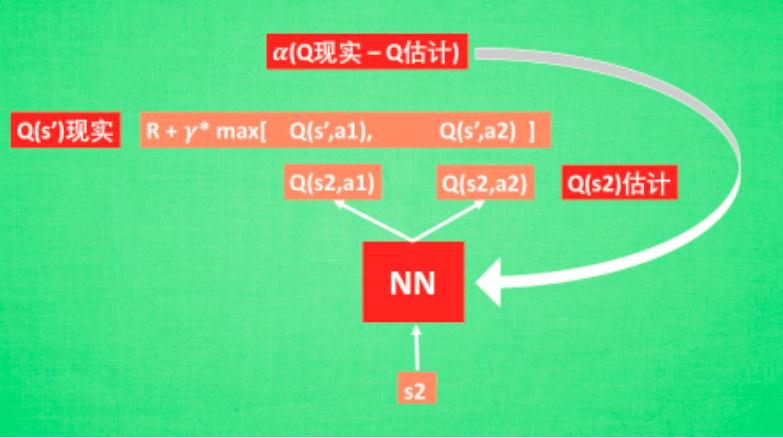
创新点:
优点:
缺点:
1、游戏结构设定:
def __init__(self):
self.__initGame()
# 初始化一些变量
self.loseReward = -
1
self.winReward =
1
self.hitReward =
0
self.paddleSpeed =
15
self.ballSpeed = (
7,
7)
self.paddle_1_score =
0
self.paddle_2_score =
0
self.paddle_1_speed =
0.
self.paddle_2_speed =
0.
self.__reset()
'''
更新一帧
action: [keep, up, down]
'''
# 更新ball的位置
self.ball_pos =
self.ball_pos[
0] +
self.ballSpeed[
0],
self.ball_pos[
1] +
self.ballSpeed[
1]
# 获取当前场景(只取左半边)
image = pygame.surfarray.array3d(pygame.display.get_surface())
# image = image[321:, :]
pygame.display.update()
terminal = False
if max(
self.paddle_1_score,
self.paddle_2_score) >=
20:
self.paddle_1_score =
0
self.paddle_2_score =
0
terminal = True
return image, reward, terminal
def update_frame(self, action):
assert len(action) ==
3
pygame.event.pump()
reward =
0
# 绑定一些对象
self.score1Render =
self.font.render(str(
self.paddle_1_score), True, (
255,
255,
255))
self.score2Render =
self.font.render(str(
self.paddle_2_score), True, (
255,
255,
255))
self.screen.blit(
self.background, (
0,
0))
pygame.draw.rect(
self.screen, (
255,
255,
255), pygame.Rect((
5,
5), (
630,
470)),
2)
pygame.draw.aaline(
self.screen, (
255,
255,
255), (
320,
5), (
320,
475))
self.screen.blit(
self.paddle_1,
self.paddle_1_pos)
self.screen.blit(
self.paddle_2,
self.paddle_2_pos)
self.screen.blit(
self.ball,
self.ball_pos)
self.screen.blit(
self.score1Render, (
240,
210))
self.screen.blit(
self.score2Render, (
370,
210))
'''
游戏初始化
'''
def __initGame(self):
pygame.init()
self.screen = pygame.display.set_mode((
640,
480),
0,
32)
self.background = pygame.Surface((
640,
480)).convert()
self.background.fill((
0,
0,
0))
self.paddle_1 = pygame.Surface((
10,
50)).convert()
self.paddle_1.fill((
0,
255,
255))
self.paddle_2 = pygame.Surface((
10,
50)).convert()
self.paddle_2.fill((
255,
255,
0))
ball_surface = pygame.Surface((
15,
15))
pygame.draw.circle(ball_surface, (
255,
255,
255), (
7,
7), (
7))
self.ball = ball_surface.convert()
self.ball.set_colorkey((
0,
0,
0))
self.font = pygame.font.SysFont(
"calibri",
40)
'''
重置球和球拍的位置
'''
def __reset(self):
self.paddle_1_pos = (
10.,
215.)
self.paddle_2_pos = (
620.,
215.)
self.ball_pos = (
312.5,
232.5)
2、行动决策机制:
# 行动paddle_1(训练对象)
if action[
0] ==
1:
self.paddle_1_speed =
0
elif action[
1] ==
1:
self.paddle_1_speed = -
self.paddleSpeed
elif action[
2] ==
1:
self.paddle_1_speed =
self.paddleSpeed
self.paddle_1_pos =
self.paddle_1_pos[
0], max(min(
self.paddle_1_speed +
self.paddle_1_pos[
1],
420),
10)
# 行动paddle_2(设置一个简单的算法使paddle_2的表现较优, 非训练对象)
if
self.ball_pos[
0] >=
305.:
if not
self.paddle_2_pos[
1] ==
self.ball_pos[
1] +
7.5:
if
self.paddle_2_pos[
1] <
self.ball_pos[
1] +
7.5:
self.paddle_2_speed =
self.paddleSpeed
self.paddle_2_pos =
self.paddle_2_pos[
0], max(min(
self.paddle_2_pos[
1] +
self.paddle_2_speed,
420),
10)
if
self.paddle_2_pos[
1] >
self.ball_pos[
1] -
42.5:
self.paddle_2_speed = -
self.paddleSpeed
self.paddle_2_pos =
self.paddle_2_pos[
0], max(min(
self.paddle_2_pos[
1] +
self.paddle_2_speed,
420),
10)
else:
self.paddle_2_pos =
self.paddle_2_pos[
0], max(min(
self.paddle_2_pos[
1] +
7.5,
420),
10)
# 行动ball
# 球撞拍上
if
self.ball_pos[
0] <=
self.paddle_1_pos[
0] +
10.:
if
self.ball_pos[
1] +
7.5 >=
self.paddle_1_pos[
1]
and
self.ball_pos[
1] <=
self.paddle_1_pos[
1] +
42.5:
self.ball_pos =
20.,
self.ball_pos[
1]
self.ballSpeed = -
self.ballSpeed[
0],
self.ballSpeed[
1]
reward =
self.hitReward
if
self.ball_pos[
0] +
15 >=
self.paddle_2_pos[
0]:
if
self.ball_pos[
1] +
7.5 >=
self.paddle_2_pos[
1]
and
self.ball_pos[
1] <=
self.paddle_2_pos[
1] +
42.5:
self.ball_pos =
605.,
self.ball_pos[
1]
self.ballSpeed = -
self.ballSpeed[
0],
self.ballSpeed[
1]
# 拍未接到球(另外一个拍得分)
if
self.ball_pos[
0] <
5.:
self.paddle_2_score +=
1
reward =
self.loseReward
self.__reset()
elif
self.ball_pos[
0] >
620.:
self.paddle_1_score +=
1
reward =
self.winReward
self.__reset()
# 球撞墙上
if
self.ball_pos[
1] <=
10.:
self.ballSpeed =
self.ballSpeed[
0], -
self.ballSpeed[
1]
self.ball_pos =
self.ball_pos[
0],
10
elif
self.ball_pos[
1] >=
455:
self.ballSpeed =
self.ballSpeed[
0], -
self.ballSpeed[
1]
self.ball_pos =
self.ball_pos[
0],
455
'''
获得初始化weight权重
'''
def init_weight_variable(self, shape):
return tf.Variable(tf.truncated_normal(shape, stddev=
0.01))
'''
获得初始化bias权重
'''
def init_bias_variable(self, shape):
return tf.Variable(tf.constant(
0.01, shape=shape))
'''
卷积层
'''
def conv2D(self, x, W, stride):
return tf.nn.conv2d(x, W, strides=[
1, stride, stride,
1], padding=
"SAME")
'''
池化层
'''
def maxpool(self, x):
return tf.nn.max_pool(x, ksize=[
1,
2,
2,
1], strides=[
1,
2,
2,
1], padding=
'SAME')
'''
计算损失
'''
def compute_loss(self, q_values, action_now, target_q_values):
tmp = tf.reduce_sum(tf.multiply(q_values, action_now), reduction_indices=
1)
loss = tf.reduce_mean(tf.square(target_q_values - tmp))
return loss
'''
下一帧
'''
def next_frame(self, action_now, scene_now, gameState):
x_now, reward, terminal = gameState.update_frame(action_now)
x_now = cv2.cvtColor(cv2.resize(x_now, (
80,
80)), cv2.COLOR_BGR2GRAY)
_, x_now = cv2.threshold(x_now,
127,
255, cv2.THRESH_BINARY)
x_now = np.reshape(x_now, (
80,
80,
1))
scene_next = np.append(x_now, scene_now[:, :,
0:
3], axis=
2)
return scene_next, reward, terminal
'''
计算target_q_values
'''
def compute_target_q_values(self, reward_batch, q_values_batch, minibatch):
target_q_values = []
for i
in range(len(minibatch)):
if minibatch[i][
4]:
target_q_values.append(reward_batch[i])
else:
target_q_values.append(reward_batch[i] + self.gamma * np.max(q_values_batch[i]))
return target_q_values
def __init__(self, options):
self.options = options
self.num_action = options[
'num_action']
self.lr = options[
'lr']
self.modelDir = options[
'modelDir']
self.init_prob = options[
'init_prob']
self.end_prob = options[
'end_prob']
self.OBSERVE = options[
'OBSERVE']
self.EXPLORE = options[
'EXPLORE']
self.action_interval = options[
'action_interval']
self.REPLAY_MEMORY = options[
'REPLAY_MEMORY']
self.gamma = options[
'gamma']
self.batch_size = options[
'batch_size']
self.save_interval = options[
'save_interval']
self.logfile = options[
'logfile']
self.is_train = options[
'is_train']
'''
训练网络
'''
def train(self, session):
x, q_values_ph =
self.create_network()
action_now_ph = tf.placeholder(
'float', [None,
self.num_action])
target_q_values_ph = tf.placeholder(
'float', [None])
# 计算loss
loss =
self.compute_loss(q_values_ph, action_now_ph, target_q_values_ph)
# 优化目标
trainStep = tf.train.AdamOptimizer(
self.lr).minimize(loss)
# 游戏
gameState = PongGame()
# 用于记录数据
dataDeque = deque()
# 当前的动作
action_now = np.zeros(
self.num_action)
action_now[
0] =
1
# 初始化游戏状态
x_now, reward, terminal = gameState.update_frame(action_now)
x_now = cv2.cvtColor(cv2.resize(x_now, (
80,
80)), cv2.COLOR_BGR2GRAY)
_, x_now = cv2.threshold(x_now,
127,
255, cv2.THRESH_BINARY)
scene_now = np.stack((x_now, )*
4, axis=
2)
# 读取和保存checkpoint
saver = tf.train.Saver()
session.run(tf.global_variables_initializer())
checkpoint = tf.train.get_checkpoint_state(
self.modelDir)
if checkpoint
and checkpoint.
model_checkpoint_path:
saver.restore(session, checkpoint.model_checkpoint_path)
print(
'[INFO]: Load %s successfully...' % checkpoint.model_checkpoint_path)
else:
print(
'[INFO]: No weights found, start to train a new model...')
prob =
self.init_prob
num_frame =
0
logF = open(
self.logfile,
'a')
while
True:
q_values = q_values_ph.eval(feed_dict={
x: [scene_now]})
action_idx = get_action_idx(q_values=q_values,
prob=prob,
num_frame=num_frame,
OBSERVE=
self.OBSERVE,
num_action=
self.num_action)
action_now = np.zeros(
self.num_action)
action_now[action_idx] =
1
prob = down_prob(prob=prob,
num_frame=num_frame,
OBSERVE=
self.OBSERVE,
EXPLORE=
self.EXPLORE,
init_prob=
self.init_prob,
end_prob=
self.end_prob)
for
_
in range(
self.action_interval):
scene_next, reward, terminal =
self.next_frame(action_now=action_now,
scene_now=scene_now, gameState=gameState)
scene_now = scene_next
dataDeque.append((scene_now, action_now, reward, scene_next, terminal))
if len(dataDeque) >
self.
REPLAY_MEMORY:
dataDeque.popleft()
loss_now = None
if (num_frame >
self.OBSERVE):
minibatch = random.sample(dataDeque,
self.batch_size)
scene_now_batch = [mb[
0]
for mb
in minibatch]
action_batch = [mb[
1]
for mb
in minibatch]
reward_batch = [mb[
2]
for mb
in minibatch]
scene_next_batch = [mb[
3]
for mb
in minibatch]
q_values_batch = q_values_ph.eval(feed_dict={
x: scene_next_batch})
target_q_values =
self.compute_target_q_values(reward_batch, q_values_batch, minibatch)
trainStep.run(feed_dict={
target_q_values_ph: target_q_values,
action_now_ph: action_batch,
x: scene_now_batch
})
loss_now = session.run(loss, feed_dict={
target_q_values_ph: target_q_values,
action_now_ph: action_batch,
x: scene_now_batch
})
num_frame +=
1
if num_frame %
self.save_interval ==
0:
name =
'DQN_Pong'
saver.save(session, os.path.join(
self.modelDir, name), global_step=num_frame)
log_content =
'<Frame>: %s, <Prob>: %s, <Action>: %s, <Reward>: %s, <Q_max>: %s, <Loss>: %s' % (str(num_frame), str(prob), str(action_idx), str(reward), str(np.max(q_values)), str(loss_now))
logF.write(log_content +
'\n')
print(log_content)
logF.close()
'''
创建网络
'''
def create_network(self):
'''
W_conv1 = self.init_weight_variable([9, 9, 4, 16])
b_conv1 = self.init_bias_variable([16])
W_conv2 = self.init_weight_variable([7, 7, 16, 32])
b_conv2 = self.init_bias_variable([32])
W_conv3 = self.init_weight_variable([5, 5, 32, 32])
b_conv3 = self.init_bias_variable([32])
W_conv4 = self.init_weight_variable([5, 5, 32, 64])
b_conv4 = self.init_bias_variable([64])
W_conv5 = self.init_weight_variable([3, 3, 64, 64])
b_conv5 = self.init_bias_variable([64])
'''
W_conv1 =
self.init_weight_variable([
8,
8,
4,
32])
b_conv1 =
self.init_bias_variable([
32])
W_conv2 =
self.init_weight_variable([
4,
4,
32,
64])
b_conv2 =
self.init_bias_variable([
64])
W_conv3 =
self.init_weight_variable([
3,
3,
64,
64])
b_conv3 =
self.init_bias_variable([
64])
# 5 * 5 * 64 = 1600
W_fc1 =
self.init_weight_variable([
1600,
512])
b_fc1 =
self.init_bias_variable([
512])
W_fc2 =
self.init_weight_variable([
512,
self.num_action])
b_fc2 =
self.init_bias_variable([
self.num_action])
# input placeholder
x = tf.placeholder(
'float', [None,
80,
80,
4])
'''
conv1 = tf.nn.relu(tf.layers.batch_normalization(self.conv2D(x, W_conv1, 4) + b_conv1, training=self.is_train, momentum=0.9))
conv2 = tf.nn.relu(tf.layers.batch_normalization(self.conv2D(conv1, W_conv2, 2) + b_conv2, training=self.is_train, momentum=0.9))
conv3 = tf.nn.relu(tf.layers.batch_normalization(self.conv2D(conv2, W_conv3, 2) + b_conv3, training=self.is_train, momentum=0.9))
conv4 = tf.nn.relu(tf.layers.batch_normalization(self.conv2D(conv3, W_conv4, 1) + b_conv4, training=self.is_train, momentum=0.9))
conv5 = tf.nn.relu(tf.layers.batch_normalization(self.conv2D(conv4, W_conv5, 1) + b_conv5, training=self.is_train, momentum=0.9))
flatten = tf.reshape(conv5, [-1, 1600])
'''
conv1 = tf.nn.relu(
self.conv2D(x, W_conv1,
4) + b_conv1)
pool1 =
self.maxpool(conv1)
conv2 = tf.nn.relu(
self.conv2D(pool1, W_conv2,
2) + b_conv2)
conv3 = tf.nn.relu(
self.conv2D(conv2, W_conv3,
1) + b_conv3)
flatten = tf.reshape(conv3, [-
1,
1600])
fc1 = tf.nn.relu(tf.layers.batch_normalization(tf.matmul(flatten, W_fc1) + b_fc1, training=
self.is_train, momentum=
0.
9))
fc2 = tf.matmul(fc1, W_fc2) + b_fc2
return x, fc2

——END——



登录查看更多
相关内容
Arxiv
8+阅读 · 2018年3月5日



相关VIP内容
相关资讯
相关论文
Arxiv
8+阅读 · 2018年3月5日