![]()
本文约2774字,建议阅读13分钟
本文介绍
了来自清华大学和南开大学的研究者提出了一种新型大核注意力模块,并在 LKA 的基础上构建了一种性能超越 SOTA 视觉 transformer 的新型神经网络 VAN。
作为基础特征提取器,视觉骨干(vision backbone)是计算机视觉领域的基础研究课题。得益于卓越的特征提取性能,CNN 成为过去十年中不可或缺的研究课题。在 AlexNet 重新开启深度学习十年之后,通过使用更深的网络、更高效的架构、更强的多尺度能力,社区已取得多项突破以获得更强大的视觉骨干和注意力机制。由于平移不变性和共享滑动窗口策略,CNN 对于具有任意大小输入的各种视觉任务是有效的。更先进的视觉骨干网络通常会在各种任务中带来显著性能提升,包括图像分类、对象检测、语义分割和姿势估计。
同时,选择性注意力是处理视觉中复杂搜索组合的重要机制。注意力机制可以看作是基于输入特征的自适应选择过程。自从提出完全注意力网络以来,自注意力模型(即 Transformer)迅速成为了 NLP 领域的主导架构。近年来,Dosovitskiy 等人提出 ViT,它将 transformer 骨干引入计算机视觉,并在图像分类任务上优于 CNN。得益于强大的建模能力,基于 transformer 的视觉骨干迅速占领了各种任务的排行榜,包括对象检测和语义分割等。
尽管自注意力机制最初是为 NLP 任务而设计的,但近来已经席卷了计算机视觉领域。然而,图像的 2D 特性为在计算机视觉中应用自注意力带来了三个挑战:
将图像视为一维序列会忽略它们的二维结构;
二次复杂度对于高分辨率图像来说太昂贵了;
只捕捉空间适应性而忽略通道适应性。
近日,来自清华大学胡事民团队和南开大学程明明团队提出了一种新型大核注意力(large kernel attention,LKA)模块,
在避免上述问题的同时实现了自注意力中的自适应和长距离相关性
。该研究还进一步提出了一种基于 LKA 的新型神经网络,命名为视觉注意力网络(VAN)。在图像分类、目标检测、语义分割、实例分割等广泛的实验中,VAN 的性能优于 SOTA 视觉 transformer 和卷积神经网络。
![]()
![]()
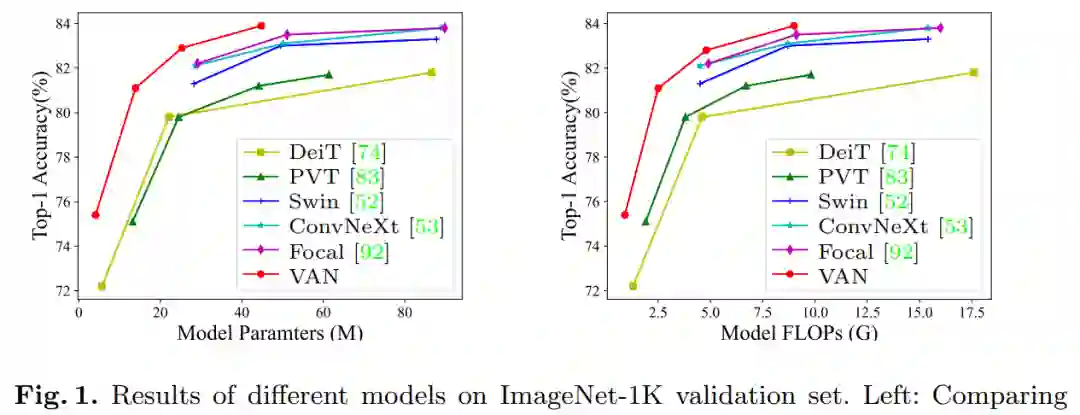
图 1:VAN 与其他模型在 ImageNet-1K 验证集上的 Top-1 准确率结果比较
论文一作为清华大学计算机系博士生国孟昊,主要研究方向为计算机视觉、计算机图形学、深度学习。他也是计图的开发者之一,曾在国际会议 / 期刊 ICLR/IPMI/CVMJ 上发表论文。
胡事民
,清华大学计算机科学与技术系教授,主要从事计算机图形学、智能信息处理和系统软件等方面的研究。研制并开源了第一个我国高校自主的深度学习框架——计图(Jittor),计图是一个完全动态编译(Just-in-time),基于元算子融合和统一计算图的深度学习框架。计图支持 30 多种的骨干网络,并且开源了多个模型库:对抗生成网络、图像语义分割、检测与实例分割、点云分类、可微渲染等。
程明明
,南开大学教授,计算机系主任,他的主要研究方向是计算机视觉和计算机图形学,他发表的论文谷歌引用 2 万余次,单篇最高引用 4000 余次。
注意力机制可以看作是一个自适应选择的过程,它可以根据输入特征选择鉴别特征并自动忽略噪声响应。注意力机制的关键步骤是生成注意力图,指出不同点的重要性。因此需要了解各点之间的关系。
有两种众所周知的方法可以在不同点之间建立关系。第一种是采用自注意力机制来捕获长距离依赖。第二种是使用大核卷积来建立相关性并产生注意力图,这种方式还是有明显的弊端的,大核卷积带来了大量的计算开销和参数。
为了克服上述缺点并利用自注意力和大核卷积的优点,该研究提出分解大核卷积操作来捕获长距离关系。如下图 2 所示,大核卷积可以分为三个部分:空间局部卷积(depth-wise 卷积)、空间长距离卷积(depth-wise 空洞卷积)和通道卷积(1×1 卷积)。
![]()
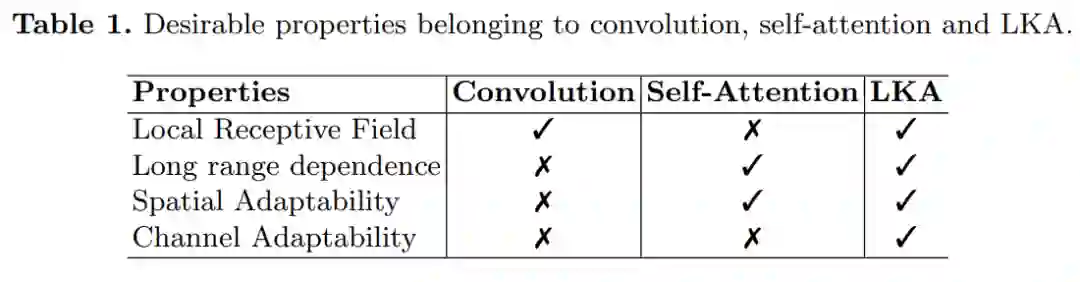
下表 1 给出了 LKA 结合卷积和自注意力的优点。
![]()
VAN 具有简单的层次结构,包括四个阶段,并逐步降低输出空间分辨率,即 H/4 × W/4 、H/8 × W/8 、H/16 × W/16 和 H /32 × W/32 。其中,H 和 W 代表输入图像的高度和宽度。随着分辨率的降低,输出通道的数量也在增加。输出通道 C_i 的变化如下表 2 所示。
![]()
如下图 3 (d) 所示,该研究首先对输入进行下采样,并使用步幅数来控制下采样率。
![]()
该研究通过定量和定性实验来证明 VAN 的有效性。其中,在 ImageNet-1K 图像分类数据集、COCO 目标检测数据集和 ADE20K 语义分割数据集上进行了定量实验,并在 ImageNet 验证集上使用 Grad-CAM 来可视化类激活映射(CAM)。
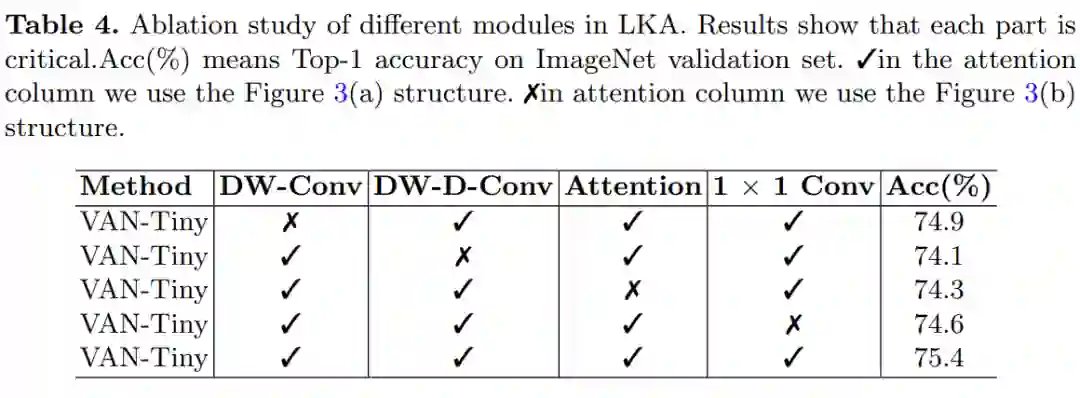
该研究首先用消融实验证明 LKA 的每个组成部分都是至关重要的。为了快速获得实验结果,该研究选择 VAN-Tiny 作为基线模型,实验结果如下表 4 所示。
![]()
通过以上分析,研究者发现 LKA 可以利用局部信息,捕捉长距离依赖,在通道和空间维度上都具有适应性。此外,实验结果证明 LKA 的所有组成部分都有助于完成识别任务。虽然标准卷积可以充分利用局部语境信息,但它忽略了长距离依赖和适应性。而自注意力虽然可以捕获长距离依赖,且在空间维度上具有适应性,但它忽略了局部信息和在通道维度上的适应性。
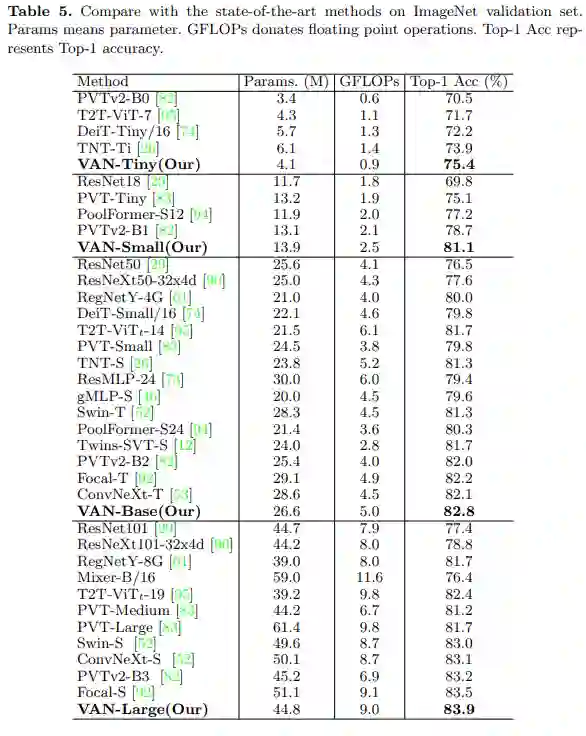
研究者还将 VAN 与现有方法进行了比较,包括 MLP、CNN 和 ViT,结果如下表 5 所示。在相似的参数和计算成本下,VAN 优于常见的 CNN(ResNet、ResNeXt、ConvNeXt 等)、ViT(DeiT、PVT 和 Swin-Transformer 等)和 MLP(MLP -Mixer、ResMLP、gMLP 等)。
![]()
可视化类激活映射(CAM)是一种可视化鉴别区域(注意力图)的流行工具。该研究采用 Grad-CAM 来可视化 ImageNet 验证集上由 VAN-Base 模型生成的注意力。下图 4 的结果表明,VAN-Base 可以清晰地聚焦在目标对象上,可视化直观地证明了 VAN 的有效性。
![]()
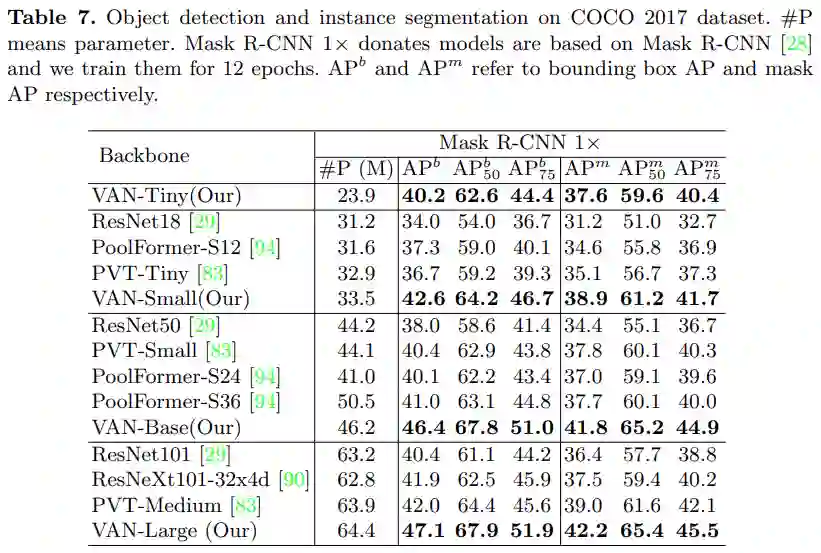
如下表 6 和表 7 所示,在目标检测和实例分割任务上,该研究发现在 RetinaNet 1x 和 Mask R-CNN 1x 设置下,VAN 以较大的优势超越了基于 CNN 的方法 ResNet 和基于 transformer 的方法 PVT。
![]()
![]()
此外,如下表 8 所示,相比于 SOTA 方法 Swin Transformer 和 ConvNeXt,
VAN 实现了更优的性能
。
![]()
下表9给出了语义分割任务的结果,基于 VAN 的方法优于基于 CNN 的方法(ResNet、ResNeXt),优于基于transformer的方法(PVT、PoolFormer、PVTv2)。
![]()